作者:許哲豪/Jack Hsu
今年 Computex & InnoVEX 2018 中可以嗅出一個方興未艾的風潮,那就是邊緣運算,本文將介紹邊緣運算為何興起,以及有哪些台灣廠商已推出相應的解決方案。
一年一度的 Computex & InnoVEX 2018 在不久前熱鬧閉幕,每年我總會撥個一、兩天去參觀,今年另外加碼了一天半參加了三場 Computex Forum:「串聯 AI 生態系」、「遇見明日新科技」及「顛覆物聯新視界」,感受到不一樣的氣氛。
整體來說,從展場熱點來看個人電腦及週邊已有逐漸淡去的感覺,取而代之的是行動通訊、人工智慧、物聯網及相關的應用軟體等相關應用。尤其世貿三館的 InnoVEX 更是明顯,大多新創公司都展現出未來「萬物皆智能(AIoT = AI + IoT)」的趨勢。
不論是家電、交通、零售、虛擬擴增實境(AR/VR/XR)、人機互動、醫療、食安、農業、金融、安全監控、電商平台及城市環境等等,無一沒有智能管理、分析及預測。經過幾天的看展隱約嗅到一股風潮即將興起,那就是「邊緣運算」(Edge Computing)(也稱「邊緣計算」),為什麼這麼說呢?接下來就把此次看展的心得整理一下分享給大家。
「人工智慧元年」到來
每年總會聽到政府又提出新口號,2010 雲端運算(Cloud Computing)元年、2015 物聯網(Internet of Thing, IoT)元年、2016 大數據(Big Data)元年,今(2018)年不免俗的也提出人工智慧(Artificial intelligence, AI)元年。
不過今年感覺似乎不只有口號,不僅公部門編列大量的預算採購設備及投資具有學研背景的新創團隊,平日只作學術論文的研究機構也開始投身解決廠商問題,民間機構緊接在後大力培訓相關人才,業界也開始天馬行空的提出各項應用,好像在面對國家存亡之戰一般的緊張,生怕一不小心就被踢出世界的舞台,或許這一波的動力會讓台灣的硬體思維能有所改善吧?
「邊緣運算」即將興起
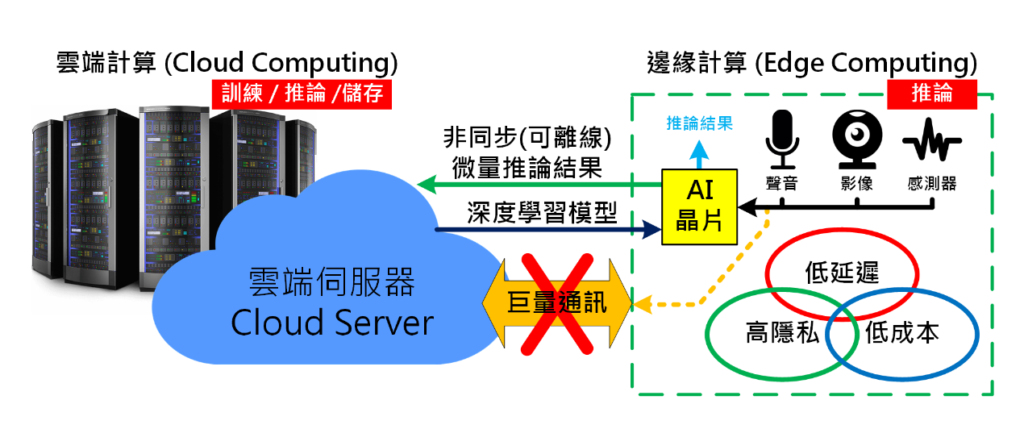
雲端及邊緣運算(圖片來源:OmniXRI 整理製作)
2012年「深度學習(類神經網路)」技術的突破帶動了新一波「人工智慧」崛起,其中最大功臣莫過於繪圖晶片(GPU)。接踵而來的是大量的建置以 GPU 為主的深度學習計算用伺服器來進行高速運算,不論是影像(物件)辨識、人臉(性別、年紀、情緒)識別、自然語言分析、語言翻譯、文義提取、文藝創作等等都要靠強大的雲端(無論公有雲或私有雲)計算才能完成。
雖然雲端可獲得接近無限的計算能力,但有太多場合基於個人隱私(資料保密)問題不能上網,或者是計算延遲性太高不符實務需求,更重要的是一直上網利用雲端服務(計算、儲存)要一直付錢,這可是使用者最不樂見的,因此在一需求下「邊緣運算」應運而生。
邊緣計算強調可針對特定需求只作單一或少量功能,因此不需像訓練時所需的巨量運算,只需利用訓練好的模型在特定排程或時間內完成推論(Inference)即可,運算量相對減少很多,所以大多數情況下可利用 AI 晶片(或神經網路加速)(CPU, GPU, FPGA, ASIC, SoC 等)即可達成。有興趣的朋友可參考我先前的發文「人工智慧 AI 晶片與 Maker 創意接軌(上)(中)(下)」。
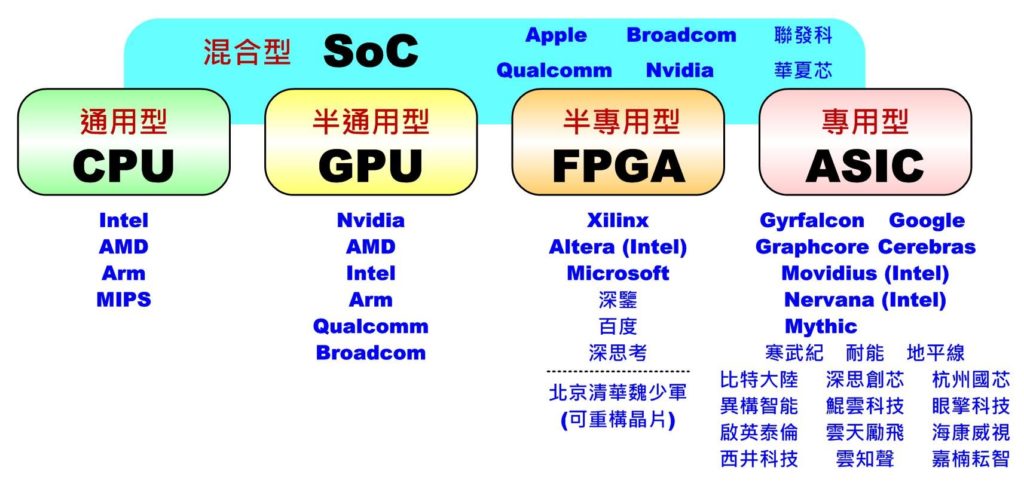
AI 晶片類型(圖片來源:OmniXRI整理製作)
到底要多邊緣才叫邊緣運算?
之前兩大台灣知名網紅「蔡阿嘎」和有超級邊緣人之稱的「HowHow」在挑戰誰才是最邊緣的人[Youtube原始影片],一開始沒講清楚,比完後才開始定義,到底是被認出來就算,還是有被打招呼就算,最後還是以有要求拍照的才算,HowHow才保住「超級邊緣人」的稱號。我想目前市場上所謂的邊緣運算大概也是這種情況,沒有一個標準定義。
從這次參展公司屬性的不同,各自定義的邊緣運算也有極大的算力差異。有的把 GPU 伺服器不上公有雲就算是邊緣運算(私有雲的概念),有的把單板電腦(小型工業電腦、NAS等)加上 GPU 卡算成邊緣運算(個人電腦概念)。而繪圖晶片(GPU)最知名供應商 NVIDIA 也把旗下的 TX2 及 Xavier 這類 SoC(內含多核 CPU+GPU)所組成小型(超)高階單板電腦也稱為邊緣運算。
當然也有一般我們較常聽到用於嵌入式系統(如樹莓派、Arm 等級的開發板)配合 AI 晶片(如 Intel Movidius 等)的邊緣運算。甚至應用於物聯網(IoT)非即時性小型感測器網路的智能邊緣運算的普通單晶片MCU(如 Cortex-M 系列)也可都算是邊緣運算。
綜合以上所述,只要 AI 推論計算部份不上網都可以算是邊緣運算。但個人比較傾向 功率小於 10 瓦(或許小到 1W)、算力小於 1TFlops(或許小到 10GFlop)、可利用行動電源(5V/2A)供電並可放到口袋中(100x100mm)的裝置才算是邊緣運算裝置。
或許有人會問這麼低的算力能作什麼應用,我總喜歡舉例說,要花一小時走路才能到的地方,開法拉利或許很帥氣,但若不趕時間時,騎個 Youbike 不用花什麼錢、也不會花太久就可以到,還可順便運動一下。
但若要到 50 公里遠的地方,那腳踏車可能就不怎麼方便了,此時可能要考慮機車或轎車才較能符合需求。同樣地當人工智慧應用場景明確時,計算量、反應時間、硬體成本就可以較容易估算出來,此時如何選擇適當的邊緣運算平台就顯而易見了。
參展廠商及產品簡介
此次展出「邊緣運算 」相關技術、產品的廠商頗多,無法逐一列出,在此僅能舉幾個代表性的例子來進行說明。
1. 鼎峰智能 — 輕鬆整理你的珍貴回憶

鼎峰成立於 2017 年,三名創辦人分別來自聯發科、博通及高通,團隊十多人分別來自各大 IC 設計公司經驗豐富。目前已獲聯電集團及其它股東投資超過 300 萬美金。2017 年曾獲得「雲谷雲豹育成總決賽」冠軍。
其主要技術利用手機做為計算平台,結合異質資源(SoC 中CPU, GPU, DSP, NPU 等)來加速。主要應用為人臉偵測、識別、分類、物件偵測及視線方向。
此次展出的項目包括:
- 智慧相簿:在本地終端裝置上運行的照片管理應用軟體,讓您更輕鬆地整理、查找及分享您的珍貴回憶。
- 人臉解鎖:高準確度的人臉真實認證,可提高安全性及便捷性,並應用於安防監控、金融授權、智慧家庭、智慧工廠、智慧物流等等。
- 動物辨識:透過影像辨識增加教育互動性,有效增強學習動機並提升教育品質。
- 物件辨識:藉由判斷物件,提昇通路銷售品質、強化廠區安控、亦可應用於教育場景。
(參考資料來源:鼎峰智能官網)
2. 滿拓科技 — 加速物聯網平台

2018 年成立於新竹,團隊來自清大資工。今(2018)年通過科技部亞洲矽谷創新創業鏈結計畫之厚創新 ─ 創意實現平台審查,並獲得 100 萬創業資金及業師輔導。今年受科技部邀約於 InnoVEX 2018 展出。
其主要技術在於提供客製化壓縮技術,在正確率微量減少下,可將訓練好的深度學習模型大幅瘦身,使其能更容易佈署到中低階的硬體(CPU, FPGA, DSP)平台上,尤其是算力不強的物聯網(IoT)平台更是需要。對於高階的硬體(GPU 伺服器)平台則能加快推論速度,是未來不可或缺的技術。
(參考資料來源:滿拓科技官網)
3. 耐能智慧 — 人工智慧晶片

耐能 2015 年成立於美國聖地牙哥,創辦人劉峻誠博士畢業於成功大學,曾在高通、三星、晨星等知名企業服務。A 輪獲得阿里創業基金、中華開發、高通、紅杉資本及其它知名企業大股東投資逾千萬美元,最近(2018/5)又獲得李嘉誠旗下維港投資領投 1800 萬美金。2017 年勇奪「高通創投紅杉資本前沿科技創業大賽」冠軍。
主要開發低功耗人工智慧晶片(神經網路加速晶片)NPU,應用在智慧家居、智慧安防、智慧手機等領域。這是個完整的終端人工智慧硬體解決方案,包含硬體智財(IP)、編譯器(Compiler)以及模型壓縮(Model compression)三大部分,可支援各種主流的卷積神經網路模型及框架。
因為現階段仍以提供 IP 為主要營業項目,雖然(大陸)客戶已有整合型 SoC 投產(流片),但目前還沒有自己獨立專用型的 NPU 上市,所以現場展出仍以 FPGA 模擬的版本,預計今年會有正式獨立產品推出。
(參考資料來源:耐能智慧官網)
4. 灼灼科技 — 普及人工智慧應用

2015 年底成立於台北,創辦人及團隊許多來自台大電機 ICS 影像實驗室,團隊成員精於數據分析、機器學習、嵌入式系統開發、智能圖像辨識等專業領域。2016 年已被全亞洲第一個 AI 加速器 Zeroth.AI 肯定。
為降低人工智慧應用開發門檻,DT42 在 Github 上提供開源系統「BerryNet」,該系統可直接佈署在多種小型嵌入式平台(如樹莓派)上,即可支援多種 AI+IoT 應用(如影像分類、物件偵測、行為偵測、IoT 網關等),另可支援多種加速硬體(如Intel Movidius Neural Compute Stick等)提升 AI 計算性能,不論監控、工業 4.0 或其他物聯產業,都能透過 DT42 的產品來縮短開發時程、降低人工智慧應用的知識門檻、讓人工智慧被加速導入到商品,真正普及人工智慧的應用。
今年 Computex 上更在 Audi Innovation Award 決賽獲得大獎,現場展出的系統僅利用樹莓派加上 Intel Movidius 神經運算棒及「BerryNet」就可進行即時物件偵測,充份體現低成本高性能應用於智慧移動的需求。
(參考資料來源:灼灼科技官網)
5. 威聯通科技 — NAS搖身成為智能管理中樞

2004 年成立台北,為威強工業電腦(IEI)完全持股子公司。提供全面且先進的網路儲存(NAS)與影像監控解決方案。近年跨足物聯網領域,並整合人工智慧(AI)與機器學習 (Machine Learning)技術,使 NAS 進化為智能管理中樞,為人類生活創造更多可能性。
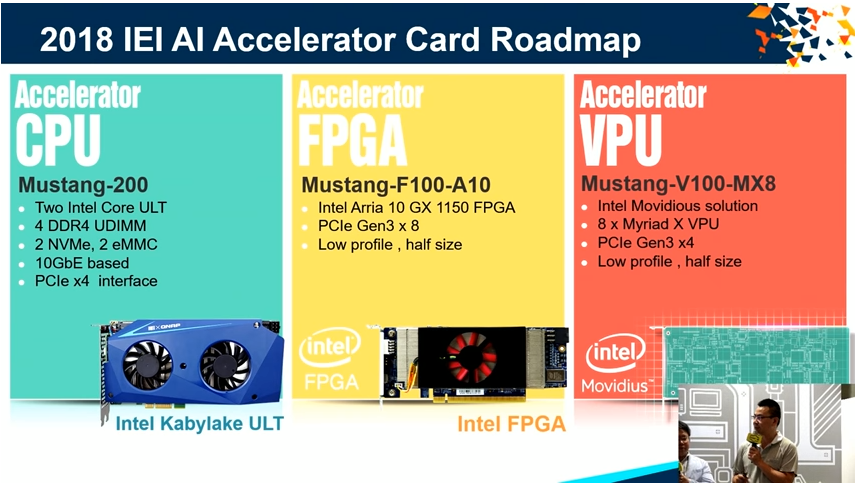
QNAPAI 加速器產品發展圖(圖片來源:QNAP官方Youtube頻道)
本次會展中提出多項以 NAS 為主機的邊緣計算型人工智慧應用產品,產品線齊全從入門到進階,不論是可執行人工訓練段或僅作推論段皆有,其核心計算晶片包括有伺服器等級 CPU(Intel Xeno)、高階繪圖晶片(NVIDIA GPU)、現場可程式邏輯閘陣列(Intel Altera FPGA)及入門級AI加速晶片(Intel Movidius)。
其 NAS 系統支援 Docker,因此很容易佈署 AI 執行框架(如TensorFlow, Keras, Caffe等)及進行推論,另外亦支援 Intel 最新推出的 OpenVINO (Open Visual Inference & Neural Network Optimization Toolkit),使得像 OpenCV 這類的開源電腦視覺函式庫亦能得到加速的效果。更多AI系統如何應用在 QNAP 的產品上,可參考 QNAP官方Youtube頻道。
(參考資料來源:威聯通科技官網)
6. 研揚科技 — 智慧零售好夥伴

成立於 1992 年,2004 年加入華碩集團,主要產品為嵌入式單板電腦、工業級主機板、嵌入式電腦系統、物聯網閘道器產品及相關配件等等。同時也為客戶提供由產品概念發想、研發、量產直到售後服務的一站購足、高度彈性的客製化服務。

研揚科技產品,左為 AI Core,右為 Up Squared。(圖片來源:研揚官網)
研揚科技目前是英特爾物聯網解決方案聯盟的成員,所以此次展出內容主要是以自家的專業創客開發板 Up Squared 搭配 mPCI-E 介面的 AI Core(Intel Movidius 方案),應用於智慧零售的產品識別及人流追蹤。
(參考資料來源:研揚科技官網)
7. 華碩電腦 — 輕鬆享受 AI 的便利

創立於 1989 年,為全球最大的主機板製造商,並躋身全球前三大消費性筆記型電腦品牌。產品除原有個人、筆記型電腦及伺服器等已投身於人工智慧領域,今年特別於 Computex Intel 產品發表會上也推出沒有實體鍵盤的雙觸控螢幕 AI 筆電概念機「Project Precog」。關於硬體規格現場沒有太多揭露,但 CPU 肯定是 Intel 新款低功耗高性的新產品。
其中最特別是竟把 Intel Movidius Vision Processing Unit (VPU)加入設計,個人猜想可能會加入 Movidius 的新款 AI 加速晶片 Myriad X 吧?這樣不僅可免去插一個 USB 神經運算棒,同時更能把 OpenVINO 等開發或執行環境加入系統,令使用者更容易享受 AI 帶來的便利性。

華碩產品 Project Precog。 (圖片來源:華碩官網)
(參考資料來源:華碩電腦官網)
小結
未來「邊緣運算」雖可解決網路巨量通訊、儲存空間、資訊隱私、推論延遲及持續付費等問題,但需有更多解決方案來強化硬體算力(AI 晶片加速)及算法優化(模型減量)。另外整體開發環境(AI 框架、工具包)、設備體積、執行功耗及銷售價格也是影響這項技術是否能普及的重要因素。
相信不久的將來大家就會更加了解如何依自身的場景需求找到雲端及本地端(邊緣)計算的合理配比,而不是全部都在雲端或邊緣端,如此就能讓更多 AI 應用落地。
(責任編輯:周政毅)

主持歐尼克斯實境互動工作室(OmniXRI):http://omnixri.blogspot.com
Edge AI Taiwan邊緣智能交流區:https://www.facebook.com/groups/edgeaitw/
- Arduino UNO Q教學案例整理 - 2026/03/09
- 有了Intel AI Playground 不寫程式也能輕鬆玩生成式AI - 2025/09/02
- 【開發資源】TinyML MCU 等級開源推論引擎 - 2025/06/09
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!



2019/03/26
too profound to understand it