
作者:Louis
開始這篇主題時,要先感謝公司的同事祐鑫與博堯。身為公司主管的我總是一聲令下請他們去做一些從沒有做過的研究與開發,而他們也總是非常敬業的配合,到現在還可以慢慢發展出更多的應用出來。原本打算在瀏覽器上面使用OpenCV.js去完成道路偵測的演算目標,這只是我們幾年前就已經達到的目標,但我們還想要玩到更多,採更大的雷… 這時候有一個更貪婪的想法:
『如果可以直接用OpenCV去達到影像處理、辨識、甚至是AI推論,像是影像識別或是物件偵測,是否真的可行? 甚至直接在瀏覽器上面跑……』
我知道現在的讀者都不太可能耐著性子去看完所有文章,因此先做個結論,讓讀者有個底。有需要了解細節的讀者朋友,可以再繼續接著往下看:
目前測試過以下方式呼叫OpenCV的Lib,所得到的結果:
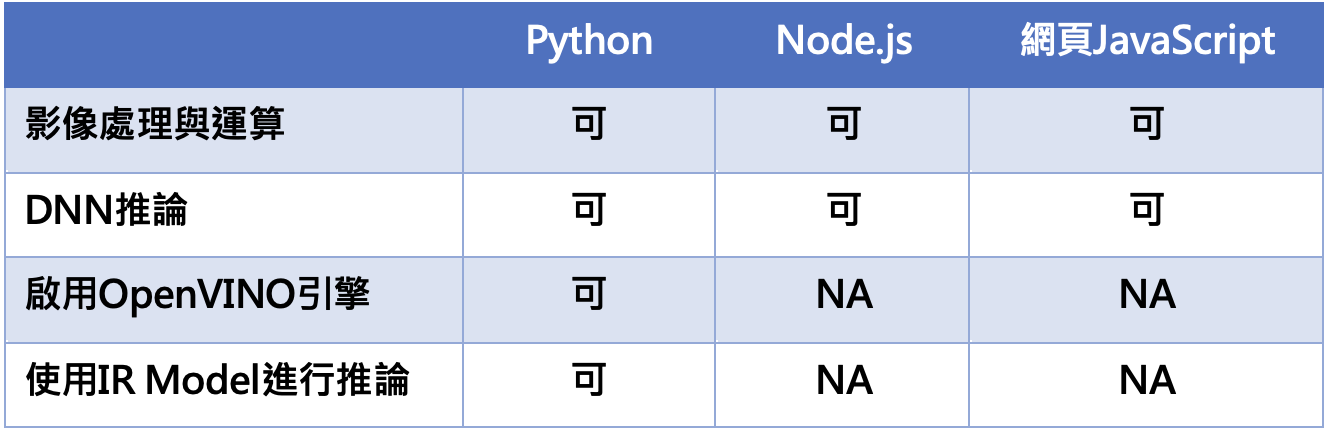
不同方式呼叫OpenCV的Lib所得到的結果
本表的背景簡單說明如下:
- 這個表是基於安裝OpenVINO 2021年版本後測試的結果。
- 本表格紀錄2021年12月的測試成果,我想過不久會有更多的改變。
- 透過OpenVINO套件安裝的OpenCV已經有包含了DNN相關推論套件,只是引入相關檔案就可以使用。而在Python環境下,可以成功的呼叫設定函式,啟用OpenVINO的推論環境。
- 預設Github下載的OpenCV.js版本沒有加入引用OpenVINO的設定相關functions,可以自行將OpenCV原始檔案下載重新編譯產生自訂的OpenCV.js,雖然可以呼叫但是回出現錯誤。有需要在Node.js使用OpenVINO與IR model進行推論的朋友,可以下載Intel所提供的inference-engine-node (https://github.com/intel/inference-engine-node ) 。目前經過安裝測試,是沒有問題的。
- 預設Github下載的OpenCV.js版本沒有加入引用OpenVINO的設定相關functions,可以自行將OpenCV原始檔案下載重新編譯產生自訂的OpenCV.js, 雖然可以呼叫但是回出現錯誤。Intel所提供的inference-engine-node如果經過適當的修改源碼,我想應該可以做到與Node.js一樣的結果。如果真的想要在網頁上使用IR model進行推論,可以參考另外一個Intel不再維護的專案。
以上的結論僅是目前為止得到的結論,隨著時間一定會有新的變化,我們就先拭目以待。這篇文章並不是到這邊就結束了,畢竟要撰寫一篇對讀者有用的文章,一定要有點內容才行。以下針對第3點的部分將目前研究的提供給讀者參考:
- 在網頁上進行OpenCV進行影像處理與演算,達到道路偵測的目標。
- 在Python使用OpenCV並開啟OpenVINO環境進行IR推論。
- 針對Node.js無法使用OpenCV去開啟IR Model去進行推論,提供另外一個解決方案 – inference-engine-node的測試與使用。
一、在網頁上用OpenCV進行影像處理
自己的公司從上架免費的V7RC到現在已經有好幾年了。相信很多對我們關注的朋友都知道。V7RC裡面有用OpenCV在道路辨識的應用上,讓遙控車可以在操場上進行自駕。我們為了追求最好的效能與移植性,使用C++當作開發語言,跟目前大家用Python作為開發語言有非常大的差異,但就應用在Android與iOS上面的成果來說,效能的確是比Python好很多。
以公司的政策來說,我們在商業上的應用是傾向於不使用Python,原因在於效能問題的考量。未來隨著CPU不斷地更迭,我相信這個問題始終會被克服。因此我們以Node.js 作為另外一個主要開發語言,而我們在OpenCV這個主題上面選擇以瀏覽器來挑戰其應用的可能性。
既然要測試,當然就拿出當年我們進行道路偵測的演算法來實作,是最有感覺的。最早,我們以Python參考道路偵測的演算法(參考網址)。
截至目前,已經有更多人分享道路辨識的演算方式,也將其優化,我相信只要有心可以找到更多的相關文章。 台灣也有人分享 (辨識出在路上的道路標線), 都是大同小異的版本可以參考。 這篇文章主要是專注在使用Javascript去實作OpenCV,所以我們不特別說明道路偵測的演算。
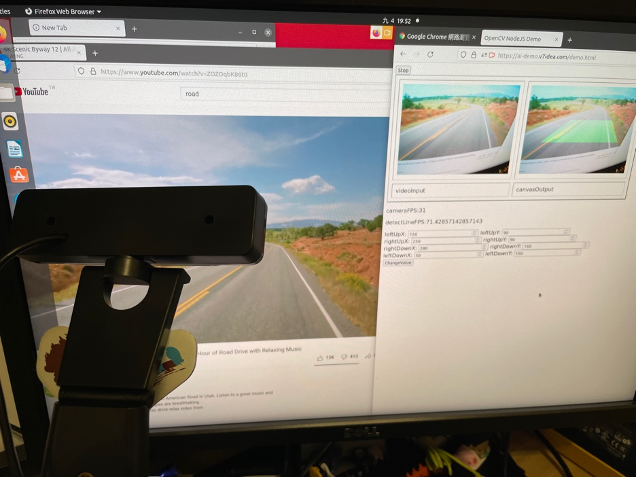
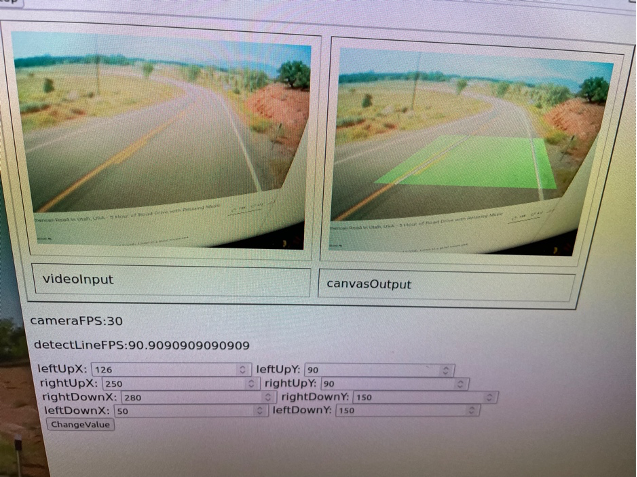
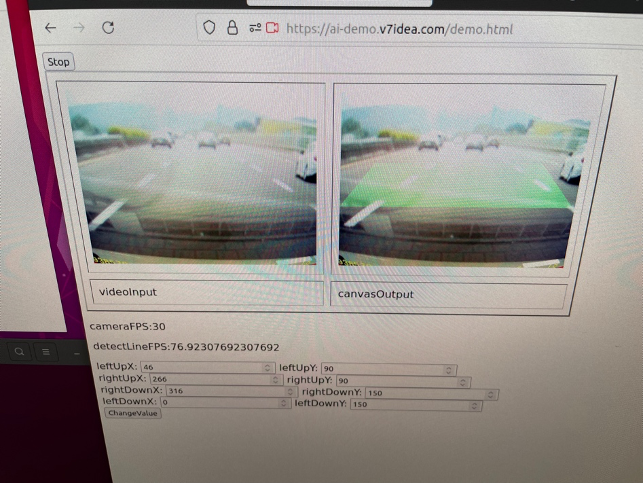
還沒有開始說明之前,可以先看一下實際完成的作品,可以給大家參考。我也將測試影片上傳到YouTube,可以從實際的影片中看到道路辨識的效果,真的挺好的:
好的,進入主題,講解如何進行實作。
(一) 整體UI架構與設計:
A. 有一個顯示Webcam輸入的顯示框(下圖左方的顯示框)。
B. 有一個可以顯示辨識結果的顯示框 (下圖右邊的顯示框)。
C. 簡單的數值設定畫面上的道路偵測區域。
D. 增加一個開始/結束的按鈕,按下後可以啟動Web Camera。
E. 顯示每秒鐘輸入的畫面張數,以及辨識的效能。
(二) html檔案的配置:
在html的物件配置上,我們使用了一個video的物件,當作顯示Web Camera的顯示窗。而另外一個canvas的物件,當作OpenCV辨識後的顯示結果,使用OpenCV進行渲染後,將我們的偵測區域與偵測到的線繪製成一張圖後,顯示到canvas上面。
程式執行的流程也相當的容易理解,步驟如下:
A. 使用按鈕開始Web Camera或是關閉Web Camera
B. 開啟Camera後,依照以下的流程進行辨識:
- 讀取Web Camera的畫面。
- 使用OpenCV進行圖形運算。
- 將運算的結果使用OpenCV繪製偵測區域,與抓到的邊緣線段,呈現到右邊的顯示區域。
html程式說明:
A. 引入opencv.js也相當簡單,可以到 Github去下載。opencv.js被包在opencv-{版本號}-docs.zip壓縮檔案中,例如使用4.5.3版本時,可以在頁面上找到opencv-4.5.3-docs.zip 。
下載檔案後,放到要撰寫的html檔案位置,並且在html檔案的head 標籤區域,加上
下載檔案後,放到要撰寫的html檔案位置,並且在html檔案的head 標籤區域,加上
這樣就可以引入opencv.js檔案了。因為opencv.js檔案不小,建議可以使用非同步載入的方式,當載入完成後,可以使用callback function設計一個提醒用戶完成載入的資訊(注意:如果未完成載入,將無法正確執行)
B. 另外,針對引入Web Camera並且順利擷取畫面,需要引入另外一個js檔案:
C. 在畫面上的open按鈕,是開啟或是關閉Web Camera, 按下時將會觸發cameraTrigger()的function:
D. cameraTrigger function的內容如下:
if (isCameraOpen) {
closeDeviceCamera();
isStartDetectCameraFPS();
isStartDetectLineFPS();
} else {
openDeviceCamera(processVideo);
}
}
實際觸發打開Web Camera是使用 openDeviceCamera(processVideo) function,我們設定processVideo是帶入處理影像的call back function:
if (isCameraOpen == false) {
//{ video: true, audio: false }
navigator.mediaDevices.getUserMedia({ video: { width: { exact: 320 }, height: { exact: 240 } } }).then(function (stream) {
isCameraOpen = true;
let tracks = stream.getVideoTracks();
console.log('Using stream device: ' + stream);
console.log('Using tracks device: ' + tracks);
video.srcObject = stream;
isStartDetectCameraFPS();
isStartDetectLineFPS();
video.play();
callBack(); // 執行 我們設定的call back function
startAndStop.innerText = 'Stop';
}).catch(function (err) {
console.log("An error occurred! " + err);
alert(err);
});
}
}
E. 實際上OpenCV處理的流程都放在 processVideo裏面,而每次執行processVideo function時,都會先啟始化參數,我們放在initParameters function中,也包含了設定好抓取影像的物件等:
if (isinital == false) {
if (src == null) {
src = new cv.Mat(video.height, video.width, cv.CV_8UC4); // 透過opencv,將擷取到的影像轉成矩陣。
}
if (dst == null) {
dst = new cv.Mat();
}
if (rgbMat == null) {
rgbMat = new cv.Mat();
}
if (hsvMat == null) {
hsvMat = new cv.Mat();
}
if (maskInverseMat == null) {
maskInverseMat = new cv.Mat();
}
if (grayMat == null) {
grayMat = new cv.Mat();
}
if (masked_replace_white == null) {
masked_replace_white = new cv.Mat();
}
if (gaussianBlurMat == null) {
gaussianBlurMat = new cv.Mat()
}
if (ksize == null) {
ksize = new cv.Size(gausianKernelValue, gausianKernelValue)
}
if (toGrayScaleMat == null) {
toGrayScaleMat = new cv.Mat();
}
if (cannyMat == null) {
cannyMat = new cv.Mat();
}
if (cannyOutPutMat == null) {
cannyOutPutMat = new cv.Mat();
}
if (maskPolyColor == null) {
maskPolyColor = new cv.Scalar(255);
}
if (square_points == null) {
square_points = cv.matFromArray(square_point_data.length / 2, 1, cv.CV_32SC2, square_point_data);
}
if (pts == null) {
pts = new cv.MatVector();
}
if (emptyMat == null) {
emptyMat = new cv.Mat()
}
if (lineColor == null) {
lineColor = new cv.Scalar(0, 0, 255);
}
if (cap == null && video != null) {
cap = new cv.VideoCapture(video); // 抓取影像的物件
}
isinital = true;
}
}
processVideo function 中最重要的部分就是進行關於道路辨識的演算,未來有需要可以再依照自己的需求改為辨識其他的特徵,甚至於應用AI辨識,道路辨識演算法就不在此進行解釋了(可以參考之前提供的範例)。將結果繪製到Canvas的物件中,也包含在processVideo裏面:
………….
let roiImage = new cv.Mat.zeros(src.rows, src.cols, src.type());
cv.fillPoly(roiImage, pts, new cv.Scalar(0, 72, 0, 30)); // 充填多邊形
let output = new cv.Mat();
cv.addWeighted(src, 1, roiImage, 1, 0, output); // 融合兩張圖片
roiImage.delete();
……..
try {
cv.imshow('videoOutput', output); // 將圖片輸出到 id為videoOutput的Canvas物件中...
output.delete();
src.delete();
src = null;
} catch (error) {
console.log("cv imShow Error: " + error)
output.delete();
src.delete();
src = null;
}
}
二、用Python呼叫OpenCV並開啟OpenVINO環境進行IR推論
使用Python語言去呼叫OpenCV lib進行AI推論,真的很簡單。網路上也很容易找到相關文章,以下僅針對簡單的測試步驟,分享給讀者。我們將以臉部偵測的model(face-detection-adas-0001 )作為範例說明如何使用OpenCV去進行推論,並且使用Intel的IR model。
前期準備:
- 安裝OpenVINO套件
- Python3
- 推論的model,這次我們使用face-detections-adas-0001.xml作為測試的樣本。
範例程式下載裡面的子目錄/OpenCVPython就是本文章說明的範例。
使用OpenCV進行DNN推論十分的簡單,短短幾十行的命令就可以完成:
步驟1:引入opencv lib
步驟2:設定使用的model檔案,並且設定intel reference engine當作推論用的引擎:
net.setPreferableBackend(cv.dnn.DNN_BACKEND_INFERENCE_ENGINE) #設定後端平台為intel inference engine
net.setPreferableTarget(cv.dnn.DNN_TARGET_CPU)
步驟3:讀取檔案並且進行推論:
blob = cv.dnn.blobFromImage(frame, size=(672, 384), ddepth=cv.CV_8U)
net.setInput(blob)
out = net.forward()
步驟4:整理結果並繪製在圖像後進行儲存:
confidence = float(detection[2])
xmin = int(detection[3] * frame.shape[1])
ymin = int(detection[4] * frame.shape[0])
xmax = int(detection[5] * frame.shape[1])
ymax = int(detection[6] * frame.shape[0])
if confidence > 0.5:
cv.rectangle(frame, (xmin, ymin), (xmax, ymax), color=(0, 255, 0))
Save the frame to an image file:
Create a date_string variable with the format
date_string = time.strftime(“%Y-%m-%d-%H:%M:%S”)
create imageName variable that takes adds the date_string to the output file name
imageName = ‘test’ + date_string +’.png’
output with name and frame
cv.imwrite( imageName, frame )
以上簡單幾行就完成了。在測試的過程中發現有幾個狀況需要分享,因為網路上的model檔案很多,並不是所有model都可以成功地進行推論,原因在與IR轉換的格式不再支援,所以就會出錯。錯誤命令的關鍵字就是 The support of IR v6 has been removed from the product. 建議避免這樣的狀況,儘量使用自己目前安裝的OpenVINO套件目錄中的downloader.py 去下載想要使用的model,為了後續使用,我直接下載所有的model:
python3 /opt/intel/openvino_2021/deployment_tools/tools/model_downloader/downloader.py --all --precisions FP16
執行Python的命令很簡單,只要執行
python3 face.py
以上的推論流程,可以應用在OpenCV.js檔案,也可以直接在OpenCV.js去進行撰寫,不過遺憾的是目前仍無法使用IR model進行推論,後續會繼續追蹤最新狀況,發表在我們的git。
三、針對Node.js無法使用OpenCV去開啟IR Model去進行推論,提供另外一個解決方案 – inference-engine-node的測試與使用
為了彌補無法使用OpenCV.js去載入Intel IR model進行推論的遺憾,Intel自己有一個Node.js 版本的inference-engine-node,可以透過github取得。
這個版本需要在本機端進行安裝,開始前先確認電腦環境是符合需求的:
- Node.js 12 LTS
- OpenVINO 2021.4
Node.js版本如果不符合,有可能會導致安裝失敗,因此先在cmd環境使用以下命令確認:
node -v
步驟1:透過git複製版控到本地端,方法是:
git clone https://github.com/intel/inference-engine-node
步驟2:複製完之後,請進入到程式碼的目錄內:
cd inference-engine-node
步驟3:進行安裝:
npm install
附註:
如果是在Windows環境下安裝,請先確認有啟用OpenVINO toolkit的設定環境,呼叫以下的script就可以啟用(安裝路徑可能有所不同,請自行更動):
C:\Program Files (x86)\IntelSWTools\openvino\bin\setupvars.bat
步驟4:執行npm建置
npm build
這時應該可以看倒npm執行編譯與安裝的程序,完成後在lib的目錄下就可以看到inference-engine-node.js 這時已經編譯成功了。
步驟5:執行npm 測試
npm test
這時可以看到測試每個功能的結果,看到的輸出應該會像以下這樣:
這樣表示已經安裝成功。接著,趕快來試試範例程式。我們以原始檔案目錄下的example/hello_object_detection_ssd_node 目錄為例子,進行物件偵測的辨識。以下是安裝與執行步驟:
請先進入example/hello_object_detection_ssd_node目錄中
步驟1:安裝:
npm install
步驟2:確認安裝結果,可以鍵入以下指令取得輔助說明:
node main.js --help
步驟3:執行測試:
使用一個圖檔進行物件辨識的測試,使用以下命令:
node main.js -m ~/inference-engine-node/models/mobilenetssd/FP16/mobilenetssd.xml -i test.jpg -d CPU -n 10
正確執行將會顯示推論的結果:
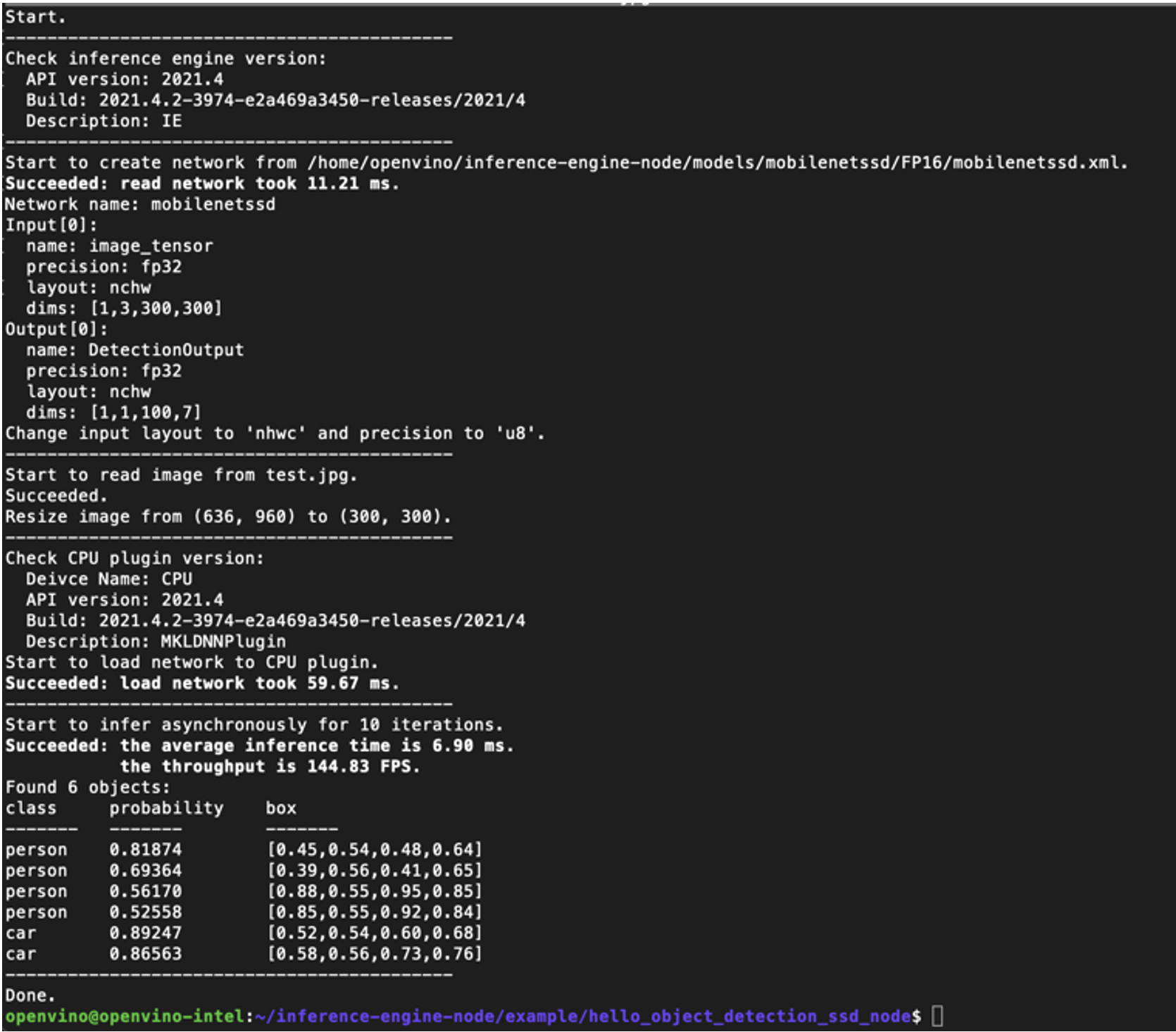
這個時候,就已經可以拿編譯好的lib應用在自己的程式碼上了。
小結
以上的三個小單元,先不提直接在瀏覽器上呼叫OpenCV.js進行影像處理的魅力,而進一步了解在瀏覽器上是否可以應用Intel的OpenVINO的Inference Engine套件,並以IR model檔案去進行AI推論,這樣可以使用一個lib整合相關功能,將是很方便的事。
雖然OpenCV.js尚不支援IR model的檔案,而目前也無法設定inference-engine當作推論引擎(個人評估應該是瀏覽器本身的架構限制,或是部分源碼仍在開發中。Node.js執行結果目前也是如此),不久的未來我想應該為慢慢克服。
藉由同步了解Python應用OpenCV去進行IR model推論的方便性,並且使用OpenVINO本身的環境提升效能,更可以期待未來Node.js的語言如同Python,可以執行IR model與應用OpenVINO的推論環境。
附加說明,在Python環境下使用像是TensorFlow或是ONNX的model檔案,一樣可以設定inference-engine作為DNN演算的背景處理。就算不使用IR model,一樣可以提升效能。
(責任編輯:謝涵如)

- 當OpenCV遇上OpenVINO:如何使用IR model進行推論? - 2021/12/13
- 【OpenVINO專欄】用DL Workbench輕鬆完成AI模型的分析與部署工作 - 2021/07/31
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!

