作者:Felix Lin
Google於2017年製作了Teachable Machine網頁版本的AI軟體工具,甫一推出就受到相當好的好評與回響,原因在於這個網站幾乎可以不需要任何說明與敘述,就可以自行摸索搞懂原來用AI實踐電腦視覺是這麼一回事!
之後更於2019年推出Teachable Machine V2,除了將原有的Image Classification(影像分類)由固定三個分類擴充為自定義分類數量,並且增加了Audio(聲音)與Pose(人體姿勢)兩個類別的分類器,此外更支援專案的存檔與轉匯出功能,不但能保留資料於日後繼續編輯,同時還能匯出Keras、TensorFlow、tf.js等不同格式的模型檔案,大幅提高了後續轉應用的可玩性!
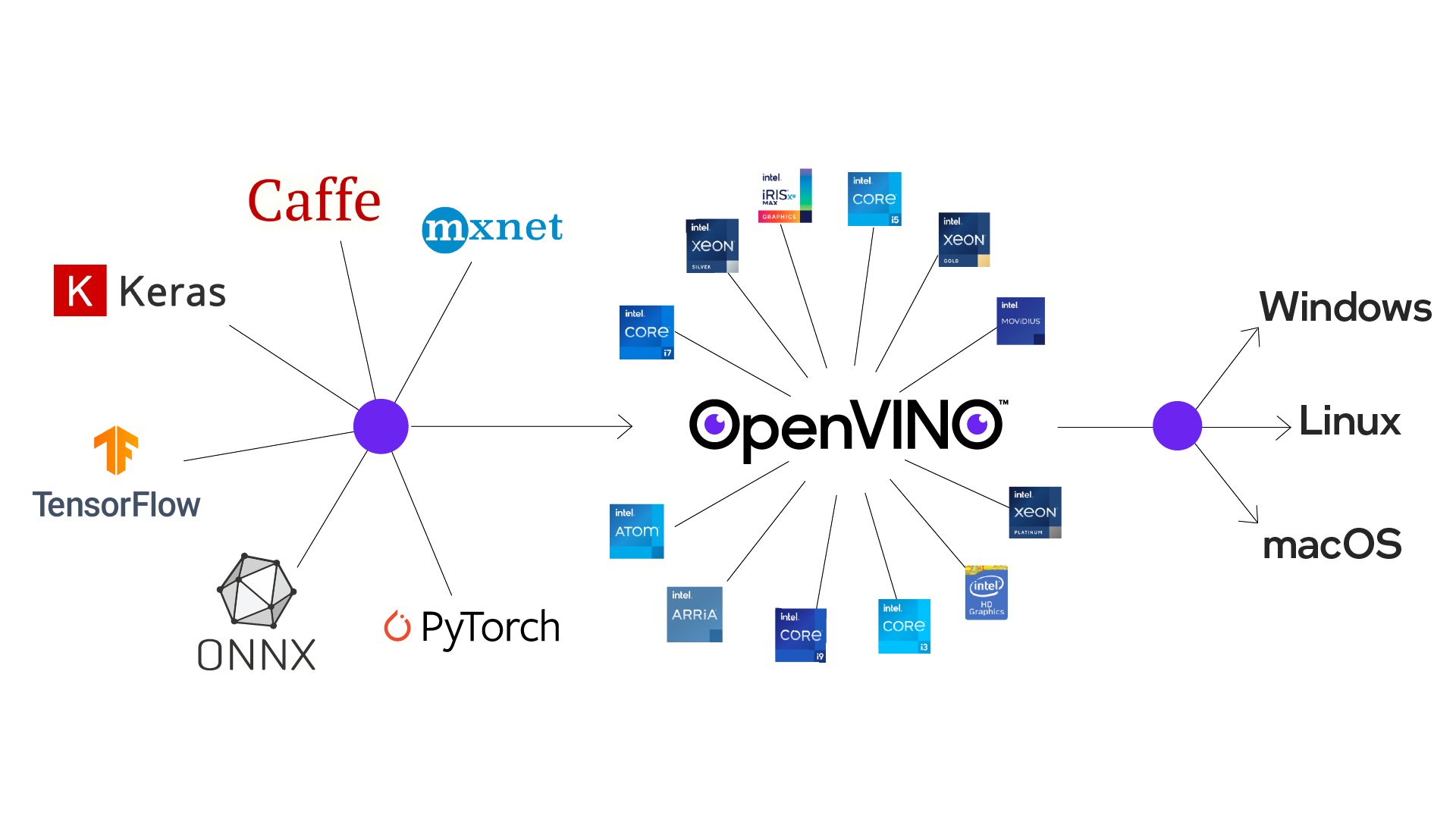
OpenVINO執行模型最佳化後能跨平台佈署AI推論(圖片來源: Intel)
OpenVINO為Intel於2018年推出的AI佈署工具套件,支援不同深度學習軟體框架如TensorFlow、PyTorch、Caffe等的模型輸入,並對模型進行最佳化與調教後,佈署於不同作業系統進行推論。其初版發布時間和Intel推出NCS2(Neural Compute Stick 2)的時間點相當接近,而一直讓筆者有著「OpenVINO就是要來搭配NCS2進行AI推論最佳化」的一種錯覺。
直到後來OpenVINO版本持續更新提其高支援完整性與提高了易用性,才讓筆者確實看清,以目前Intel CPU/GPU的處理效能,已經足以負荷多數情境的AI應用推論了!如下方長條圖顯示著Intel的不同世代顯示晶片在的AI推論效能比較,分別以第九代iGPU與第12代iGPU執行不同模型之間的效能差異。其中光是Gen12相比Gen9跑FP16模型推論FPS就已超過兩倍之譜,若是將模型轉換為INT8進行推論更可以在將效能再拉升至一倍左右!若要進一步了解OpenVINO各AI模型對應不同處理器的效能,也可以參照OpenVINO Benchmark Result。
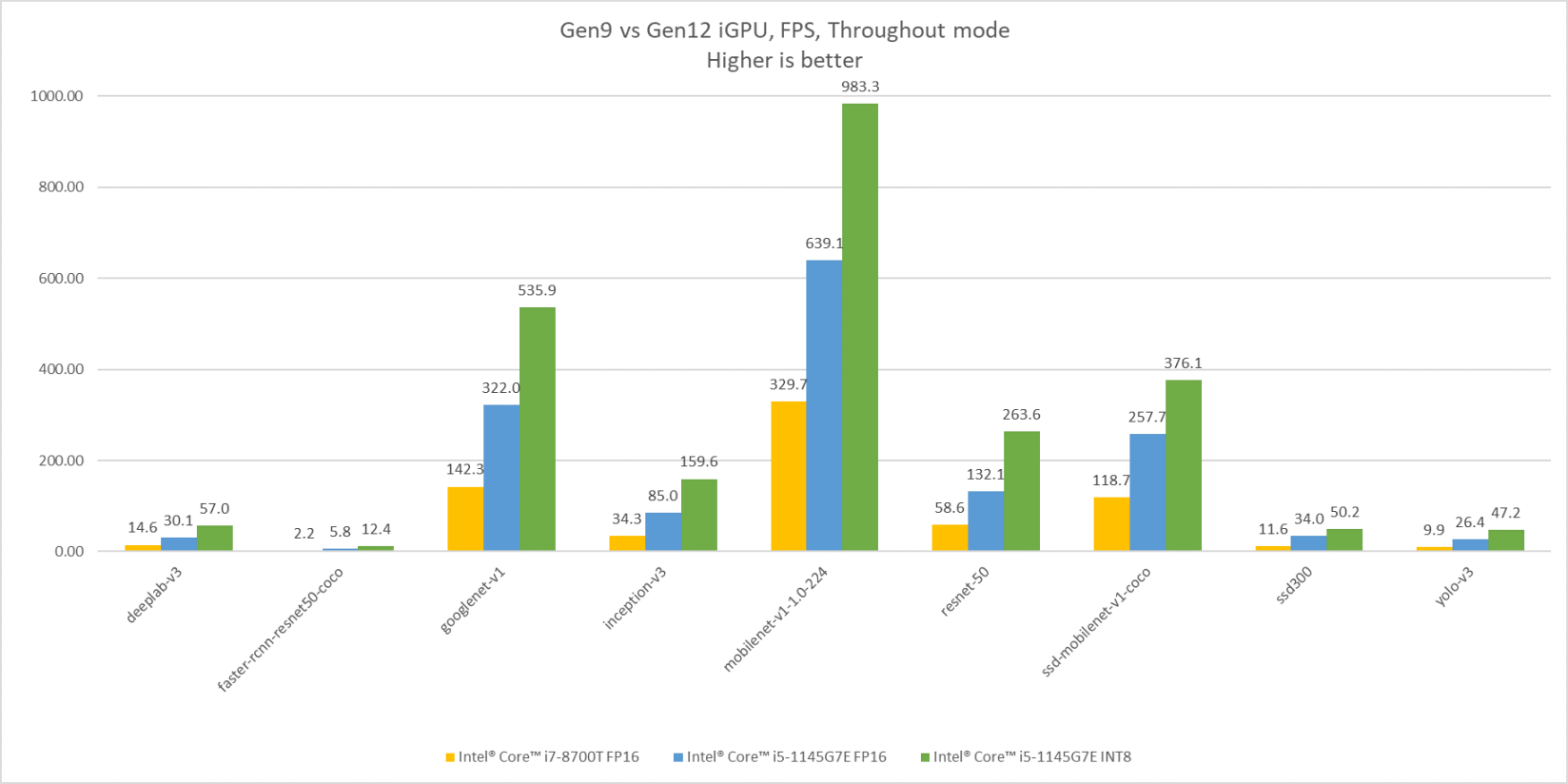
Intel Gen9 與 Gen12 iGPU AI推論效能比較 (圖片來源: OpenVINO-toolkit)
在分別接觸了Teachable Machine與OpenVINO之後,不禁讓人聯想,是否能讓這兩個簡單易用的酷工具結合在一起?一個負責處理模型訓練,另一個負責處理推論與應用,若能成功便可讓大夥享齊人之福,把複雜事情簡單化,短時間內即可完成應用雛形。不囉嗦即刻來做測試!
我們先到Teachable Machine網站上去訓練模型,至於要辨識的影像就直接就地取材-使用我們的雙手做手勢的分類。這裡筆著做了五個手勢分類,分別為剪刀、石頭、布、讚、以及數字7的手勢,各取得約略350張的影像資料作為輸入的dataset。訓練參數則直接用預設參數:EPOCH: 50,Batch Size: 16,Learning Rate: 0.001進行訓練。最後我們就選擇Export Model將模型匯出,選擇的格式為TensorFlow Savedmodel方便OpenVINO進行轉換,順利取得converted_savedmodel.zip檔案即完成模型訓練的步驟啦!
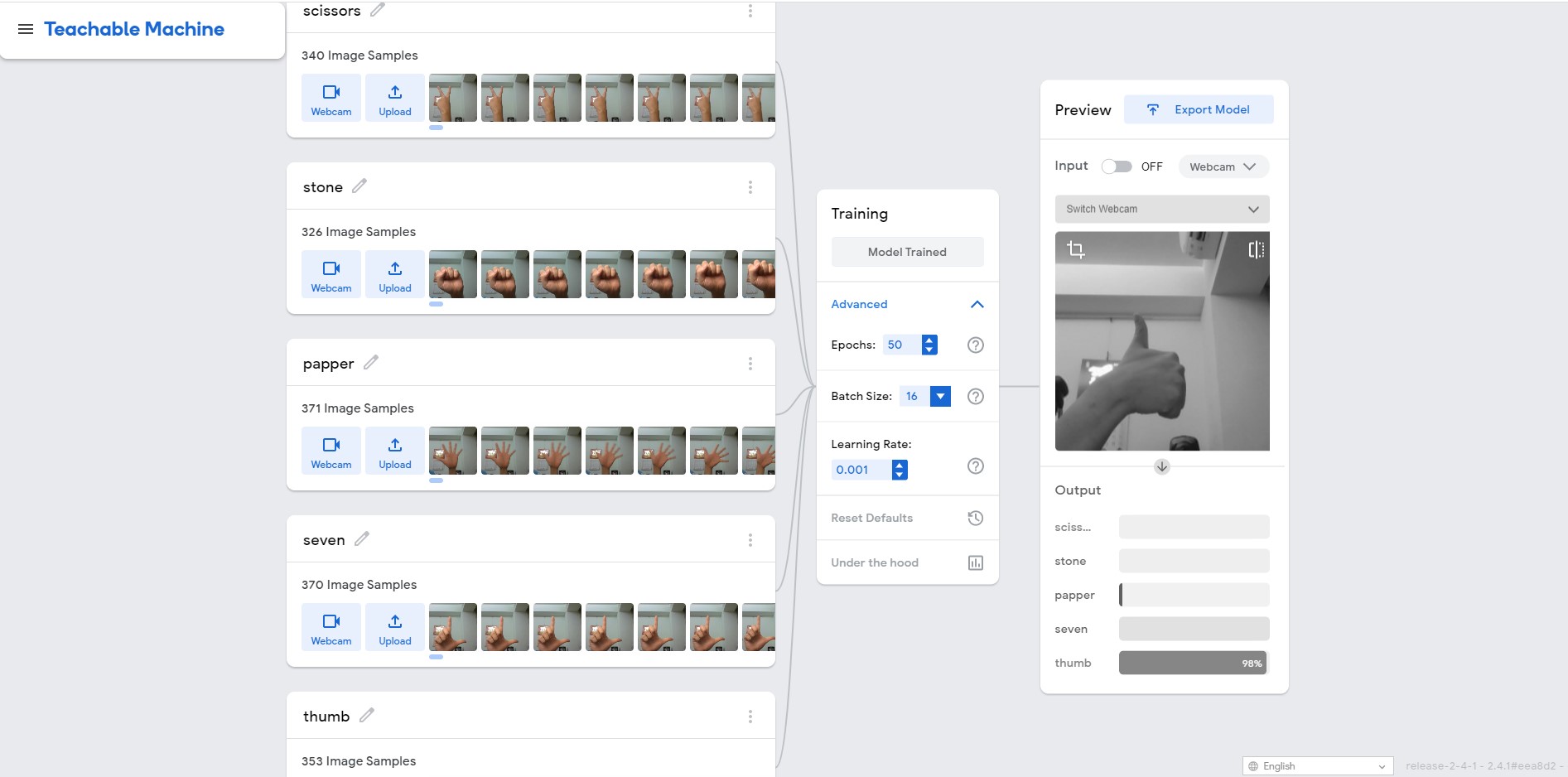
在Teachable Machine訓練影像分類模型
接著我們要將從Teachable Machine取得的TensorFlow模型檔(.pb),使用OpenVINO進行轉換。筆者的測試環為Ubuntu20.04作業系統,OpenVINO Tookit使用2021.4 LTS版本,處理器為Intel i7-1185GRE(搭載Iris Xe顯示晶片)。要建置OpenVINO開發環境除了在原生系統下載安裝包執行所有套件的安裝外,現在也可以使用docker快速建置環境,過程其實沒什麼難度,按照官方文件指引Step by Step就可以了,或是參考Jack大的docker建置教學都是很棒的資源,這裡就不多做贅述了。
為了方便建立一個名為tm的資料夾,存放teachable machine模型資料,並且解壓縮得到saved_model.pb與labels.txt等檔案。
~$ mkdir tm
~$ cd tm
~/tm$ unzip converted_savedmodel.zip
Archive: converted_savedmodel.zip
creating: model.savedmodel/
extracting: model.savedmodel/saved_model.pb
creating: model.savedmodel/variables/
extracting: model.savedmodel/variables/variables.data-00000-of-00001
extracting: model.savedmodel/variables/variables.index
creating: model.savedmodel/assets/
extracting: labels.txt
~/tm$
接著執行model optimizer進行模型最佳化轉換,指定目前資料夾取得pb檔,這邊要注意input_shape參數必須指定為[1,224,224,3],其意義為[N,H,W,C]:
- N: 一次抓取多少數量的影像。
- H: 影像的高度,單位為象素。
- W: 影像的寬度,單位為象素。
- C: 通道數量。若是彩色圖像則有RGB三個通道。
上述若N為未知數值(負值)會造成轉換上的錯誤,而在TensorFlow上預設輸入的shape為[-1,224,224,3],因此要手動進行shape調整。此外,Teachable Machine使用MobileNet神經網路架構,轉換的scale依據OpenVINO轉換TensorFlow文件得知為127.5,我們便以此數值代入。最後筆者希望可以得到較佳的推論速度,帶入data_type參數,並指定模型權重值以FP16的數值格式進行量化。輸入以下指令進行模型轉換:
~/tm$ source /opt/intel/openvino_2021/bin/setupvars.sh
[setupvars.sh] OpenVINO environment initialized
~/tm$ mo_tf.py --saved_model_dir model.savedmodel/ --input_shape [1,224,224,3] -s 127.5 –data_type=FP16
執行成功後會在當前目錄得到IR(Intermediate Representation)檔saved_model.xml與saved_model.bin。我們就能使用這個IR模型中繼檔在OpenVINO上進行推論。
推論的部分在邊緣裝置的推論我們使用OpenVINO toolkit內建的Classification的Demo來做測試,看看實際結果如何。因影像分類Demo目前僅提供C++語言版本,我們需要先行做編譯:
~$ cd /opt/intel/openvino_2021/deployment_tools/open_model_zoo/demos/
/opt/intel/openvino_2021/deployment_tools/open_model_zoo/demos$ ./build_demos.sh
Setting environment variables for building demos...
[setupvars.sh] OpenVINO environment initialized
-- The C compiler identification is GNU 9.3.0
... 中間訊息省略 ...
[100%] Built target human_pose_estimation_demo
Build completed, you can find binaries for all demos in the /home/openvino/omz_demos_build/intel64/Release subfolder.
/opt/intel/openvino_2021/deployment_tools/open_model_zoo/demos$
編譯完成後會看到提示訊息說明可執行檔的路徑,同時我們將額外的手勢照片存放到~/tm/pic的路徑,讓範例程式可以用這些圖像作為測試資料。執行下方指令啟動範例程式,相關參數說明如下:
- -i: <必要參數>,輸入影像資料的檔案路徑或資料夾路徑
- -m: <必要參數>,IR模型檔xml的檔案路徑
- -labels: <必要參數>,分類標籤文字檔的路徑
- -d: 執行推論的硬體裝置進行推論,可選CPU, GPU,也可以設定MULTI:CPU,GPU同時使用CPU與GPU執行推論。預設為CPU。
- -time: 重複執行推論的時間,預設為-1,代表執行到使用者中斷為止。
- -no_show: 不顯示影像推論結果。
- -nt: 取得前n個最大可能的類別,預設為5。
~$ cd ~/omz_demos_build/intel64/Release
~/omz_demos_build/intel64/Release$ ./classification_demo -d GPU -m ~/tm/saved_model.xml -i ~/tm/pic/ -labels ~/tm/labels.txt
[ INFO ] InferenceEngine: IE version ......... 2021.4
Build ........... 0
[ INFO ] Parsing input parameters
[ INFO ] Reading input
[ INFO ] Files were added: 20. Too many to display each of them.
[ INFO ] Loading Inference Engine
[ INFO ] Device info:
[ INFO ] GPU
clDNNPlugin version ......... 2021.4
Build ........... 0
Loading network files
[ INFO ] Batch size is forced to 1.
[ INFO ] Loading model to the device
待模型載入後會跳出一個圖形化視窗,顯示著目前進行影像分類識別的結果。我們可以看到大部分判定的結果是符合我們的預期的,而少部分判定錯誤的圖像經測試後是在Teachable Machine上就辨識度不佳的圖片,整體而言推論分類結果令人滿意!
左上角同時顯示著當前的效能指標Latency與FPS,因為需要額外處理影像輸出的辨識結果,這會降低非常多FPS,所以此數值僅能做參考之用。若想要知道不做輸出影像的效能可以每秒幾張圖像,只要在剛剛執行的命令後面,再加上-no_show –time 10,意思就是不輸出推論的影像,並且在模型啟動推論10秒後結束程式。當DEMO程式返回時就會顯示Latency與FPS,筆者在僅使用GPU的情況下,效能測時得到的結果就高達654.9 FPS與7.2 ms Latency!
此外再補充一點,若我們在Teachable Machine上訓練的影像分類數量少於5個分類,在執行DEMO程式時可能會出現"[ ERROR ] The model provides 2 classes, but 5 labels are requested to be predicted"此錯誤訊息,原因在於DEMO程式預設會去抓取可能性最高的前5個分類,而實際模型輸出的分類數量卻少於5個分類而產生錯誤。可以再加上參數”-nt 1”指定DEMO程式只取得可能性最高的分類即可。

Image classification推論測試結果
小結
各位看過以上流程之後,是不是覺得訓練影像分類模型並且佈署在自己的裝置上執行不再遙不可及,而且是既簡單又容易的事!藉由這類簡單工具組件幫助我們完成邊緣算的訓練、轉換、到佈署總體時間約略在半小時內即可完成。雖然距離實際應用可能還有一小段差距,但藉由把複雜的事情拆解成各個簡單的組件與任務,短時間內就能綜觀全局而找到對的方向努力,各位腦中是否已浮現出各種應用可能性的想像了呢!?
(責任編輯:謝涵如)

- 以MCU開啟Edge AI新境界:Renesas RA8P1實測 - 2025/10/22
- Windows on Snapdragon部署GenAI策略指南 - 2025/09/23
- 運用Qualcomm AI Hub結合WoS打造低功耗高效能推論平台 - 2025/08/01
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


