作者:曾成訓(CH.Tseng)
利用 COCO dataset 所抓取的 person 物件,雖然可以得到數量非常多的標記圖片(總計有 45,174 標記檔),但若打算應用在人物計算和追蹤上,其實不太合用,最主要的原因在於 COCO 針對多人群聚的標記方式有問題,例如下方這張相片:

(圖片來源:曾成訓提供)
後方的一排球員,並不是每一個都有標識,此外還有一個大標記來註明這一區也是「person」,這種作法會造成我們在計算或需要明確的個人形體識別時造成困擾,因此我們需要找一個對於 person 有明確且嚴謹標識 dataset。
目前最為完整適用於群聚 person 檢測的 dataset 有兩個:CityPersons 及 CrowdHuman,都是由對岸中國開源釋出的,這類的資料集最大的用途在於行人檢測、跟蹤和檢索等。
- 行人檢測:將影片或相片中的所有行人框選出來
- 行人跟蹤:將影片中不同行人的軌跡串連起來,進而識別個體及行進方向
- 行人檢索:將感興趣的人物從影片中檢索出來
CityPersons
由南京理工大學的張姍姍教授於 2017 年發表,請見相關論文,如果您有興趣,下面是該 dataset 發表時的介紹影片,由張姍姍教授主講。
- dataset 影像來源:
Cityscapes資料集(攝於德國18個城市)
- 圖片及標記的行人數目:
- Train dataset: 2975張圖片/ 19,654個行人
- Val. dataset: 500張圖片/ 3,938個行人
- Test dataset: 1575張圖片 / 11,424個行人
- Classes(標記 labels):
- pedestrian(walking,running,standing up)
- rider(riding bicycles or motorbikes)
- sitting person
- other person(非正常姿勢)
- Dataset download:
- 標記檔及 trained models
- 圖片檔需另外從 Cityscapes 網站申請下載
Cityscapes 的 dataset 必須透過線上申請才能下載,我申請了登入帳號並已啟用,但狀態一直停留在等待管理員核可的階段,因此無法下載此 dataset。
CrownHuman
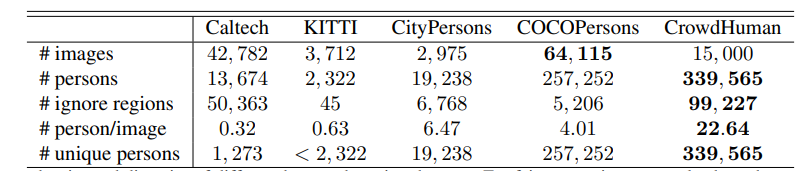
這是由中國最知名的 AI 獨角獸公司矌視科技(Face++)所釋出的資料集,圖片及標記數目比起 CityPersons 更多更完整。以下為各 dataset 的比較,可見 CrowdHuman 是目前最適合用於訓練行人檢測的資料集。
(圖片來源:曾成訓提供)
從下這張圖,可看出 CrowdHuman 驚人的檢測效果,上方由左至右的綠黃藍框,分別為 COCO、Caltech、CityPersons 所訓練出的識別結果,下方紅框則為 CrowdHuman 的識別效果。

(圖片來源:曾成訓提供)
另外,CityPersons 可直接經由官方網站下載,不需申請。
CrowdHuman 標記格式
針對同一個 human 提供如下三種 BBox:
- Head BBox:針對頭部的標記
- Visible BBox:影像中的身體可見區域的標記
- Full BBOX:完整身體區域,看不見區域為預測

(圖片來源:曾成訓提供)

(圖片來源:曾成訓提供)
由 CrowdPerson 提供的這三種標記,我們除了能精確地標識出影像中的所有人,也能得到該人被遮蔽的程度。
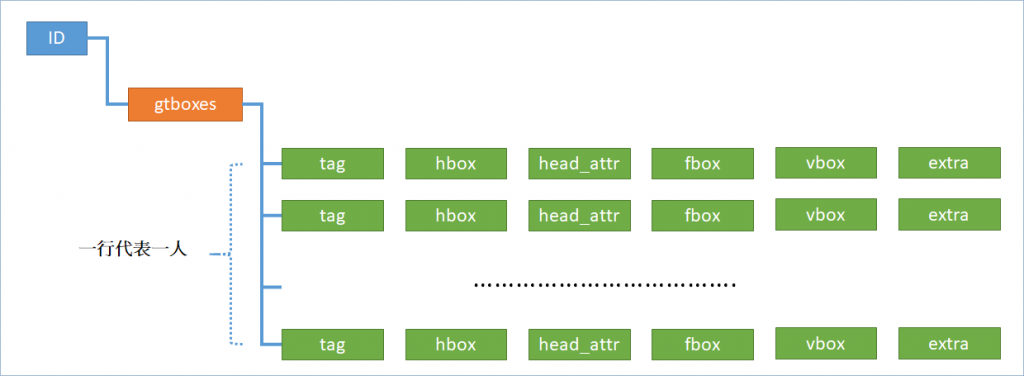
標記檔格式
Train 與 Validation 的標記資訊分別存放於 annotation_train.odgt 以及 annotation_val.odgt 兩個檔案,odgt 是一種標注檔案的格式,每一行為一獨立的 json 格式文字,代表一張影像檔的標記內容,因此 dataset 有多少張相片,該 odgt 檔便有幾行,以其中一行為例:

這串文字的格式可整理成:
(圖片來源:曾成訓提供)
- ID:圖片檔案名稱
- gtboxes:所有的 BBox list
- tag:用來 label 名稱,共兩種:person 及 mask;mask 是指:crowd、reflection、something like person 這類的情況,一般我們只需要取出 person 即可
- hbox:頭部的 BBox(Head)
- head_attr:頭部的一些屬性
- fbox:全身的 BBox(Full body)
- vbox:沒有被遮蔽的 BBox(Visible body)
- extra:BBox 的額外屬性
以上持續重複 tag、hbox、extra,視影像中有多少人而定。
撰寫擷取物件的程式
如果只想抓取 head 部份,則 target_class 內容請設定成 target_class = [ “head” ],取出的 class 名稱計有 person_head 和 mask_head 兩種,這是因為 CrowdHuman 的 gtboxes 標記當中的 tag 有兩種內容:person 及 mask,代表影像中的是真人或假人倒影。
如果想抓取 full body 及 visible body,那麼 target_clas 內容要設定成 target_class = [ “fbody”, “vbody” ],這樣取出的 class 將會有四種:person_fbox、person_vbox、mask_fbox 及 mask_vbox。
要抓取全部(head、full body、visible body)的話,則 target_class 內容設為空值即可:target_class = [],這樣取出的 class 將會有六種:person_head、person_fbox、person_vbox、mask_head、mask_fbox 及 mask_vbox。
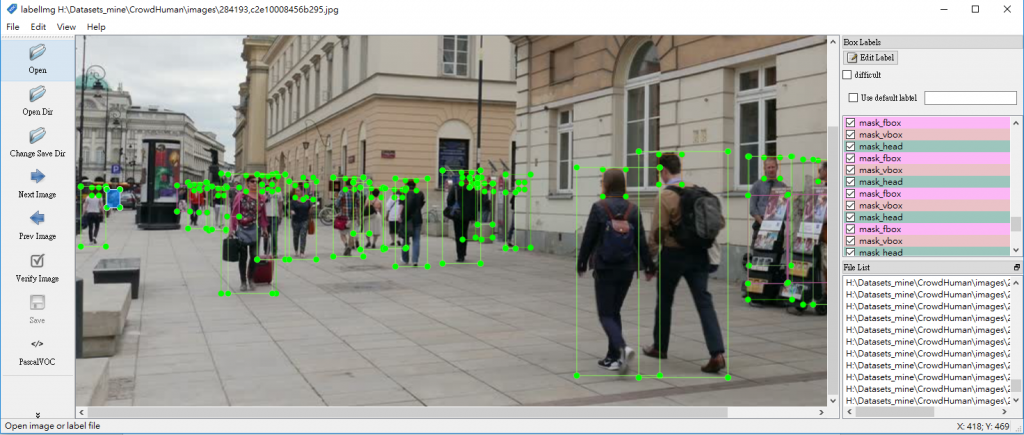
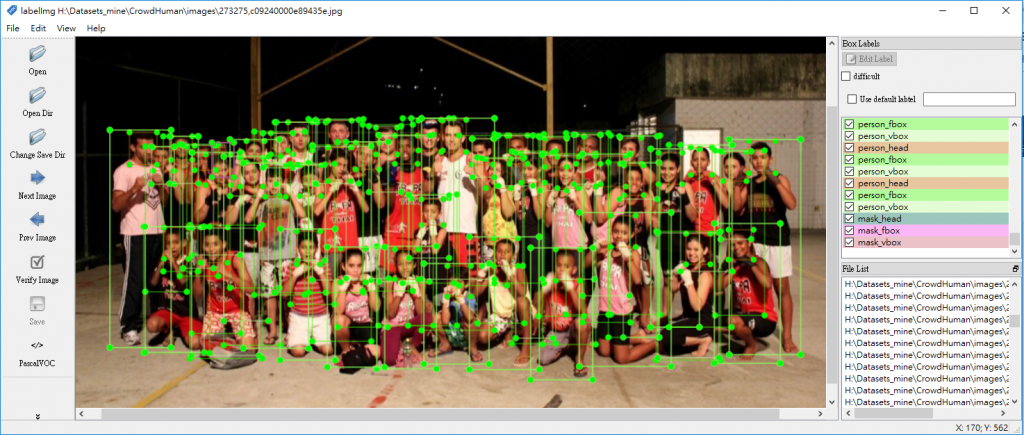
執行後,產生的 dataset 可以用 labelImg 開啟,而且已經轉換為 PASCAL VOC 標記格式,會發現影像中每一位人物皆予以鉅細靡遺的標記,有的相片標記人數甚至高達數十或上百個,可見 CrowdHuman dataset 所投入的人力與時間真的不在話下。
(圖片來源:曾成訓提供)

(圖片來源:曾成訓提供)
(圖片來源:曾成訓提供)
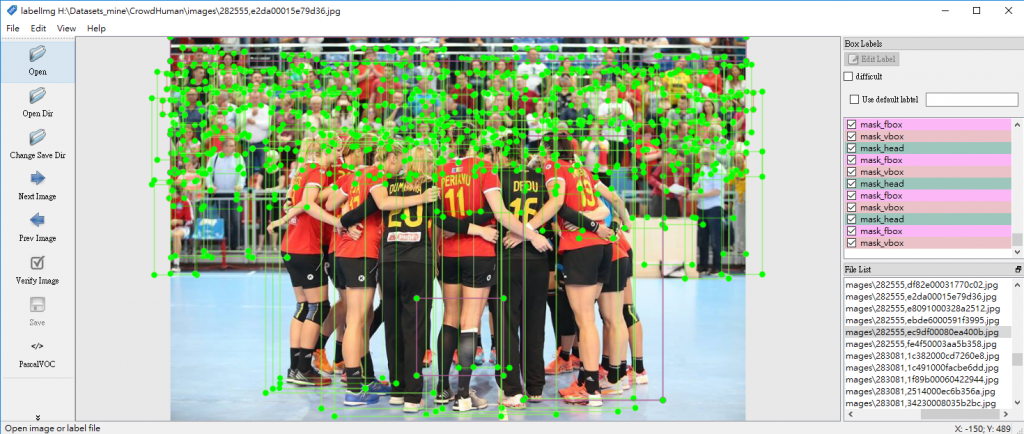
(圖片來源:曾成訓提供)
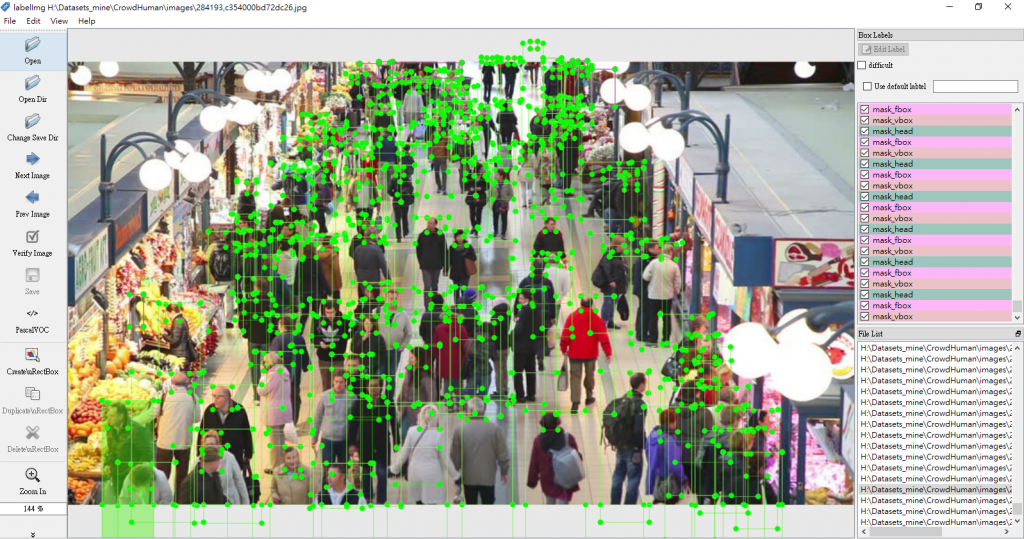
(圖片來源:曾成訓提供)
參考程式
import json
import cv2
import imutils
import time
import os, glob
target_class = [] #["head", "fbody", "vbody", "mask"] #[] --> all
#target_class = []
annotations_path = "/WORK1/dataset/crowdHuman/annotation_train.odgt"
crowdHuman_path = "/WORK1/dataset/crowdHuman/Images"
xml_file = "xml_file.txt"
object_xml_file = "xml_object.txt"
#output
datasetPath = "/DATA1/Datasets_mine/labeled/crowd_human_dataset"
imgPath = "images/"
labelPath = "labels/"
imgType = "jpg" # jpg, png
def check_env():
if not os.path.exists(os.path.join(datasetPath, imgPath)):
os.makedirs(os.path.join(datasetPath, imgPath))
if not os.path.exists(os.path.join(datasetPath, labelPath)):
os.makedirs(os.path.join(datasetPath, labelPath))
def writeObjects(label, bbox):
with open(object_xml_file) as file:
file_content = file.read()
file_updated = file_content.replace("{NAME}", label)
file_updated = file_updated.replace("{XMIN}", str(bbox[0]))
file_updated = file_updated.replace("{YMIN}", str(bbox[1]))
file_updated = file_updated.replace("{XMAX}", str(bbox[0] + bbox[2]))
file_updated = file_updated.replace("{YMAX}", str(bbox[1] + bbox[3]))
return file_updated
def generateXML(imgfile, filename, fullpath, bboxes, imgfilename):
xmlObject = ""
for (labelName, bbox) in bboxes:
xmlObject = xmlObject + writeObjects(labelName, bbox)
with open(xml_file) as file:
xmlfile = file.read()
img = cv2.imread(imgfile)
cv2.imwrite(os.path.join(datasetPath, imgPath, imgfilename), img)
(h, w, ch) = img.shape
xmlfile = xmlfile.replace( "{WIDTH}", str(w) )
xmlfile = xmlfile.replace( "{HEIGHT}", str(h) )
xmlfile = xmlfile.replace( "{FILENAME}", filename )
xmlfile = xmlfile.replace( "{PATH}", fullpath + filename )
xmlfile = xmlfile.replace( "{OBJECTS}", xmlObject )
return xmlfile
def makeLabelFile(filename, bboxes, imgfile):
jpgFilename = filename + "." + imgType
xmlFilename = filename + ".xml"
xmlContent = generateXML(imgfile, xmlFilename, os.path.join(datasetPath ,labelPath, xmlFilename), bboxes, jpgFilename)
file = open(os.path.join(datasetPath, labelPath, xmlFilename), "w")
file.write(xmlContent)
file.close
if __name__ == "__main__":
check_env()
img_filename = {}
img_bboxes = {}
f = open(annotations_path)
lines = f.readlines()
total_lines = len(lines)
for lineID, line in enumerate(lines):
data = eval(line)
img_id = data["ID"]
total_iid = len(data["gtboxes"])
for iid, infoBody in enumerate(data["gtboxes"]):
tag = infoBody["tag"]
hbbox = infoBody["hbox"]
head_attr = infoBody["head_attr"]
fbbox = infoBody["fbox"]
vbbox = infoBody["vbox"]
extra = infoBody["extra"]
if(len(target_class)==0 or ("head" in target_class)):
if(img_id in img_bboxes):
last_bbox_data = img_bboxes[img_id]
last_bbox_data.append((tag+"_head", hbbox))
img_bboxes.update( {img_id:last_bbox_data} )
else:
img_bboxes.update( {img_id:[(tag+"_head", hbbox)]} )
if(len(target_class)==0 or ("fbody" in target_class)):
if(img_id in img_bboxes):
last_bbox_data = img_bboxes[img_id]
last_bbox_data.append((tag+"_fbox", fbbox))
img_bboxes.update( {img_id:last_bbox_data} )
else:
img_bboxes.update( {img_id:[(tag+"_fbox", fbbox)]} )
if(len(target_class)==0 or ("vbody" in target_class)):
if(img_id in img_bboxes):
last_bbox_data = img_bboxes[img_id]
last_bbox_data.append((tag+"_vbox", vbbox))
img_bboxes.update( {img_id:last_bbox_data} )
else:
img_bboxes.update( {img_id:[(tag+"_vbox", vbbox)]} )
filename = img_id + ".jpg"
img_filename.update( { filename:img_id } )
print("[Left over] {}/{} , {}: head:{} full:{} visible:{}".format(total_lines-lineID, total_iid-iid, img_id,\
hbbox, fbbox, vbbox))
for file in os.listdir(crowdHuman_path):
file_name, file_extension = os.path.splitext(file)
if(file in img_filename):
bbox_objects = {}
if(file in img_filename):
img_id = img_filename[file]
if(img_id in img_bboxes):
bboxes = img_bboxes[img_id]
makeLabelFile(file_name, bboxes, os.path.join(crowdHuman_path, file))(本文經作者同意轉載自 CH.TSENG 部落格、原文連結;責任編輯:賴佩萱)

- 【模型訓練】訓練馬賽克消除器 - 2020/04/27
- 【AI模型訓練】真假分不清!訓練假臉產生器 - 2020/04/13
- 【AI防疫DIY】臉部辨識+口罩偵測+紅外線測溫 - 2020/03/23
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


