作者:許哲豪
近幾年來人工智慧(Artificial Intelligence, AI)喴的震天價響,吃也要AI,穿也要AI,連上個廁所也要來個AI智能健康分析,生活週遭食衣住行育樂幾乎無處不AI,彷彿已經來到科幻電影中的那個世界,面對這波「智能」新浪潮,身為Maker的我們自然不能缺席。本文將分成上、下兩篇介紹AI晶片的發展,以及Maker們如何使用AI晶片與創作接軌。
AI這個領域看似深不可測,大家都說你得先學個線性代數、機率再加上一堆理論以及看了就頭疼的程式碼,再經過數年修練,就能小有成就。不過,大家請不必擔心,這些難的部份就先交給聰明的資料科學家和工程師,Maker們只要應用他們開發出的源碼及工具(SDK) 發揮創意專心創作出更具「智能化」的作品,解決更多人們的需求即可。
打個比方,「就像學開車不必先懂得車子如何設計,只需到駕訓班學基本原理、操作及交通安全規則就可上路了。」但是,如果你想精進駕駛技術,甚至當個專業賽車手或開發出專屬的車子,這時就必須更了解車子的設計原理,並學著如何改車及用何種方式駕駛,如此才能發揮車子的最大效能。

AI的應用不難,但想精通就得好好修練,就像除了知道怎麼開車以外,還需要知道車子的原理與架構
從開車的例子來舉例:AI晶片就如同引擎,計算能力等同於決定車子的馬力,而算法(模型)就像車型,不同的車型有著不同用途、解決不同的問題,如果開著跑車要載貨而開著貨車要競速,相信一定不會有好的結果。而大量的資料就像汽油,少了它車子肯定動不了。
接下來就從當下最熱門的議題「人工智慧晶片(AI Chip)」來切入,讓大家能更進一步了解AI基本術語及觀念,各家AI晶片技術到底有何不同及Maker們要如何運用這些資源來提升創作使其更智能化。
人工智慧與深度學習
自1950年代「人工智慧」一詞被提出,但受限於硬體計算能力、算法可用性及資料集的數量,幾經浮沈始終未能推出實用的結果。直到2012年Alex Krizhevsky 利用深度卷積神經網路(Deep Convolutional Neural Network, CNN)以大幅差距贏得知名影像分類ILSVRC大賽,大家才重新對人工智慧重燃起希望。
2016年Google的「Alpha Go」完勝最難攻克的圍棋,更是激起各國政府及普羅大眾對人工智慧的重視。聽到「人工智慧」這個名詞,相信大家腦中一定浮現各種科幻電影的場景,想像著電腦已經可以取代人類完成各種需要大量思考才能完成的事,但現實上並非如此。

2016年 Alphago 圍棋競賽
目前市面上說的人工智慧,大多是指深度學習(Deep Learning, DL)算法所產生的結果,其實只是在找一個最佳函數解,而非真正具有像人的思考方式。
更進一步來說,如下圖所示(Fig. 1),人工智慧包含了機器學習(Machine Learning, ML),而其下又包含了有標準答案才能學習(訓練)的監督式(Supervised)學習(分類、迴歸),沒有標準答案可自動依資料屬性分群的非監督(Unsupervised)式學習(聚類)及具獎懲機制找出最佳答案的增強式(Reforcement)學習(分類)。
深度學習只是由監督式學習下的神經網路(Neural Network, NN)所演化出來的,經過這幾年不斷的演化,目前已從只能處理監督式學習問題擴展到非監督式及增強式學習。因此,目前市售的AI晶片發展趨勢多半鎖定在處理深度學習類型問題,而非處理傳統機器學習及真正人工智慧的問題。
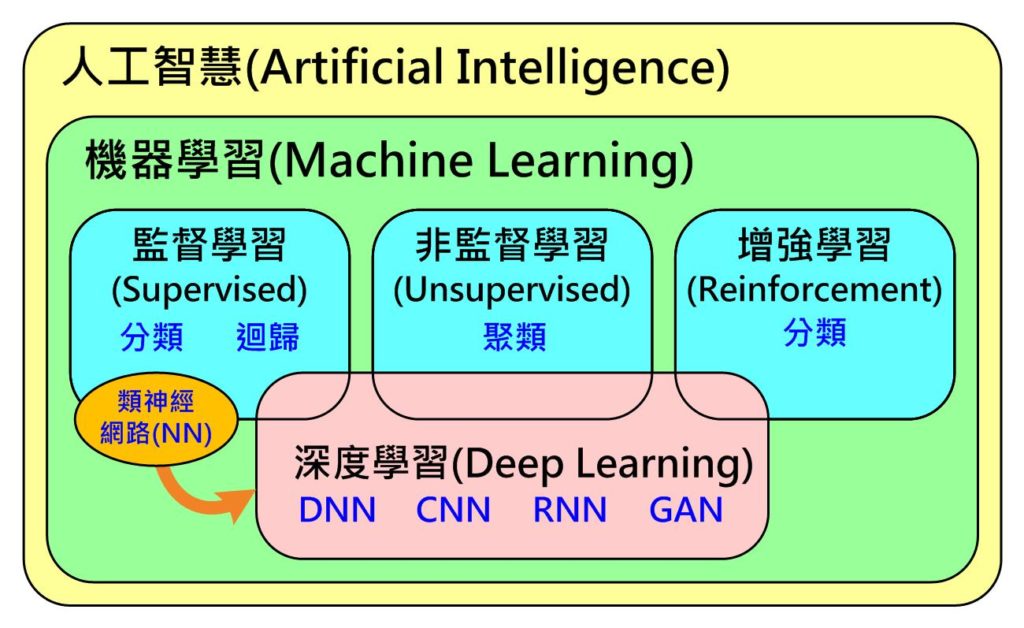
Fig. 1 人工智慧、機器學習與深度學習關係 (圖片來源:OmniXRI整理繪製)
深度學習技術的應用
目前應用人工智慧或者更精準地說,深度學習到底能解決什麼問題呢?最常見的兩大領域就是影像及語音
在影像方面,可對單張影像進行單一項目分類( Fig. 2a),但若影像中,同時出現二種類型物件時,那就很有可能分類錯誤或者同時歸屬到多個類別中。再來,可找出影像中多個物件並定位出來( Fig. 2b)。
若想要再更精準描繪出物件輪廓就必須進行語義分割(Fig. 2c),換句話說就是以像素等級的方式進行分類,把每個像素分到指定的分類中,此時仍無法區分出相同物件不同個體。最高等級就是實例分割(Fig.2 d),不僅能精準分割物件輪廓且能分割出不同個體。當然,這四類型的難度也是依序提高,所需付出的計算量也相對提高。

Fig. 2 常見影像應用人工智慧使用情境 (圖片來源:OmniXRI整理繪製)
另一個較大應用的領域就是「語音」,首先要讓電腦聽懂我們在說什麼,就必須正確地把語音變成文字(Fig. 3e),才能提供給後續的語言(意圖)解讀(Fig. 3g)。當然要聽懂是誰在說話,而說話的情緒為何也是很重要的(Fig. 3f),在了解說話的內容後就必須產生回答,把通順的句子合成為柔美的語音(Fig. 3h),才能完成一個完整的對話過程,不然就變成雞同鴨講。
除此之外,如文章翻譯、影片摘要、股市分析、交通物流、醫療照護等,非影音領域的應用也都很適合以深度學習方式進行辨識及分析。
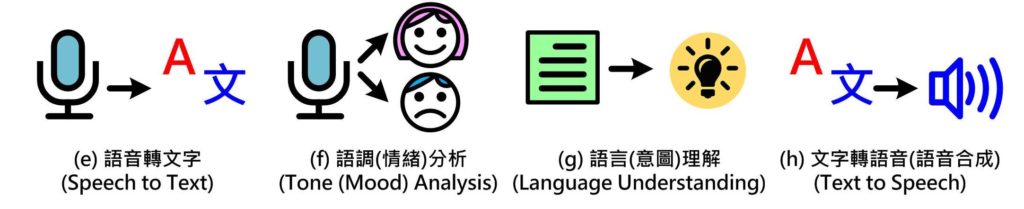
Fig. 3 常見語音應用人工智慧使用情境 (圖片來源:OmniXRI整理繪製)
AI晶片的神經網路(NN)工作原理
為了能更進一步了解以深度學習為主的AI晶片到底要如何工作,首先要了解組成「神經網路(NN)」神經元的工作原理。
如下圖(Fig. 4a)所示,每個神經元有n個輸入值,每個輸入值有一個權重(Weight)值,把所有輸入值乘權重值加總起來,有時會另外加上一個偏置值(Bias)來調整,將得到的值再經過一個激活函數(Activation function)即可產生新的輸出值。從另一個角度來看,相當於每個權重值決定對應的輸入值對這個神經元的影響程度。
以Fig. 4a為例,由左至右為推論(Inference),可得到算輸出結果,過程中需要n個權重值加上1個偏置值,而這些值是需要經由訓練(Training)而得。訓練前須取得許多(越多越好)已知答案或稱為標籤(Label)的訓練資料,假設輸出值只有二種答案,是(1.0)或者不是(0.0)。
如果第一組輸入資料已知答案為是(1.0),但經過推論後只得到0.6,則表示權重及偏置值不理想需要調整,此時利用根據差值(1.0 – 0.6 = 0.4)由右至左調整每個權重及偏置值,而至於調多少則隨不同方式也有不同。
同樣的步驟再輸入第二組資料進行調整,直到所有訓練資料都做過一輪(Epoch)。此時,大家可能會問這樣就訓練好了嗎?我們還得拿出另一組未曾出現在訓練資料中,但卻已知答案的資料來進行驗證,就如同學校老師教了許多內容,但要透過考試成績才能知道學生是否學會了,如果分數不及格,就要重新訓練加強磨練。
相同地,我們必須反覆執行這些步驟直到驗證資料都得到滿意的答案,因此,可想而知所需來回的次數相當大,所以通常訓練會需要設計什麼時候停止,可選擇成績(正確率)到達某個門檻,或者不管成績只考慮訓練次數。這就好比學校的模擬考,雖然學生每次都考高分,但真正考試時成績仍不理想,此時就得增加學習樣本重新訓練。
為了能處理更複雜的問題,一個神經元可擴展成一組簡單(單層)神經網路,如Fig. 4b所示,會有輸入層、隱藏層(Hidden Layer)及輸出層,推論及訓練的概念和一個神經元大致相同。若待解決問題更困難,如Fig. 4c所示,則可增加每一層的神經元或隱藏層數來解決。
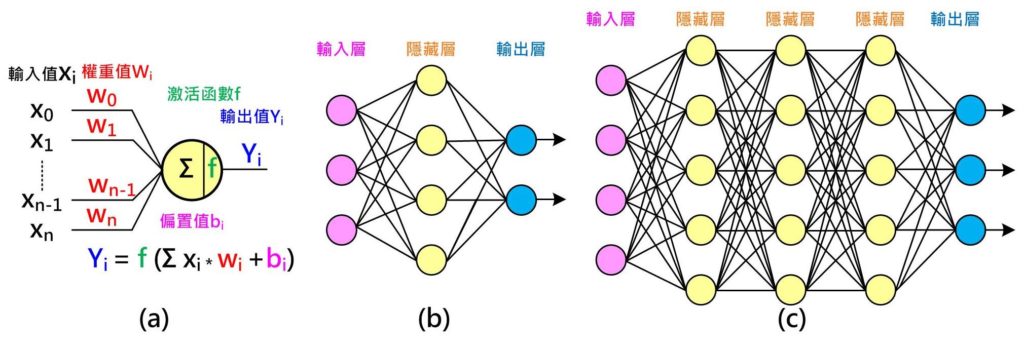
Fig. 4 神經網路:(a)神經元工作原理;(b)簡單(單層)神經網路;(c)複雜(深層)神經網路 (圖片來源:OmniXRI整理繪製)
深度學習的代表作 – 卷積神經網路(CNN)
不過,問題來了,當輸入的資料為影像時,隨便一張32*32的單色灰階影像,就有高達1024個輸入;若是彩色影像還要乘以三倍(R,G,B),如此龐大的網路,參數(權重、偏重值)數量實在多到難以計算。於是深度學習的代表作「卷積神經網路(CNN)」因此誕生了。
如 Fig. 5 所示,這是一個用來辨識手寫數字(0~9)的案例(模型),稱為「LeNet」,輸入為32*32點單色灰階影像,輸出為0~9的機率。其中應用到一種名稱「卷積」或「迴旋積」的技巧,它讓權重值可以共用,在 Fig. 5中顯示的 C1層就是由六組 5*5的卷積核計算後的結果,則只需156((5*5+1)*6)個參數就夠了。當輸入點數降低到夠少點數時再採用全連結(Full Connection)方式(如上圖Fig. 4a, 4b),Fig. 5中的F6層。不過即便是如此,LeNet整個完整網路仍有六萬個參數需要進行訓練。
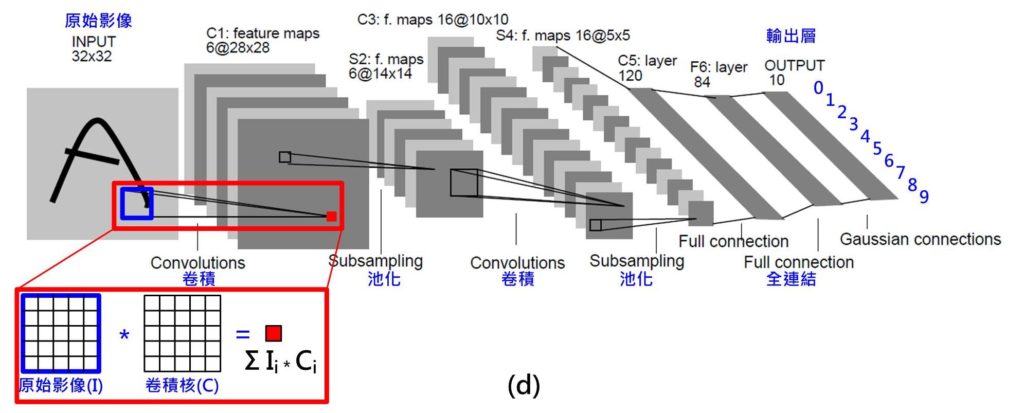
Fig. 5 神經網路:卷積神經網路(CNN, LeNet) (圖片來源:OmniXRI整理繪製)
為了解決各種不同問題,於是各種不同的網路(Net)結構或模型(Model)被提出。從Fig. 6 中可看出,橫軸是計算量,每個乘法或加法就算一次運算(Operations, Ops),不同算法從數千萬次到數百億次的計算才能推論一筆資料,通常計算量和參數量(圓圈直徑)有直接關係,參數量可能從數百萬到數億個。不過正確率和參數量及計算量則不一定有直接關連,對實際使用上來說當然希望找到計算量越低、正確率越高的模型,而正是AI科學家及工程師努力的方向。
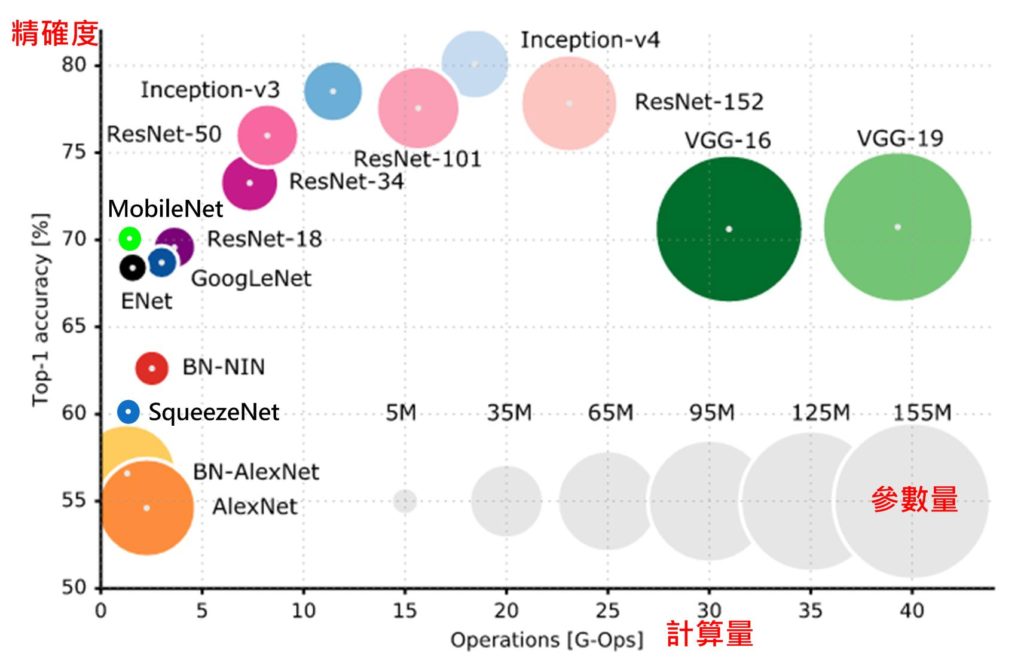
Fig. 6 影像分類之神經網路之參數量、計算量及精確度比較圖(圖片來源)
對Maker而言只需根據需求(正確率、計算量)及計算時間找到一個夠用的的模型及硬體平台(AI晶片)來用即可,就像只有幾個紙箱的東西要搬,不必找一台貨櫃車或一台千萬跑車來載。反之應用上若很在意正確率,則可能就要多浪費一些計算量(時間)及昂貴的硬體平台來換。
小結
由上述內容可知雖然運用深度學習神經網路可得到較理想的辨識結果,但所需付出的代價也同樣非常驚人,光推論一筆資料就要計算數千萬次到數百億次,更不要說訓練時要訓練數萬到數百萬筆資料,數十到數千次循環週期(Epoch),所以如何加速訓練及推論時間就成了最重要的工作。
為了完成這麼龐大的工作,就必須有強悍運算能力的硬體平台。下一篇我們將繼續介紹目前市面上的各類AI晶片,也會針對不同類型的晶片進行分析。
(本文同步發表於歐尼克斯實境互動工作室(OmniXRI);責任編輯:葉于甄。)

主持歐尼克斯實境互動工作室(OmniXRI):http://omnixri.blogspot.com
Edge AI Taiwan邊緣智能交流區:https://www.facebook.com/groups/edgeaitw/
- 【Arduino UNO Q專欄05】家庭氣象站 - 2026/07/07
- 【Arduino UNO Q專欄04】人臉偵測開關燈具 - 2026/06/22
- 【Arduino UNO Q專欄03】板載點矩陣LED應用 - 2026/06/08
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!



2018/06/06
讚!