作者:高煥堂
本文摘自 高煥堂 的下列書籍,以及北京【電子世界雜誌】連載專欄

在上一篇文章中,您已經熟悉了GAN模型的兩個主要角色是:判別器(Discriminator)和生成器(Generator)。兩個角色互相較量智慧,教學相長、共同成長。
為了讓您更容易理解上述的共同成長過程,於此特別拿「射飛鏢」的範例來說明之。閱讀完本文,您將很熟悉如何訓練GAN模型,並且進而能修改既有的其程式碼,來創作您自己的獨特GAN了。
以GAN學習「射飛鏢」為例
於此,使用格格和丫環來比喻。有一天,格格來到了「射飛鏢」教室,由丫環陪伴格格練習「射飛鏢」。

此時,兩人都還沒有學習過射飛鏢的技能。於是,就請一位教練(即專家先射了3支飛鏢,都非常接近靶心。以紅色點表示之,如下圖:
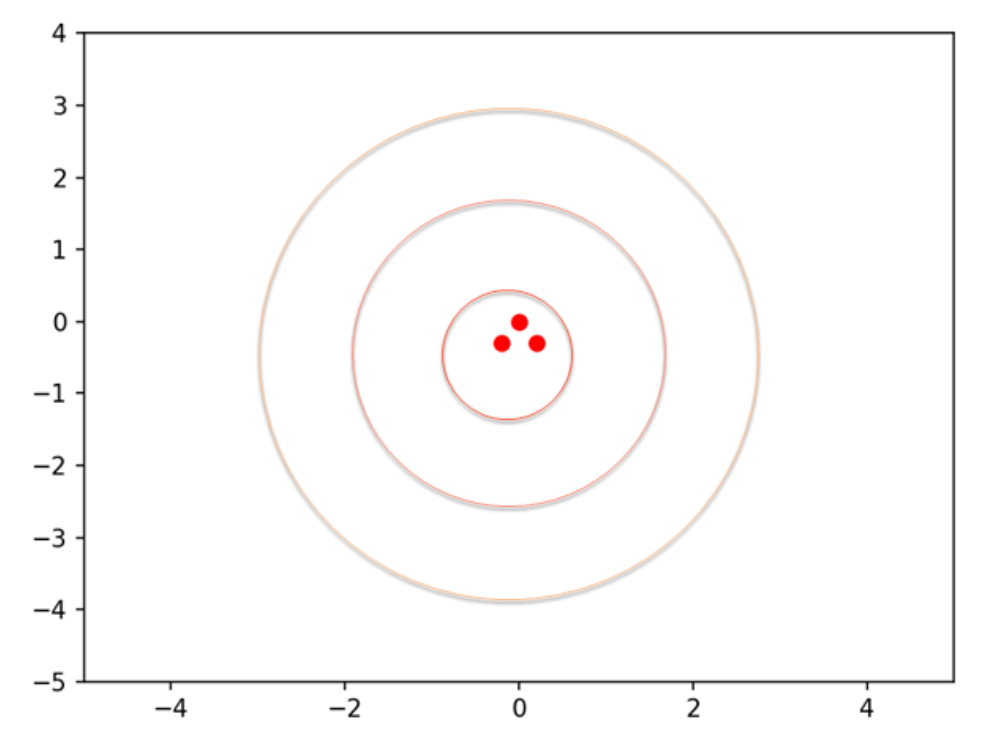
然後,這位教練就離開教室,回家去了。請您想一想,此時這位格格會如何學習射飛鏢呢?由於這位教練已經離去了,所以他不能親自指教格格射飛鏢。
沒關係,如果這是 AI 丫環和 AI 格格,就可以組合成為一個 GAN 模型了。AI 丫環扮演判別器(Discriminator)角色,而 AI 格格則扮演生成器(Generator)角色。
上圖就是格格學習的標的(Target),通稱為真品(Real data)。然後,就由格格來練習射飛鏢了。格格所射的飛鏢,則稱為新品(New data)或仿品(或假品)。以藍色點表示之,如下圖:
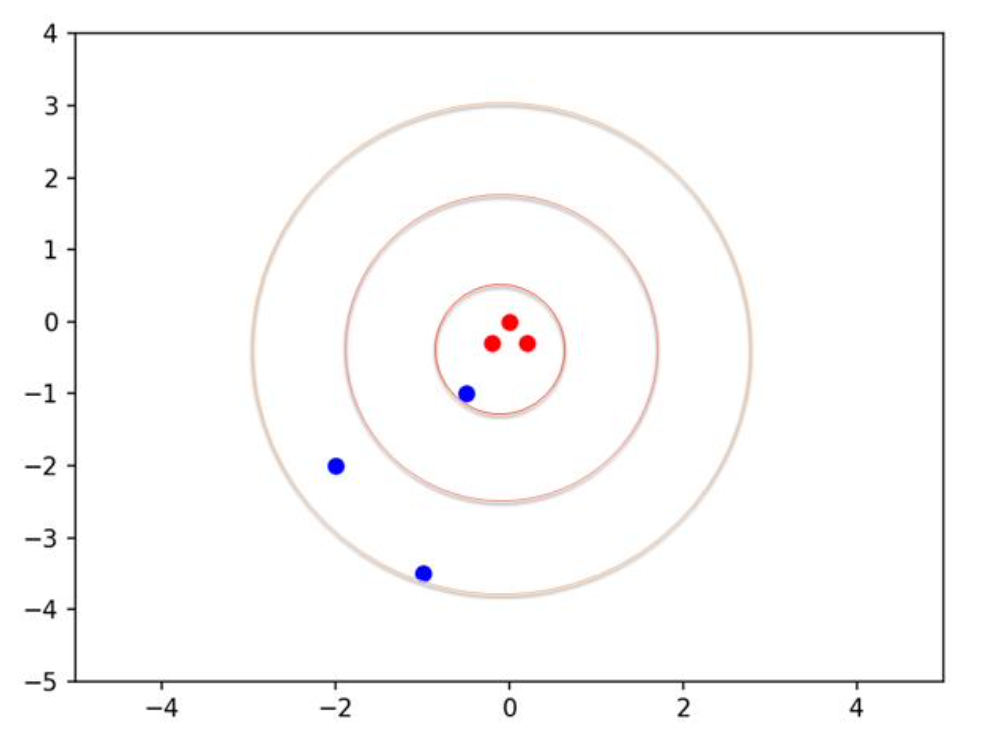
這裡的紅色點是教練投射的3支飛鏢命中點(即人類教練的作品)。而藍色點是 AI 格格投射的3支飛鏢命中點。接下來,請您想一想,如何設計GAN模型來實踐AI格格與AI丫環的教學相長呢?由於教練已經離去了,所以:
- 他不能親自教導格格射飛鏢。
- 我們也無法藉由設定T(目標值)的方式,把他的專家(射飛鏢)智慧,納入到AI丫環的模型裡。
沒問題的,雖然教練已經離去了,但是他已經留下他的作品(如上圖),在這作品裡,其蘊含了專家的經驗直覺(即專家智慧)。AI 丫環可以協助 AI 格格從教練的作品中,學習到這位教練的專家智慧。
以Pytorch實現「射飛鏢」的GAN模型
剛才已經說明了GAN的學習流程了。現在就以Pytorch實現之。茲撰寫程式碼:
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
def sigmoid(y):
return 1/(1+np.exp(-y))
NoiseSize = 16
def get_noise():
noise = torch.rand(NoiseSize) * 15.0
return noise
# 準備真品(教練投鏢)
real_data = np.array([[0,0], [-0.2, -0.3], [0.2, -0.3]]).flatten()
#-------------------------------------------
real_X = torch.tensor(real_data).float()
true_label = torch.ones(1)
new_label = torch.zeros(1)
# 定義D(丫環)模型
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.layer1 = nn.Linear(6, 32)
self.layer2 = nn.Linear(32, 1)
def forward(self, X):
H = torch.relu(self.layer1(X))
Y = self.layer2(H)
return torch.sigmoid(Y)
#-------------------------------
# 定義G(格格)模型
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.layer1 = nn.Linear(NoiseSize, 32)
self.layer2 = nn.Linear(32, 6)
def forward(self, N):
Y = torch.relu(self.layer1(N))
return self.layer2(Y)
D = Discriminator()
G = Generator()
# 損失函數
criterion = nn.BCELoss()
optimizer_d = torch.optim.Adam(D.parameters(), lr=0.0002)
optimizer_g = torch.optim.Adam(G.parameters(), lr=0.0002)
#-------------------------------------
def train_D(X, T):
Z = D(X)
d_loss = criterion(Z, T)
optimizer_d.zero_grad()
d_loss.backward(retain_graph=True)
optimizer_d.step()
return d_loss
#----------------------------------------
def train_G(N, T):
Y = G(N)
new_X = Y
Z = D(new_X)
g_loss = criterion(Z, T)
optimizer_g.zero_grad()
g_loss.backward()
optimizer_g.step()
return g_loss
#-------------------------------------------------
def train(epochs, steps):
for ep in range(epochs):
d_loss_real = train_D(real_X, true_label)
N = get_noise()
new_X = G(N)
d_loss_new = train_D(new_X, new_label)
d_loss = (d_loss_real + d_loss_new) / 2
N = get_noise()
g_loss = train_G(N, true_label)
if(ep % steps == 0):
d_loss_np = d_loss.detach().numpy()
g_loss_np = g_loss.detach().numpy()
print("ep=", ep, " d_loss=", np.round(d_loss_np, 2),
" g_loss=", np.round(g_loss_np, 2))
#-----------------------------------------------------------------------------
train(5, 1)
#-------------------------------------------------
ax = np.reshape(real_data, (3, 2))
N = get_noise()
# 把隨機構想(噪音)給格格,生成新品(假品)
new_X = G(N)
fx = new_X.detach().numpy()
fx = np.reshape(fx, (3, 2))
plt.xlim(-5, 5)
plt.ylim(-5, 4)
plt.scatter(ax[:,0], ax[:,1], c='red')
plt.scatter(fx[:,0], fx[:,1], c='blue')
plt.show()
#END
其中的指令:
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.layer1 = nn.Linear(NoiseSize, 32)
self.layer2 = nn.Linear(32, 6)
def forward(self, N):
Y = torch.relu(self.layer1(N))
return self.layer2(Y)
這定義一個生成器(Generator),它繼承了Pytorch的nn.Module模組。其中的forward()函數進行:N *W+B = Y的計算。也就是進行生成器的「正向推演」流程。
接著,train_D()函數負責訓練判別器;而train_G()函數負責訓練生成器。最後,指令:
train(5, 1)
就對此GAN模型訓練5回合。執行時,輸出結果:

可以看出來,格格的判斷誤差(d_loss)和弟弟的預期誤差(g_loss),會逐漸下降。經過5回合訓練之後,繪出圖像如下:
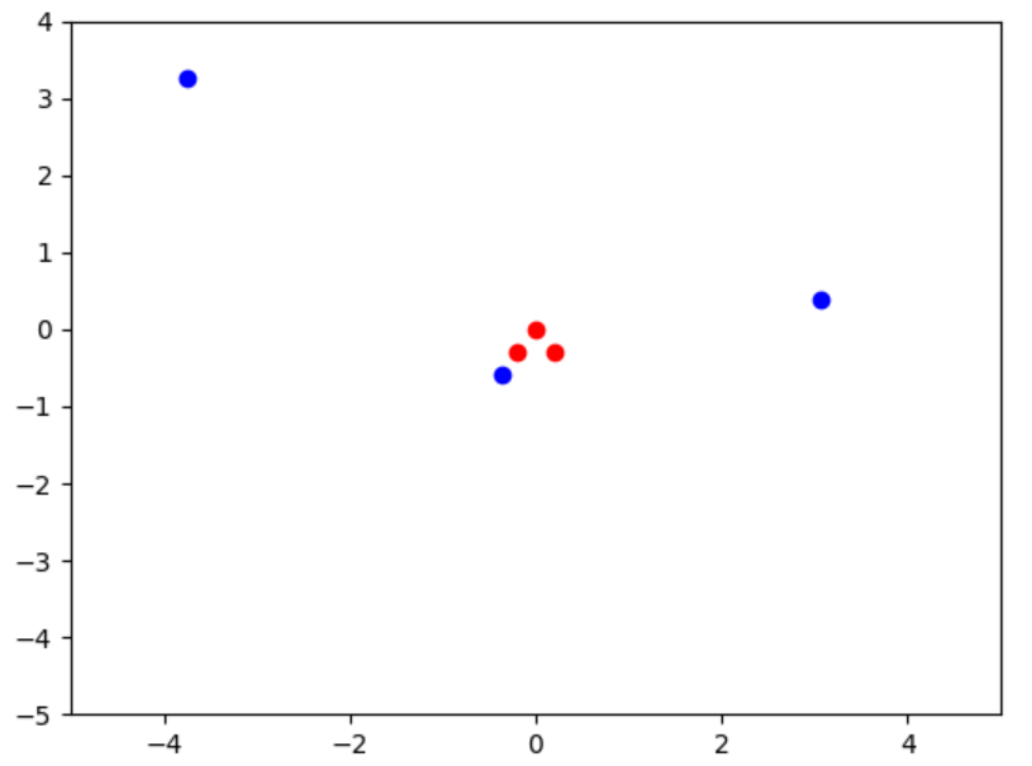
可以看出來,AI格格有一些進步了,所射的這3支新飛鏢,更接近教練的「真品」了。接著,準備對此GAN模型訓練50回合,也就是AI丫環和AI格格繼續一起學習50回合。於是把上述程式碼裡的指令,更改為:
train(50, 10)
重新執行這程式,對此GAN模型展開50回合訓練。執行時,經過50回合學習之後,繪出圖像如下:
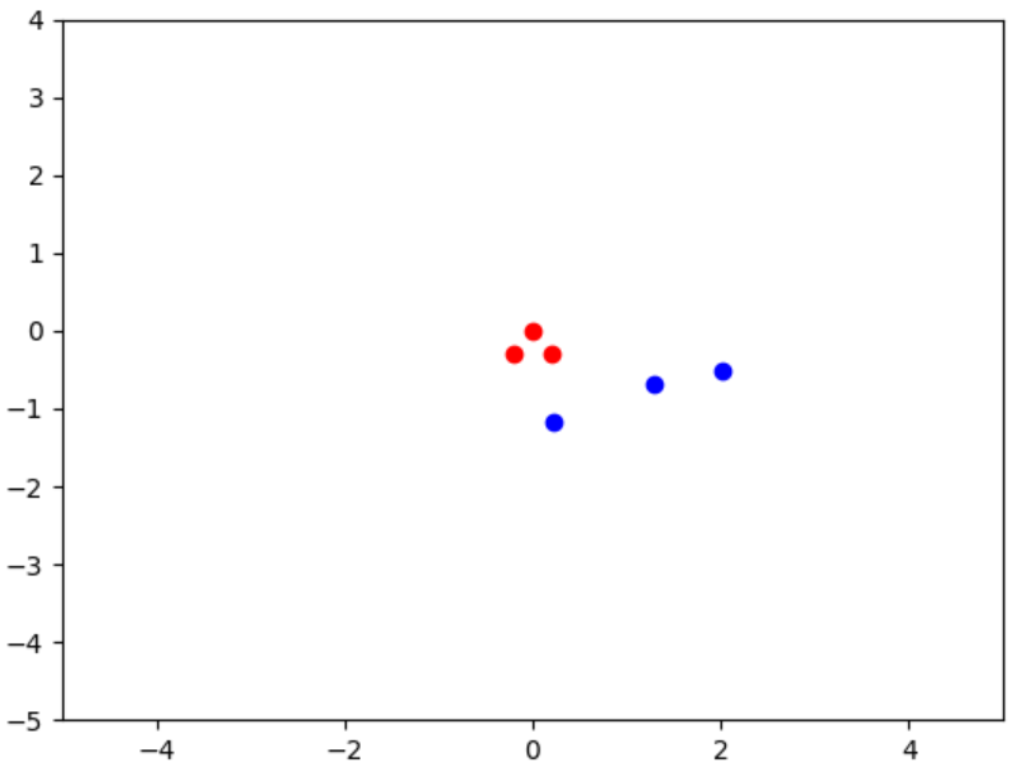
可以看出來,AI格格的智慧(技術)表現已經成長很多了。如果把上述指令,更改為:
train(1000, 200)
準備對此GAN模型訓練1000回合。執行時,經過1000回合訓練之後,繪出圖像如下:
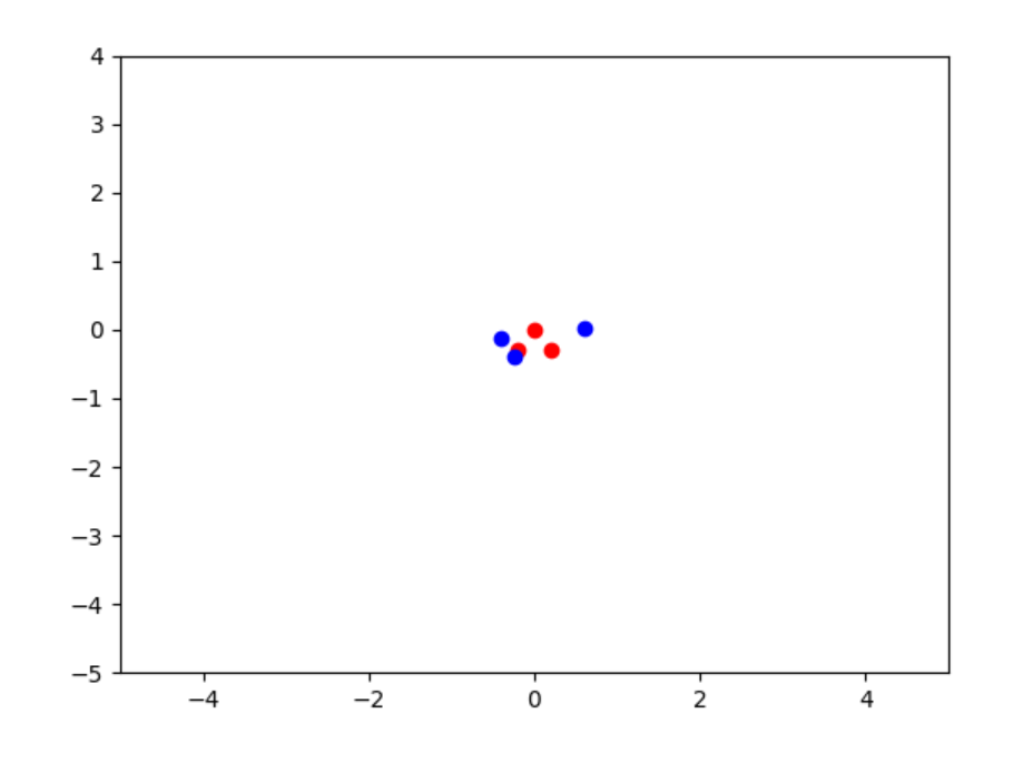
可以看出來,AI格格的「射飛鏢」智慧表現已經非常接近於教練了。換句話說,AI格格從教練的傑作(即作品)中,學習到了教練的專業直覺了。
GAN從人類畫作中學習繪畫
在上一小節裡,您已經從「射飛鏢」範例中,深入理解GAN的訓練流程了。也看到了AIㄚ環陪伴AI格格,從人類專家(如教練)的作品中,學習到「射飛鏢」專業技術。經過1000回合學習之後,AI格格的射飛鏢的表現,已經非常接近人類專家了。
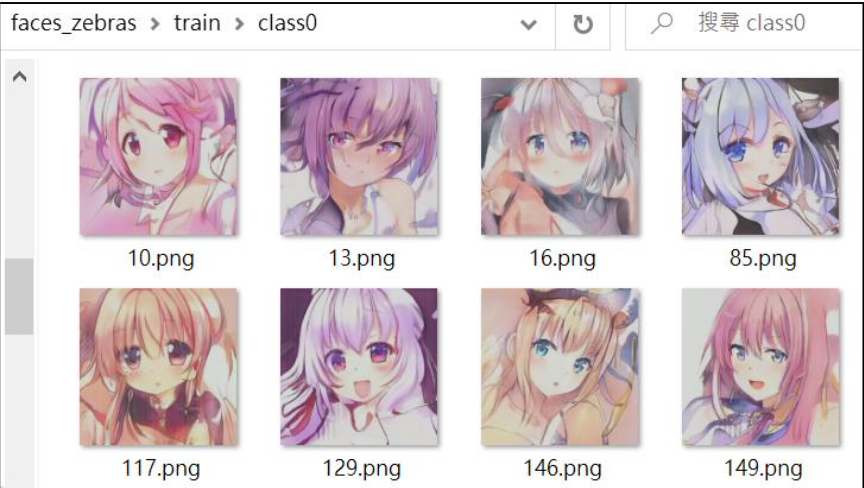
在本節裡,就進一步讓GAN模型從人類畫家的作品(畫作)中,學習專家(即畫家)的直覺,並表現於AI的圖像模仿和創作上。於此將採用著名的GAN Anime Faces圖像集,拿它來作為真品集,來讓GAN模型來學習。於是,從Anime Faces圖像集裡取出30張人臉圖像集。如下圖:
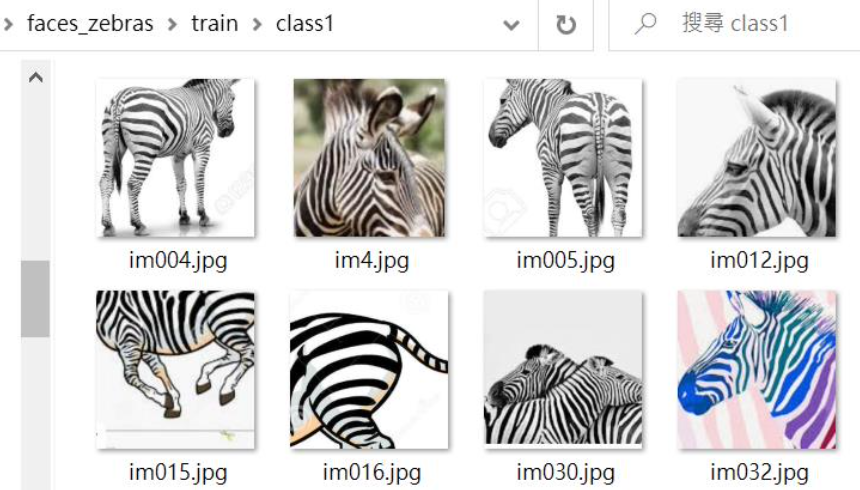
同時也從Google圖像網頁上收集30張斑馬圖像。如下圖:
在此範例裡,就拿這兩份圖像集(即人類畫家的作品)來讓 GAN 模型學習。茲撰寫程式碼:
import numpy as np
import torch
import torch.nn as nn
from torchvision import transforms
import torchvision.utils as vutils
import matplotlib.pyplot as plt
import torch.optim as optim
from PIL import Image
import os
import glob
torch.manual_seed(1)
noise_size = 100
# 生成噪音
def get_noise():
return torch.randn(1, noise_size)
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5],
[0.5,0.5,0.5])])
# 實際讀取*.png圖片
face_images = []
for imageName in glob.glob(
'c:/oopc/animal_zebras_data/train/class0/*.png'):
image = Image.open(imageName).convert('RGB')
image = transform(image)
face_images.append(image)
# 實際讀取*.jpg圖片
zebra_images = []
for imageName in glob.glob(
'c:/oopc/animal_zebras_data/train/class1/*.jpg'):
image = Image.open(imageName).convert('RGB')
image = transform(image)
zebra_images.append(image)
cond_0 = torch.zeros(1, 1).long()
cond_1 = torch.ones(1, 1).long()
true_label = torch.ones(1, 1)
new_label = torch.zeros(1, 1)
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
torch.nn.init.normal_(m.weight, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
torch.nn.init.normal_(m.weight, 1.0, 0.02)
torch.nn.init.zeros_(m.bias)
#------------------------------------------------------
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.cond = nn.Sequential(
nn.Embedding(2, 100),
nn.Linear(100, 3*128*128))
self.model = nn.Sequential(
nn.Conv2d(6, 64, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, 128, 4, 3, 2, bias=False),
nn.BatchNorm2d(128, momentum=0.1, eps=0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(128, 256, 4, 3,2, bias=False),
nn.BatchNorm2d(256, momentum=0.1, eps=0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(256, 512, 4, 3, 2, bias=False),
nn.BatchNorm2d(512, momentum=0.1, eps=0.8),
nn.LeakyReLU(0.2, inplace=True),
nn.Flatten(),
nn.Dropout(0.4),
nn.Linear(4608, 1),
nn.Sigmoid()
)
def forward(self, x):
image, cond = x
c = self.cond(cond)
c = c.view(-1, 3, 128, 128)
concat = torch.cat((image, c), dim=1)
z = self.model(concat)
return z
#------------------------------------------------------
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.cond = nn.Sequential(
nn.Embedding(2, 8),
nn.Linear(8, 16))
self.noise = nn.Sequential(nn.Linear(noise_size, 4*4*512),
nn.LeakyReLU(0.2, inplace=True))
self.model = nn.Sequential(
nn.ConvTranspose2d(513, 512, 4, 2, 1, bias=False),
nn.BatchNorm2d(512, momentum=0.1, eps=0.8),
nn.ReLU(True),
nn.ConvTranspose2d(512, 256, 4, 2, 1,bias=False),
nn.BatchNorm2d(256, momentum=0.1, eps=0.8),
nn.ReLU(True),
nn.ConvTranspose2d(256, 128, 4, 2, 1,bias=False),
nn.BatchNorm2d(128, momentum=0.1, eps=0.8),
nn.ReLU(True),
nn.ConvTranspose2d(128, 64, 4, 2, 1,bias=False),
nn.BatchNorm2d(64, momentum=0.1, eps=0.8),
nn.ReLU(True),
nn.ConvTranspose2d(64, 3, 4, 2, 1, bias=False),
nn.Tanh())
def forward(self, x):
noise, cond = x
n = self.noise(noise)
n = n.view(-1, 512,4,4)
c = self.cond(cond)
c = c.view(-1, 1, 4, 4)
concat = torch.cat((n, c), dim=1)
image = self.model(concat)
return image
D = Discriminator()
G = Generator()
D.apply(weights_init)
G.apply(weights_init)
criterion = nn.BCELoss()
optimizer_g = optim.Adam(G.parameters(), lr=0.0005, betas=(0.5, 0.999))
optimizer_d = optim.Adam(D.parameters(), lr=0.0005, betas=(0.5, 0.999))
#------------------------------------
def train_D(XC, T):
Z = D(XC)
d_loss = criterion(Z, T)
optimizer_d.zero_grad()
d_loss.backward(retain_graph=True)
optimizer_d.step()
return d_loss
#---------------------------
def train_G(NC, T):
N, C = NC
Y = G(NC)
Z = D((Y, C))
g_loss = criterion(Z, T)
optimizer_g.zero_grad()
g_loss.backward()
optimizer_g.step()
return g_loss
#----------------------------
def train_GAN(X, C):
#--- 訓練D ---
train_D((X, C), true_label)
N = get_noise()
new_X = G((N, C))
train_D((new_X, C), new_label)
#--- 訓練G ---
N = get_noise()
train_G((N, C), true_label)
#-------------------------------------------
epochs = 300
for ep in range(epochs):
print(ep)
num = len(face_images)
for i in range(num):
face_image = face_images[i].unsqueeze(0)
train_GAN(face_image, cond_0)
zebra_image = zebra_images[i].unsqueeze(0)
train_GAN(zebra_image, cond_1)
#----------------------------------------------
tc_0 = torch.zeros(3, 1).long()
tc_1 = torch.ones(3, 1).long()
with torch.no_grad():
N = torch.randn(3, noise_size)
new_image0 = G((N, tc_0)).detach()
N = torch.randn(3, noise_size)
new_image1 = G((N, tc_1)).detach()
concat = torch.cat((new_image0, new_image1), dim=0)
plt.figure(figsize=(7,7))
plt.axis("off")
pictures = vutils.make_grid(concat, padding=2, normalize=True)
plt.imshow(np.transpose(pictures,(1,2,0)))
plt.show()
#-------------------
#END
這範例讓GAN模型學習300回合。學習完成了,接著,執行到指令:
tc_0 = torch.zeros(3, 1).long()
tc_1 = torch.ones(3, 1).long()
這相當於:
tc_0 = [[0], [0], [0]]
tc_1 = [[1], [1], [1]]
繼續執行到指令:
N = torch.randn(3, noise_size)
new_image0 = G((N, tc_0)).detach()
生成器就繪出3張人臉圖像。最後,執行到指令:
N = torch.randn(3, noise_size)
new_image1 = G((N, tc_1)).detach()
生成器就繪出3張斑馬圖像。如下圖所示:

可以看到了,GAN模型從人類畫家的作品中,學習其專業直覺,因而也會進行繪畫創作了。

近5年來,從事於AI普及化教育工作,目前擔任銘傳大學AI課程、長庚智慧醫療研究所AI課程授課老師。也擔任永春國小、東園國小、立志中學、君毅中學、永春高中等學校的AI師資培育工作。
- LoRA微調三步驟:以大語言模型MT5為例 - 2024/05/02
- 為什麼Gemma採取Decoder-Only Transformer架構呢? - 2024/04/08
- 如何從0訓練企業自用Gemma模型 - 2024/04/03
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


