作者:許哲豪 Jack
最近 Nvidia 推出 Jetson Nano AI 開發板,瞬間刷爆各大人工智慧社群版面,害得我原本整理好的十幾個 AI 開發板文章頓時失去貼出的動力,因為 Jetson Nano 的低價(US$99)與高性能(472 GFlops)已輾爆包括 Coral Google Edge TPU 的所有開發板。

三大 AI 開發板 (圖片來源:Jack 提供)
初步比較目前較夯的三大 AI 開發板:Nvidia Jetson Nano、Coral Google Edge TPU、Intel(Movidius)Neural Compute Stick 2,如下表所示。嚴格說起來 Intel 的神經運算棒並無法單獨存在,需要另外搭配有 CPU 的主機板,而樹莓派的算力太弱,不足以稱為 AI 開發板,所以通常會把這兩者組合成一組 AI 開發板,像 Google AIY Vision Kit 就是同類型的整合產品。
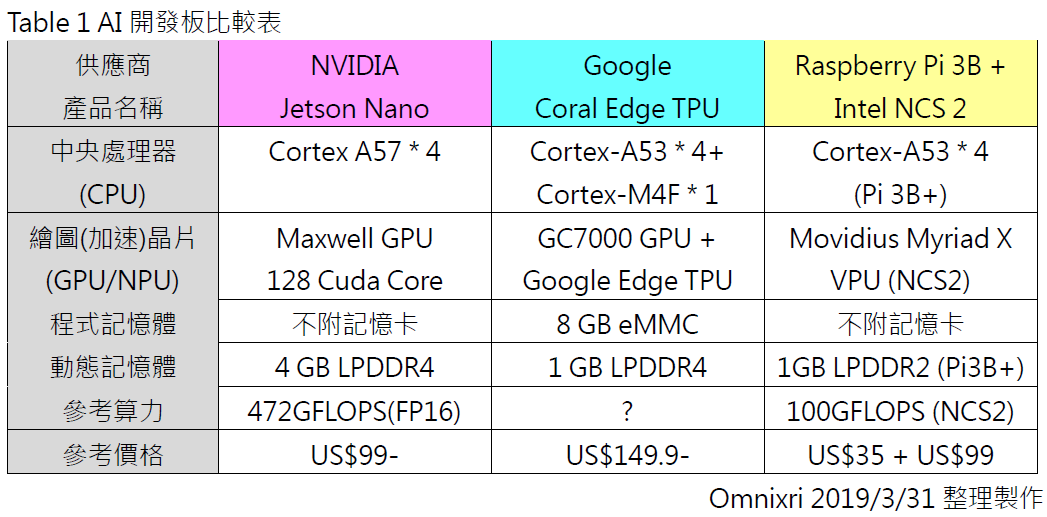
三大 AI 開發板各性能比較(圖片來源:Jack 提供)
目前這些 AI 開發板並沒有通用的比較基準,傳統上可用「每秒可執行多少浮點數」運算(Float pre Second,FLOPS)或「每秒執行多少」運算(Opertions,OPS)來比較。一般 GPU 或 NPU 多半被設計作為矩陣運算用,所以 A*B+C 本來需要兩道指令(乘法和加法)才能完成,會變成一道指令就可執行,所以若以 OPS 表示時,就會變成兩倍,如此便會造成執行速度較快的錯覺。
在深度學習的計算上,除了大量的矩陣演算外,尚有許多數百萬甚至數億個參數需要來回存取,但由於受限於記憶體速度及頻寬問題,常會造成不同模型的計算上有不同的性能表現。舉例來說,若在高速公路上行駛,則跑車的表現一定輾爆一般轎車;若需不斷上下交流道,那麼跑車就不一定勝過一般轎車太多。
另外,相同的模型在不同框架(TensorFlow、Caffe、PyTorch)或者經過特別的優化、壓縮、剪枝等,甚至依據硬體特性而修正模型,也有可能產生計算效能(速度)的差異。
由於 Google Coral Edge TPU 上市沒多久,官方及民間高手皆尚未大量提出測試數據,所以 TPU 實際有多厲害,僅能從 Alasdair Allan 發表的文章一窺究竟。這次 Nvidia 為了讓大家知道 Jetson Nano 有多優秀,特別製表比較三大 AI 開發板的性能,如下表所示,不過根據這些公開的數據比較,其實反而透露了一個重要訊息,就是「不要太相信廠商提出的算力大小」,參考一下就好。
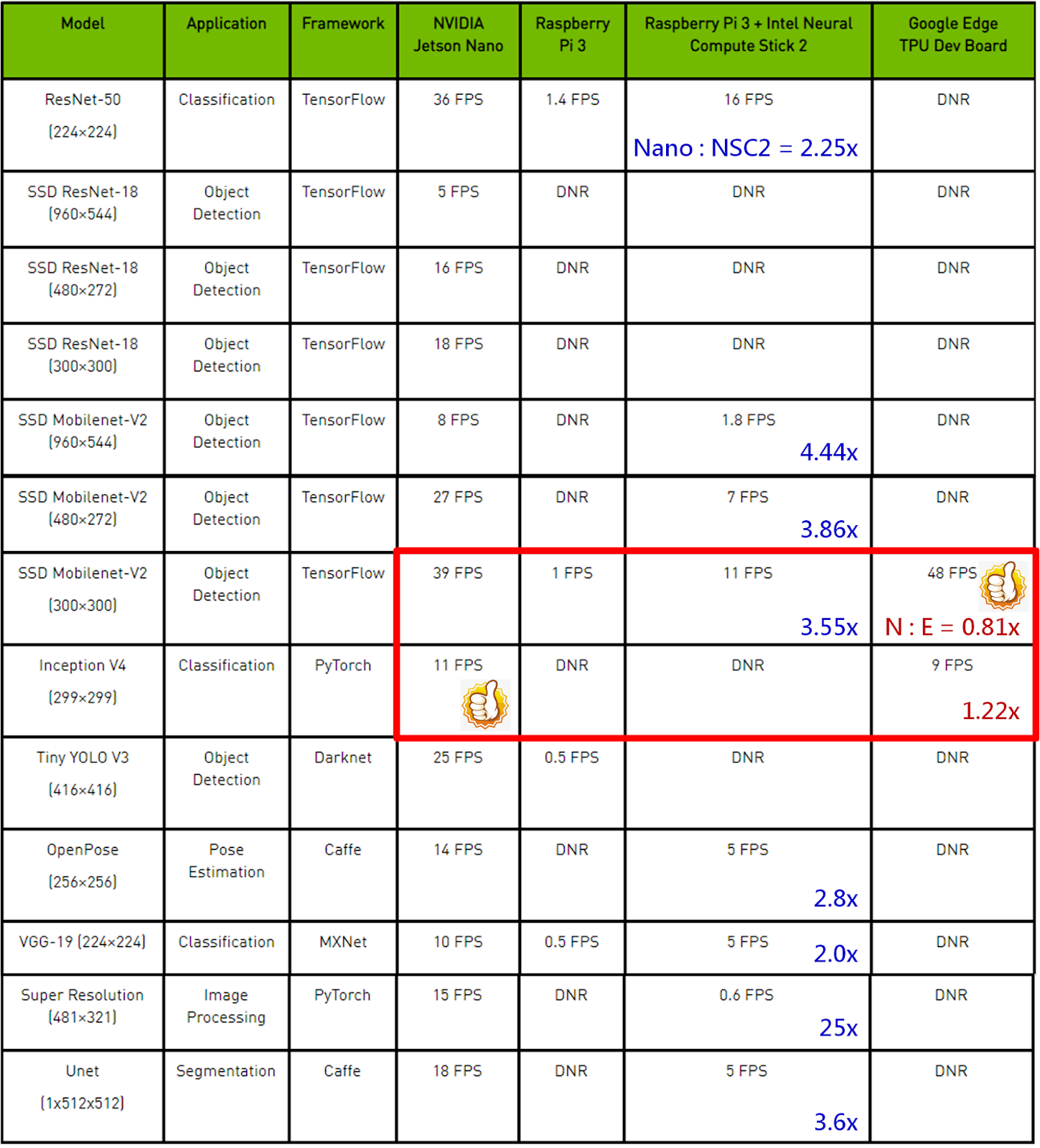
AI 開發板算法與性能比較表(圖片來源:Nvidia Developer)
為何如此說呢?以 Nvidia Jetson Nano 與 Pi3+NSC2 二組開發板比較,理論上硬體算力應該是固定倍率的差異,但在不同模型(算法下)竟然可以從差 2 倍到 25 倍,更令人費解的是,在部份模型中 Google Coral Edge TPU 竟然勝過 Nvidia Jetson Nano,這中間到底發生什麼事了?個人猜想應該是「特定模型在特定框架下剛好滿足 TPU 的最佳計算方式,所以得到較好的表現」,還請各路高手提出高見解惑。
不論誰家產品較為優秀,對於 Maker 而言,便宜又算力強大的 AI 開發板時代已來臨,以後就再也沒有藉口說算力太貴無法做出好的作品啦!
(本文轉載自歐尼克斯實境實驗室、原文連結;責任編輯:賴佩萱)

主持歐尼克斯實境互動工作室(OmniXRI):http://omnixri.blogspot.com
Edge AI Taiwan邊緣智能交流區:https://www.facebook.com/groups/edgeaitw/
- Arduino UNO Q教學案例整理 - 2026/03/09
- 有了Intel AI Playground 不寫程式也能輕鬆玩生成式AI - 2025/09/02
- 【開發資源】TinyML MCU 等級開源推論引擎 - 2025/06/09
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!



2019/06/11
非常讚同作者的觀點「特定模型在特定框架下剛好滿足 TPU 的最佳計算方式,所以得到較好的表現」。國外開發者的評測結果顯示,Google Coral Edge TPU在MobileNet模型的運行速度比直接競爭對手快3到4倍。但是總的來說,推理速度並不能決定硬件的好壞,這隻是其中的一個因素。