作者: Fidel Makatia
本文將帶領讀者了解如何透過Raspberry Pi 5與基於Arm的本地端LLM推論,打造一個完全私有、無需依賴雲端、且具備即時效能的智慧家庭助理。
問題在於:智慧家庭高度依賴雲端,而且代價不小
多數智慧家庭助理均仰賴雲端AI,即使是開燈、調整恆溫器或查看能源使用量這類簡單任務也不例外。這不僅帶來隱私風險,也會造成延遲,甚至讓你家在網路中斷時變得脆弱。
在一個逐漸走向重視隱私與自主性的世界中,挑戰已經十分明確:我們能否運用像Raspberry Pi 5這樣價格親民的硬體,將真正的智慧帶入智慧家庭中——也就是可在本地端高效運作,同時兼顧隱私保護?
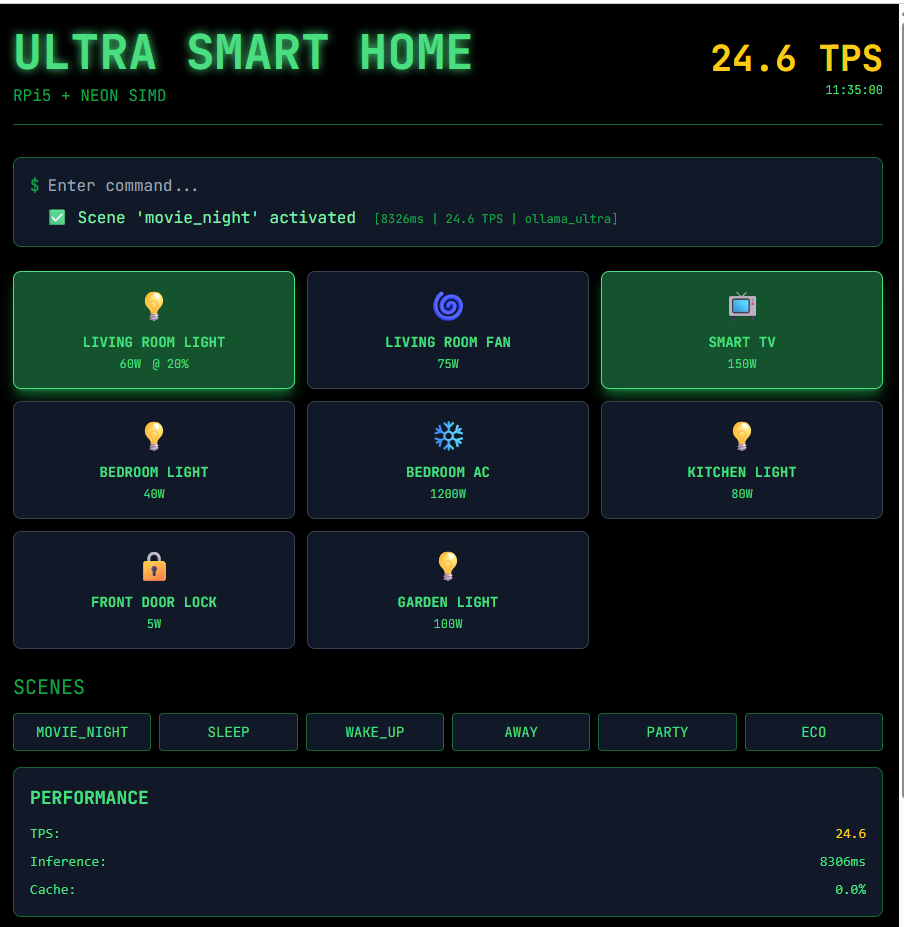
圖1:運作「千問」時的使用者介面
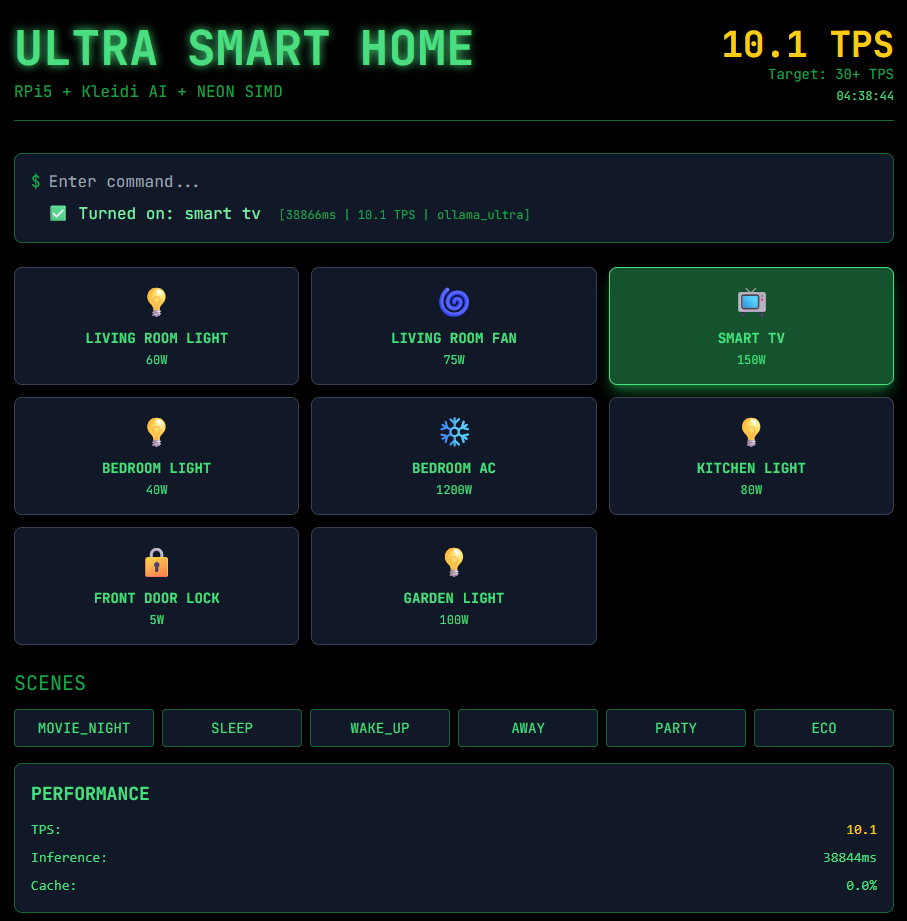
圖2:運作DeepSeek時的使用者介面
為什麼這很重要:隱私、可靠性,以及人人可及的邊緣AI
對數以百萬計的使用者而言,特別是那些處在網路不穩定或連線成本高昂的族群,仰賴雲端的智慧家庭只有在網路正常時才稱得上「智慧」。即使是在網路條件良好的家庭中,隱私問題也逐漸成為人們關切的重點。Raspberry Pi 5採用64位元Arm處理器,帶來顯著的效能躍升。
搭配高效率的LLM,如今已能在本地端執行先進的AI,兼顧完整的隱私保護與即時回應。這個專案證明了:強大而私有的AI,現在已能在價格親民、且易於取得的硬體上實現。
解決方案:在Raspberry Pi 5上打造私有、具對話能力的智慧家庭AI
這款以開放原始碼打造、以隱私為優先的智慧家庭助理,展示了大型語言模型如今已能完全在基於Arm的裝置上於本地端運作。它透過Ollama與LLM來實現自然語言指令與家庭自動化,全程不依賴雲端。當沒有雲端,也就無需妥協。
關鍵實作步驟

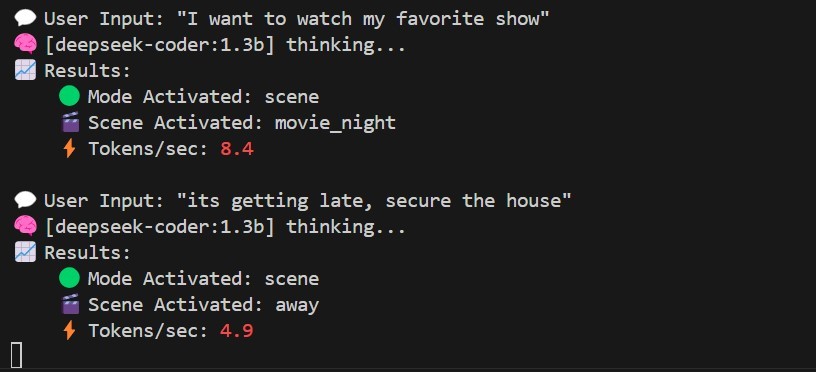
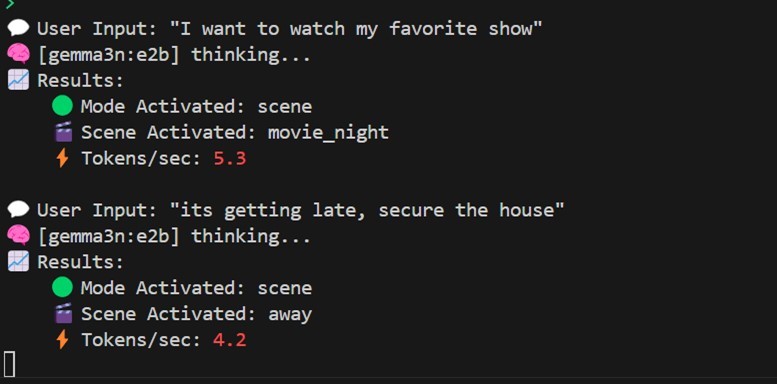
- Ollama LLM後端:所有自然語言處理(NLP)皆在裝置端透過Ollama執行,支援DeepSeek、TinyLlama、Qwen、Gemma等模型。模型可在本地端下載並執行,完全不需要任何外部API。
- 為Arm架構最佳化:系統針對Raspberry Pi 5的四核心64位元Arm Cortex-A76處理器進行調校。Arm架構在效能功耗比上的優勢,以及強大的NEON引擎,對於加速LLM推論所需的複雜數學運算相當重要,讓Pi 5能以更低延遲,執行比前一代更大型的模型。
- 直接裝置控制:支援GPIO、MQTT與Zigbee,可直接與燈具、風扇、插座、感測器等各類硬體整合。
- 網頁儀表板與API:提供簡潔的使用者介面與REST API,方便控制與監控,同時也提供命令列介面(CLI)以滿足進階使用者需求。
- 即時效能指標:可監測 LLM 執行速度(tokens/sec)、指令延遲、功耗與快取命中率,確保系統具備完整的透明度,並便於效能調校。
硬體配置

圖3:硬體配置
- Raspberry Pi 5(建議 8GB 或 16GB):這款單板電腦配備四核心Arm Cortex-A76 CPU,每個核心最高可達2.4GHz。Arm核心支援NEON SIMD(單指令多資料)延伸指令集,可進行高效率的平行處理,特別適合需要大量運算的應用情境。
- Raspberry Pi OS 64 位元版(或 Ubuntu 22.04 ARM64)。
- MicroSD或 NVMe儲存裝置。
- 網際網路連線:僅於初始設定時需要,部署完成後即可離線運作。
- GPIO 裝置:透過 GPIO/MQTT/Zigbee 連接的燈具、感測器等。
- 完整設定與操作說明請參考GitHub:https://github.com/fidel-makatia/EdgeAI_Raspi5/tree/main.
系統架構
該系統從指令到執行動作,採用全程在本地端運作的工作流程。
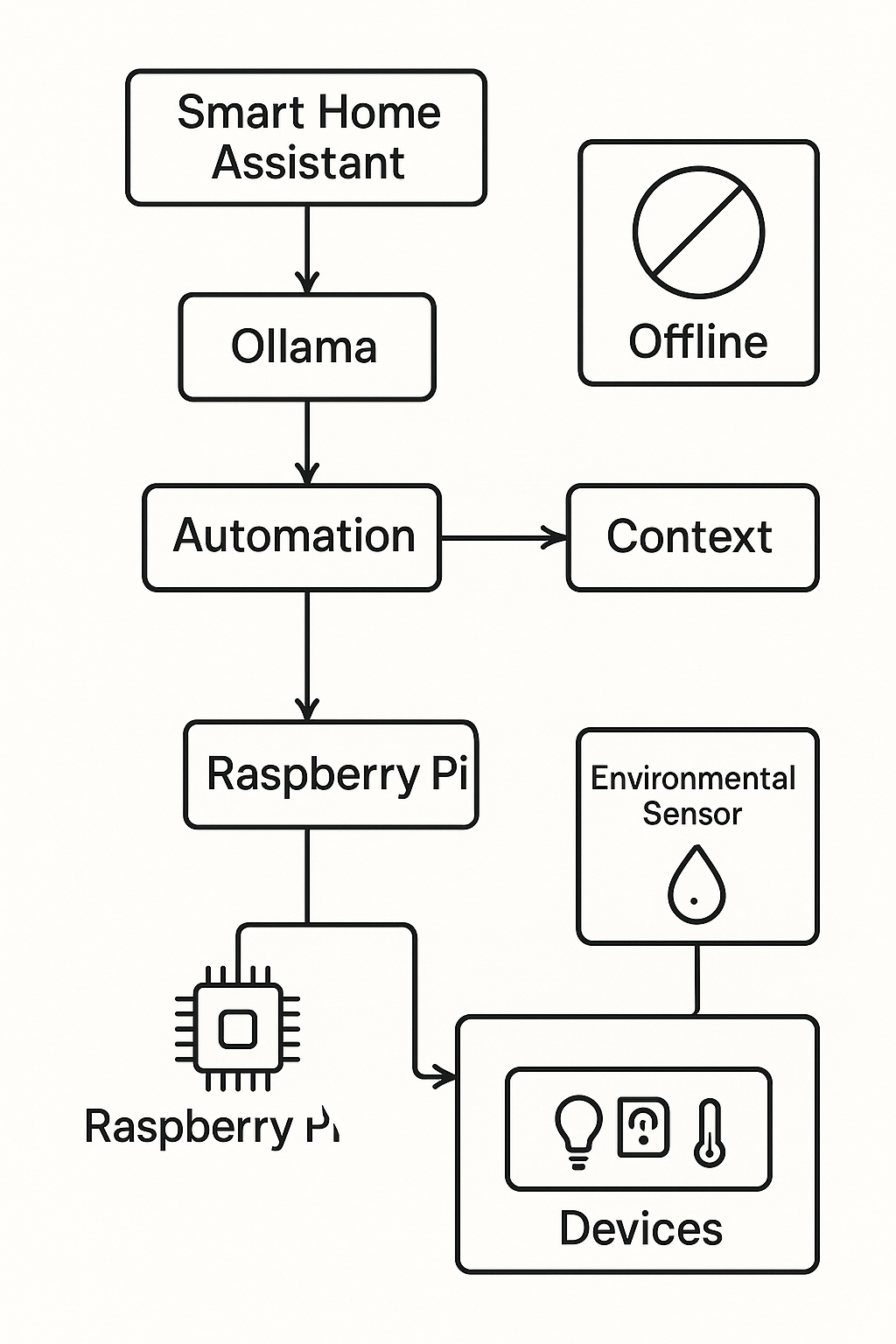
圖4:系統架構
效能指標視覺化
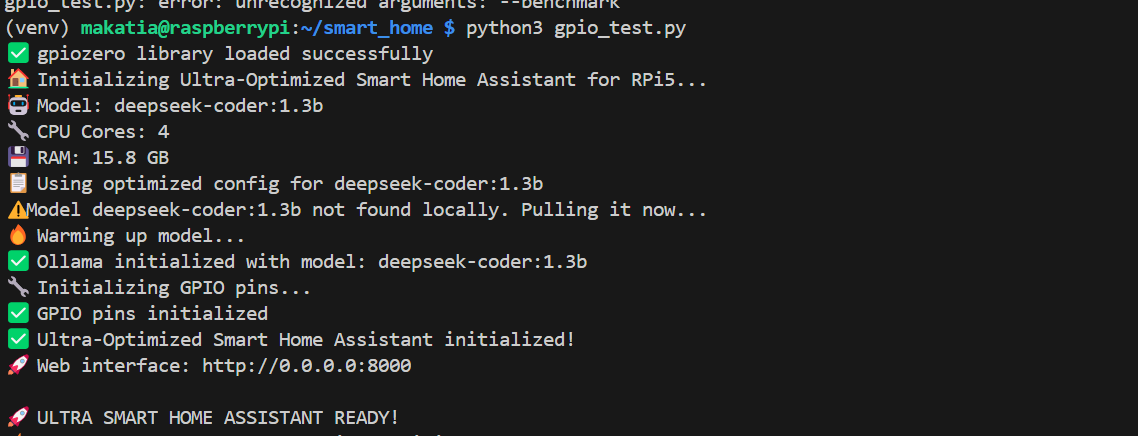
圖5:系統初始化流程,突顯關鍵的最佳化步驟以及硬體與軟體的初始化作業。
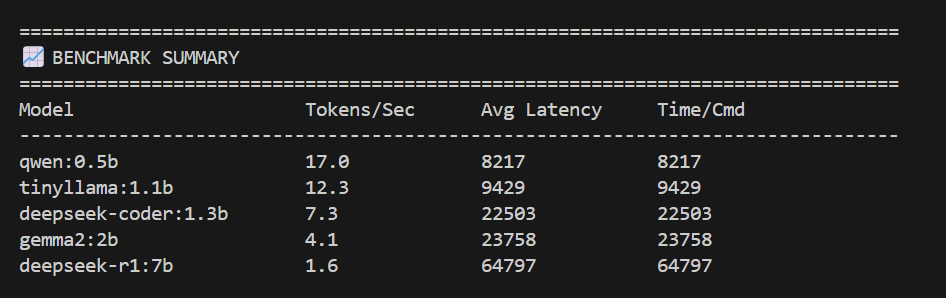
圖6:效能基準測試摘要
技術細節
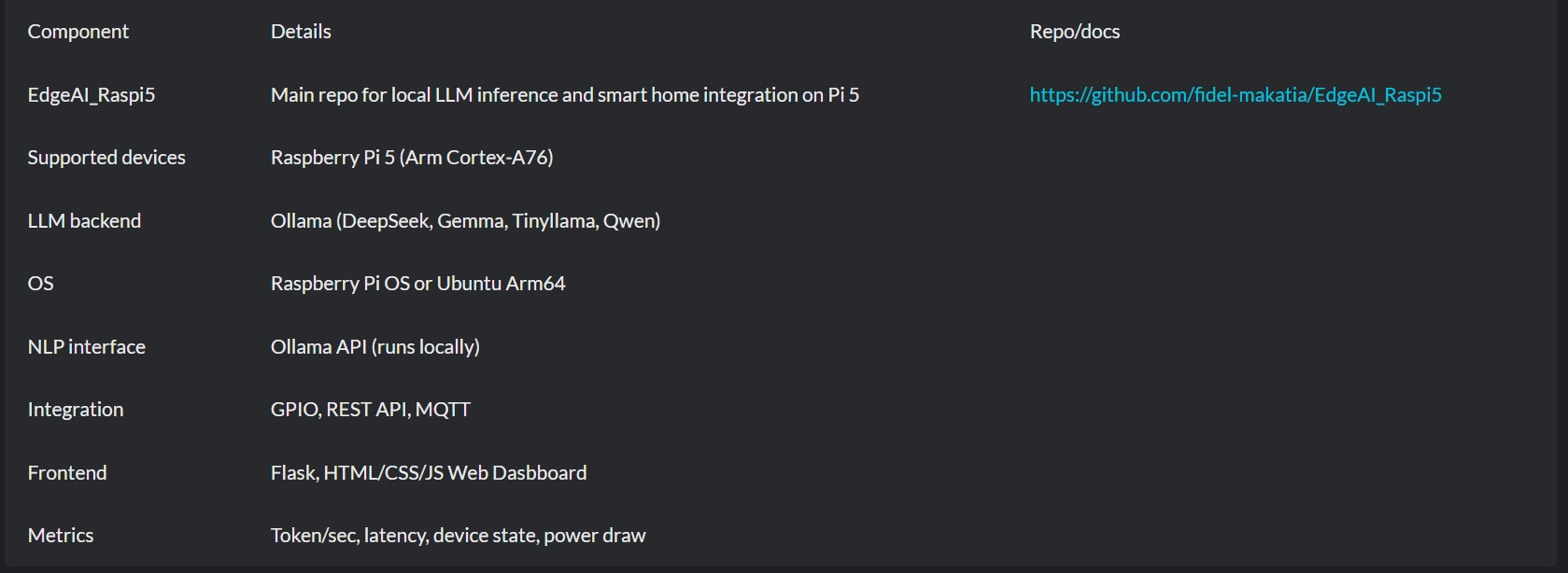
挑戰與解決方案
- 在Pi 5上部署 LLM:Ollama提供的量化模型讓LLM推論變得切實可行。量化技術可大幅降低模型在記憶體與運算上的負擔,對現代Arm CPU特別有效,使Raspberry Pi 5 能在不到 16GB 記憶體的情況下支援最高達 70 億參數的模型(例如 Deepseek 7B)。
- 維持即時回應能力:所有請求與自動化流程皆在本地端完成,在完成推論後,多數任務都能達到亞秒級的回應時間。
- 通用通訊協定支援:程式碼採模組化設計,支援GPIO、MQTT與Zigbee,確保可與各式各樣的家庭硬體相容。
效能指標
| 指標 | Raspberry Pi 5 本地端LLM(Ollama) | 雲端 AI | 說明 |
| 推論延遲 | 約 1–9 秒(TinyLlama 1.1B) | 0.5–2.5 秒(另加網路抖動) | 本地端推論具備一致性、隱私性與可預測性 |
| 指令執行 | 推論完成後即時執行 | 受網路/伺服器延遲影響 | Arm 架構的 Pi 5 消除了雲端作為單點故障的風險 |
| Tokens/秒 | 8–20 tokens/秒 | 20–80+ | 本地端模型在 Arm 硬體上的速度正快速提升 |
| 可靠性 | 可離線運作;無外部相依性 | 需要網際網路 | Pi 5 可作為全天候中樞,不受 ISP 中斷影響 |
| 隱私 | 100% 在裝置端;資料不外流 | 資料需傳送至服務供應商 | 絕對的資料隱私可獲得保障 |
| 持續成本 | 硬體購置後為 0 美元 | 每月約 5–25 美元(API 費用) | 無任何持續性費用 |
| 模型客製化 | 可在本地端執行任意量化模型 | 由服務供應商限制 | 支援 GGUF 與 ONNX 格式,具備高度彈性 |
| 安全性 | 僅限本地網路 | 暴露於遠端入侵風險 | 攻擊面大幅降低 |
結果與影響
- 真正在裝置端運行、私有的 AI:所有運算與自動化流程皆在裝置端完成,資料完全不會離開你的區域網路。
- 低延遲、高可靠性:即使拔除網路連線,也能實現近乎即時的指令執行。
- 硬體彈性高:可在任何支援Python與Ollama的Arm Cortex-A架構平台上執行。
技術堆疊
- 後端:Python 3、Flask
- 網頁前端:HTML、CSS、JavaScript
- LLM/NLP:Ollama、DeepSeek(其他可選:Gemma、Qwen、TinyLlama、Mistral)
- 硬體:gpiozero、Adafruit DHT(選用)
- API:REST、網頁儀表板、CLI
開始使用
- 程式碼庫與文件:https://github.com/fidel-makatia/EdgeAI_Raspi5
- 快速上手:
-
- 將Raspberry Pi OS或Ubuntu燒錄至SD卡或NVMe磁碟。
- 複製(clone)程式碼庫,並依照說明完成安裝。
- 透過Ollama下載支援的 LLM(相關建議請參考程式碼庫)。
- 連接家中裝置並設定自動化流程。
接下來的步驟
- Fork這個程式碼庫,並在你的Raspberry Pi 5上親自嘗試。
- 擴充支援更多模型、通訊協定或感測器。
- 使用儀表板進行在地端自動化與系統監控。
- 觀看下方的示範影片:
可使用的Arm開發者工具
其他資源
- EdgeAI_Raspi5 GitHub: https://github.com/fidel-makatia/EdgeAI_Raspi5
- Ollama: https://ollama.com/
- Raspberry Pi 5 Documentation
- Whisper.cpp (for optional voice integration)
這個專案展示了在Raspberry Pi 5上進行本地端LLM推論,如何徹底改變智慧家庭在隱私、延遲與可靠性上的表現,並將控制權真正帶回邊緣端。
若想取得打造以隱私為優先的智慧家庭助理之逐步指南,歡迎探索 Arm Learning Path for Raspberry Pi Smart Home。
(參考原文:Transformin smart home privacy and latency with local LLM inference on Arm devices;本文作者為美國德州農工大學博士,中文版校閱者為Arm首席應用工程師林宜均)
- 【Arm的AI世界】打造車用裝置端多模態助理 - 2026/06/16
- 【Arm的AI世界】運算平台開發者必看:無須硬體也能進行OpenBMC+UEFI模擬與驗證! - 2026/04/09
- 【Arm的AI世界】運用ExecuTorch與Arm SME2加速裝置端機器學習推論 - 2026/03/18
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


