作者:Felix Lin
WoS完整且彈性的Gen AI Stack
前一篇文章筆者介紹了如何使用高通(Qualcomm) AI Hub來快速地在Windows on Snapdragon (WoS)完成AI應用的部署,然而身為被認證為Copilot+ PC的成員,要能順暢運作本地端生成式AI模型及開發衍生應用才是其最重要的主戰場!
筆者在前篇文章也有介紹過高通的AI Stack推論架構圖,而針對生成式AI同樣也擁有完整的Gen AI Stack。如下圖所示,由上至下分別從開發者的APP 、模型類別、GenAI框架、Runtime框架、到不同的AI引擎後端,都有完整且彈性的架構可供選擇。從中間最重要的GenAI API/Frameworks看起,除了高通自家的Gen AI推論套件Genie,還有泛用性更佳的Onnx Runtime GenAI,甚至於開源社群的第三方套件如Llama.cpp、MLC LLM等也都可以在WoS運作。
而在其下層的 AI Runtime Frameworks 框架主要仍以高通 QAIRT 與 ONNX Runtime 搭配 QNN EP (Execution Provider) 為主,往下對應到Snapdragon X上CPU、NPU與GPU等各自的後端低階函式庫與AI引擎。GenAI API/Framework之上,則是可以選擇不同的GenAI模型來源進行導入,包括微軟的AI Toolkit與Local Foundry、高通的AI Hub、第三方的Hugging Face等,具有廣大的相容性與操作上的彈性。本篇文章將會介紹幾種不同的方法在WoS實現本地端生成式AI模型的運作。
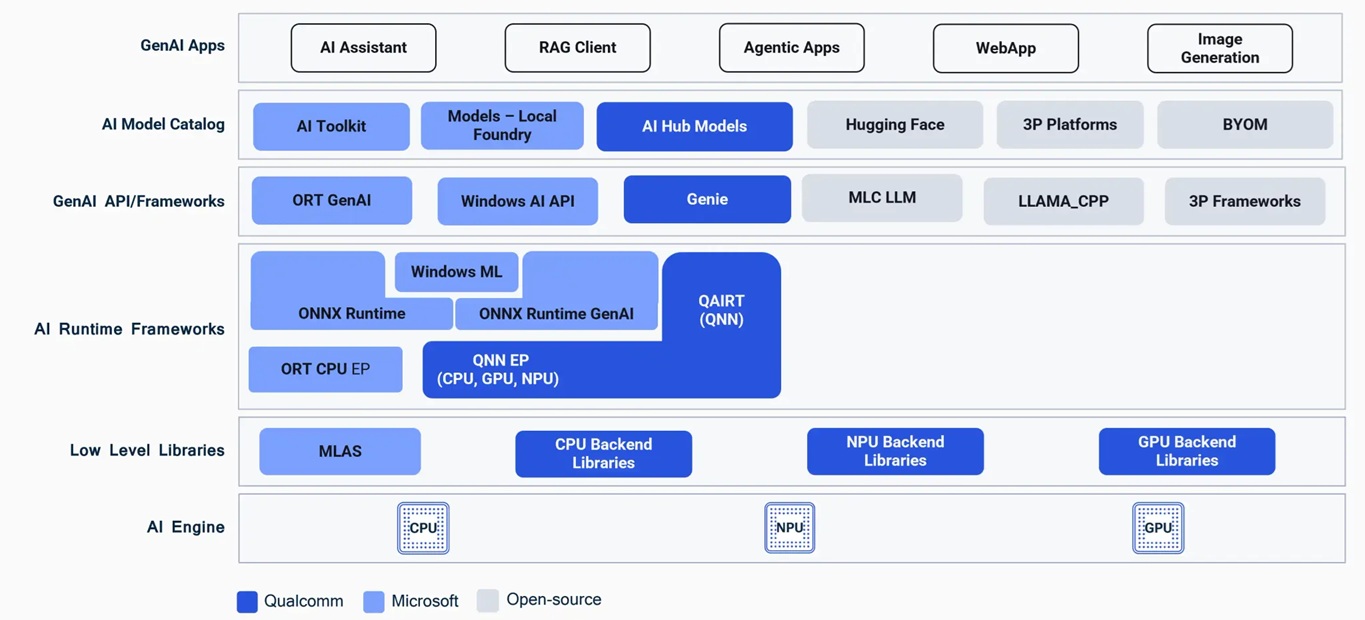
WoS GenAI 推論架構
ORT GenAI x QNN EP的高速渠道
若說到在WoS最推薦的GenAI開發框架,那麼ONNX Runtime GenAI絕對是不二之選,主要在於往下層已經內建打通 QNN Execution Provider,可以彈性選擇要運作在CPU、GPU或是NPU上,效能逼近原生QAIRT且資源調度極為容易掌控。再來往上則是彈性串接各類模型,不管是Hugging Face上的開源模型,抑或是主流框架(如PyTorch)的模型,都很容易轉匯與對接。所以若是要入門WoS應用開發,優先選擇ORT GenAI的工作流準沒錯!使用系統管理員身分開啟Power Shell執行以下流程:
STEP 1:設定工作目錄環境變數 。
$DIR_PATH = "C:\WoS_AI"
STEP 2:下載套件安裝腳本,此腳本是來自於高通的github wos-ai Repo。
if (!(Test-Path $DIR_PATH\Downloads\Setup_Scripts)) {mkdir $DIR_PATH\Downloads\Setup_Scripts}
Invoke-WebRequest -O oga_setup.ps1 https://raw.githubusercontent.com/quic/wos-ai/refs/heads/main/Scripts/oga_setup.ps1
Move-Item -Path ".\oga_setup.ps1" -Destination $DIR_PATH\Downloads\Setup_Scripts -Force
STEP 3:執行腳本安裝所需套件,包含Python、Git、onnxruntime-genai Python模組等。
cd $DIR_PATH
powershell -command "&{. .\Downloads\Setup_Scripts\oga_setup.ps1; OGA_Setup -rootDirPath $DIR_PATH}"
STEP 4:從Hugging Face取得已編譯好的QNN模型。在llmware下有兩個立即可用的ONNX QNN模型分別是llama3.2-3b和phi3.5,這邊可直接進行下載。當然後續開發者若有透過AI Hub進行模型的匯出與最佳化所導出的模型,理論上也都是可以直接套用的。
$DIR_PATH = "C:\WoS_AI"
cd $DIR_PATH
git clone https://huggingface.co/llmware/llama-3.2-3b-onnx-qnn
STEP 5:下載範例程式。此範例是微軟onnxruntime-genai repo中的python QA問答範例程式。
$DIR_PATH = "C:\WoS_AI"
cd $DIR_PATH
curl https://raw.githubusercontent.com/microsoft/onnxruntime-genai/refs/heads/main/examples/python/model-qa.py -o model-qa.py
STEP 6:啟動python虛擬環境。運用STEP 3下載的腳本,進入SDX_OGA_ENV虛擬環境。
powershell -NoExit -command "&{cd $DIR_PATH; . .\Downloads\Setup_Scripts\oga_setup.ps1; Activate_OGA_VENV -rootDirPath $DIR_PATH}"
STEP 7:執行ONNX GenAI進行llama3.2對話。預設是運作於NPU上,如下圖所顯示之結果,可以看到Tok/s可接近165。這邊用有到幾個指令參數說明如下:
- model_path:指定模型路徑,指向稍早下載的llama-3.2-3b。若有下載其他模型(如phi3.5) 可將路徑指向到該模型。
- execution_provider:指定ONNX Runtime EP,由於希望在NPU執行推論,因此指定為遵循設定檔,該設定檔檔名為 genai_config.json,存放在與模型相通的路徑下。
- timing:顯示TTFT與tok/s資訊。
python .\model-qa.py --model_path .\llama-3.2-3b-onnx-qnn --execution_provider "follow_config" --timings
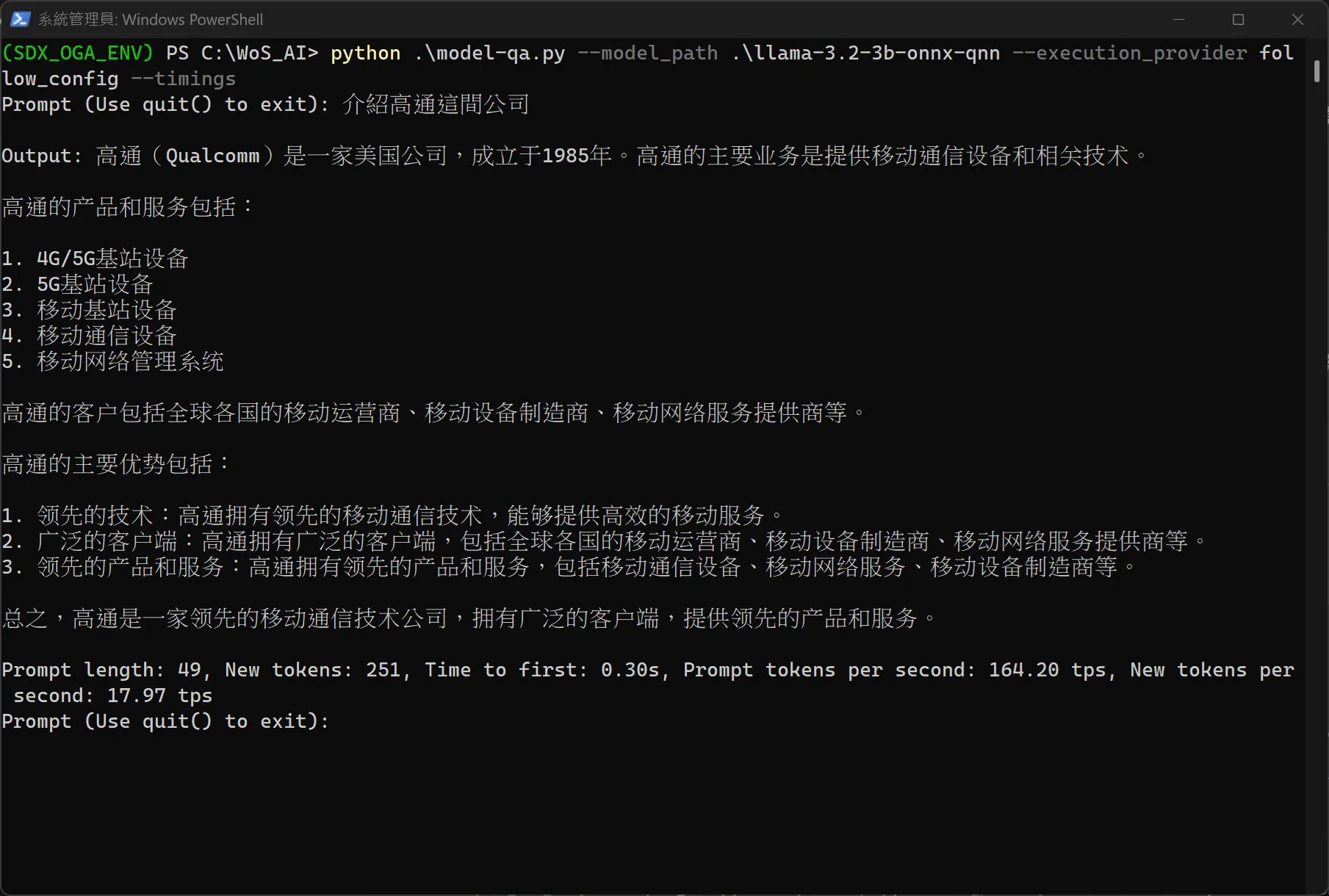
使用Hexagon NPU進行推論,每秒大約輸出165 tokens
AI Foundry Local
Azure AI Foundry是微軟推出的一站式生成式 AI 平台,整合模型市集、代理開發工具與企業級管理部署工具,而AI Foundry Local是Azure AI Foundry的本地化部署選項,專為高隱私、低延遲或斷網環境而設計。開發者可將雲端模型下載並轉換成ONNX、QNN等格式,在自有伺服器、邊緣裝置或Windows on Snapdragon PC上執行推論。現階段AI Foundry Local與WoS的整合協調性也非常好,只需要幾個指令即可馬上運作。
STEP 1: 安裝AI Foundry Local工具。開啟Power Shell 執行下方指令,可以看到套件正在啟動安裝的過程如下圖。
winget install Microsoft.FoundryLocal
安裝Foundry Local工具
STEP 2:輸入下方指令查看可以支援的模型清單。以當前筆者的環境來說,有deepseek-r1與phi4-mini支援NPU運作,其他還有qwen、phi3與mistral的CPU運作版本等。
foundry model list
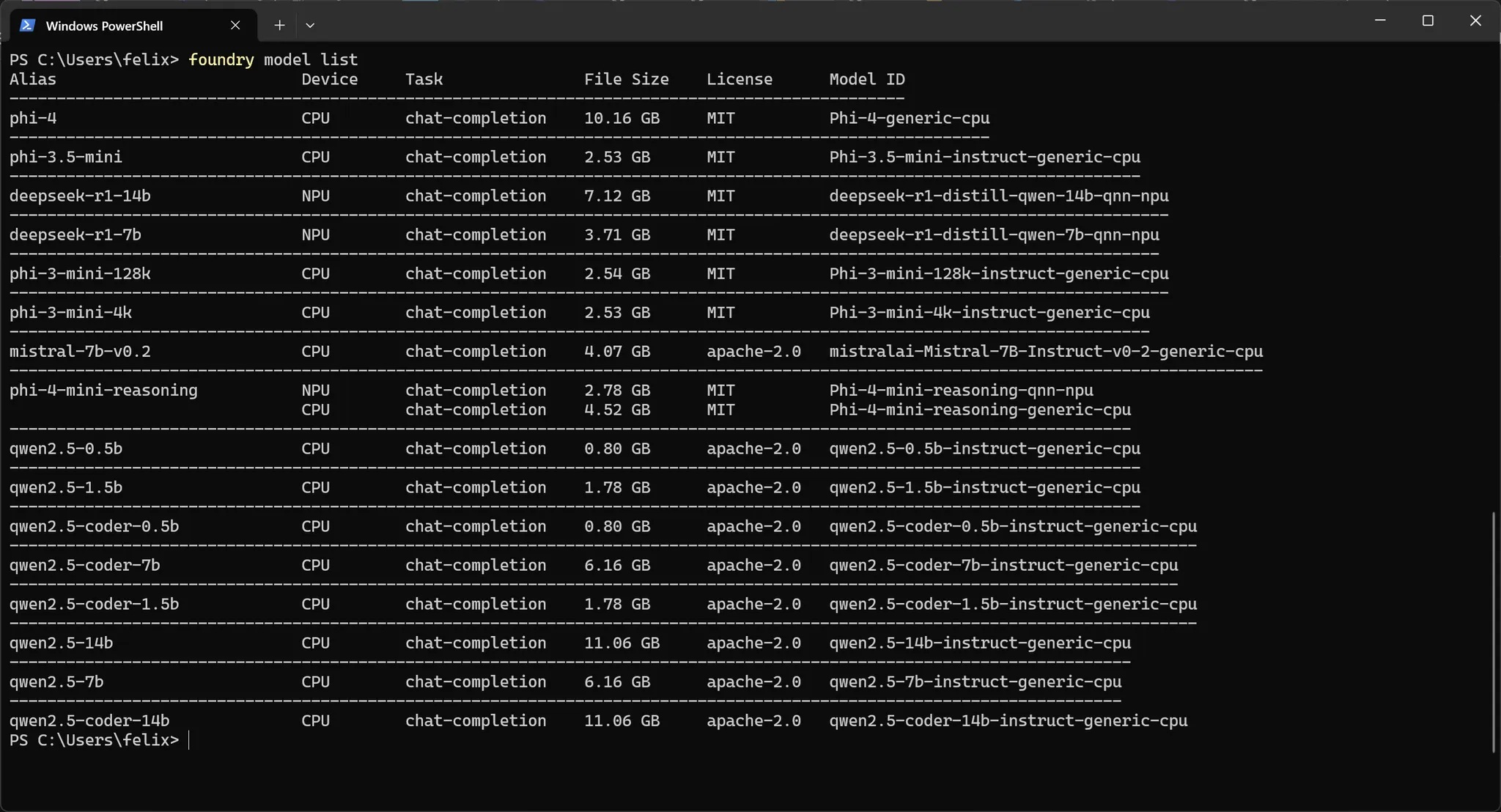
線上查找支援的模型清單
STEP 3:運作模型。這邊以deepseek-r1作為範例,若要執行其他模型只要將模型名稱更換即可。
foundry model run deepseek-r1-7b
啟動後除了進入到對話模式進行交談外,Foundry Local也會啟動伺服器讓其他的client端可以連入進行互動,開發者也可以使用Foundry Local SDK或Rest API方式進行應用開發。
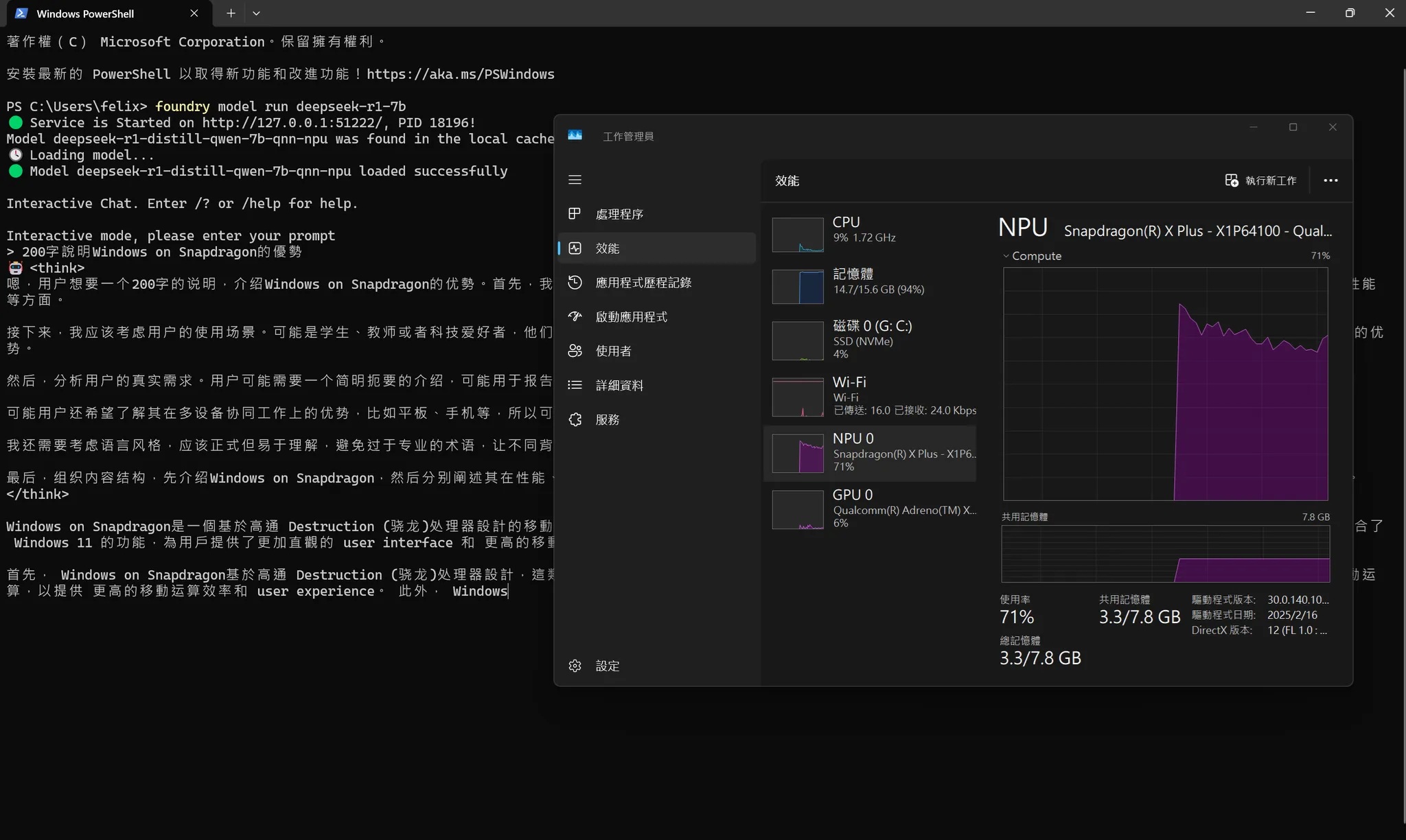
Foundry Local以NPU進行deepseek-r1推論
AI Toolkit for VS Code
Microsoft AI Toolkit是一個VS Code擴充整合式工具套件,協助開發者快速探索、測試、微調與部署生成式AI模型。該工具套件內建Modal Catalog,可以檢索來自不同平台(如Azure、Hugging Face等)的模型,並且下載至本地端playground 即時對話測試。
STEP 1:安裝AI Toolkit。開啟 VS Code 切換到Extensions擴充元件頁面,搜尋「AI Toolkit」並進行安裝。
安裝AI Toolkit for Visual Studio Code
STEP 2:下載模型。點選 VS Code 側邊的「AI Toolkit」 ,在裡面找到「Model Catalog」選項,主視窗會顯示「Find the Right Model for Your AI Solution」內容,此處可以搜尋所有支援的模型。可以在「Model Type」的下拉式選單中過濾特定模型,譬如說運作在NPU的模型等。在每一個模型名稱的區塊中點選 「+Add Model」即可下載該模型到本地端。
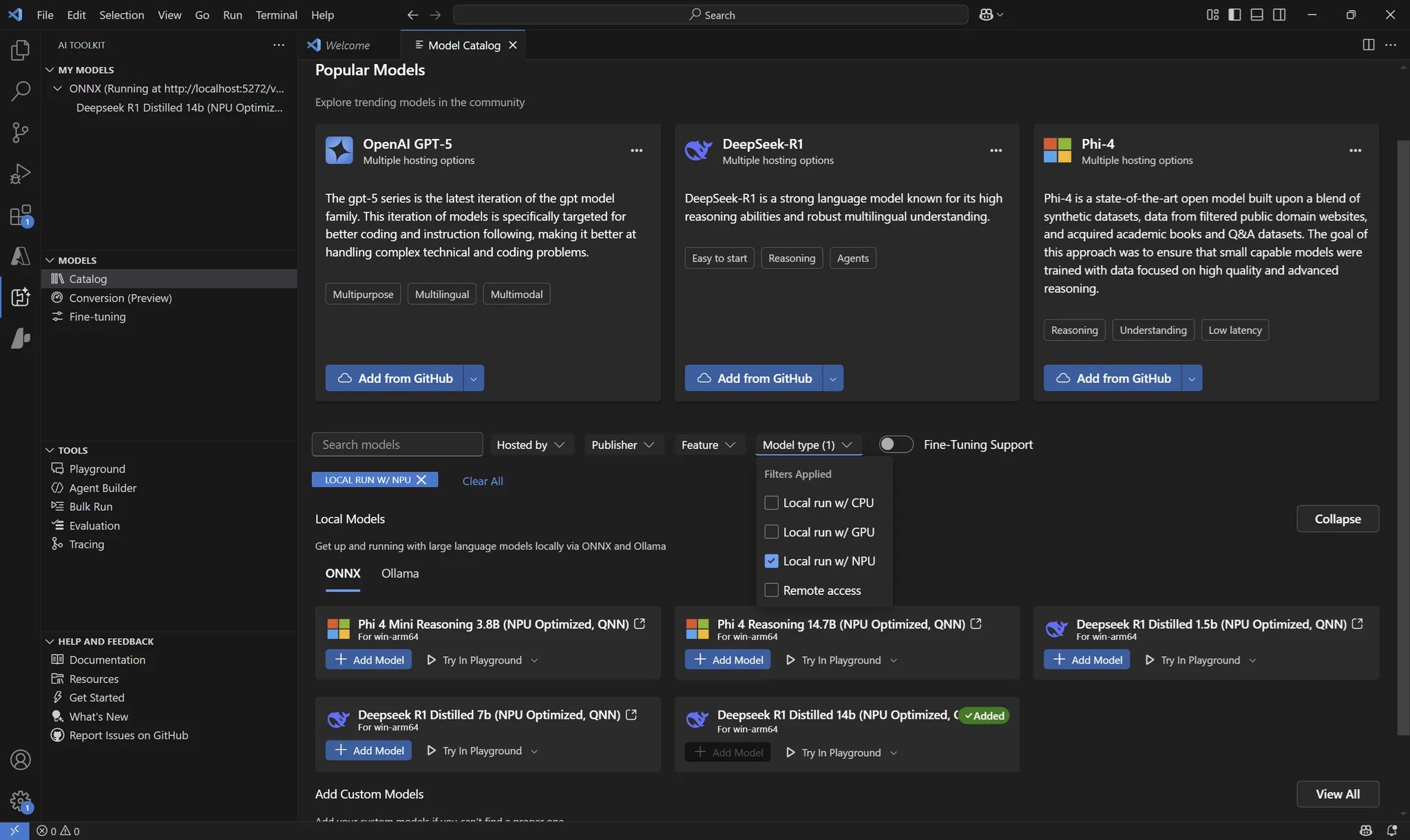
AI Toolkit for VS Code提供相容於OpenAI的API,開發者可以直接以OpenAI SDK進行串接。除此之外也有微調(Fine-Tuning) 功能的整合,可以選擇在本地端或是Azure VM進行。
AnythingLLM
AnythingLLM是一個開放原始碼的本地端知識管理與LLM整合平台,專注於讓文件能與AI對話。使用者可匯入PDF、Word、Markdown、網站內容,系統會自動分割、向量化,並建立檢索式知識庫;此外導入了Workspace 概念,將不同專案或部門的知識分開管理。在模型選擇上,AnythingLLM既能連接雲端 API (OpenAI、Gemini、Anthropic等),也能透過Ollama、LM Studio或Local AI運作本地端模型。
要安裝AnythingLLM,只要到官網下載Winwdows (Arm)版本,並且執行安裝即可完成。啟動後進入設定頁面,在「大型語言模型」(LLM)的設定分項中,可選擇不同LLM的提供者。透過下拉式選單可以找到「AnythingLLM NPU」的模型來源,下方則會出現來自微軟與Meta語言模型的NPU最佳化版本,初次選擇的模型會自動進行下載。
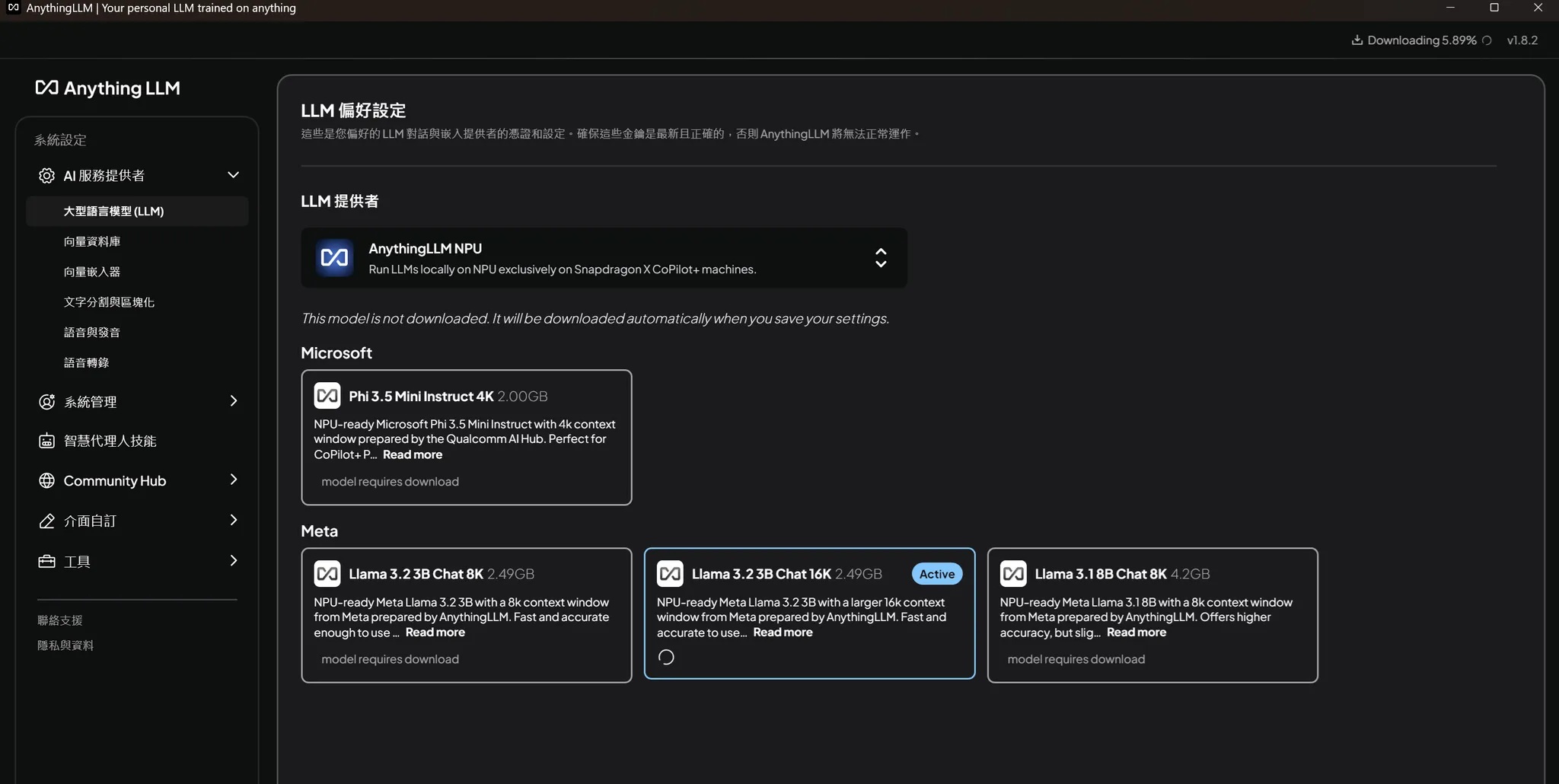
AnythingLLM可以選擇直接於Snapdragon NPU運作的語言模型
AnythingLLM有工作區Working Space的概念,不同的工作區可以上傳各自的檔案,進行向量資料庫的嵌入與RAG應用,同時也提供API進行外部呼叫,比較適合做為個人或小型團隊的知識庫衍伸開發。
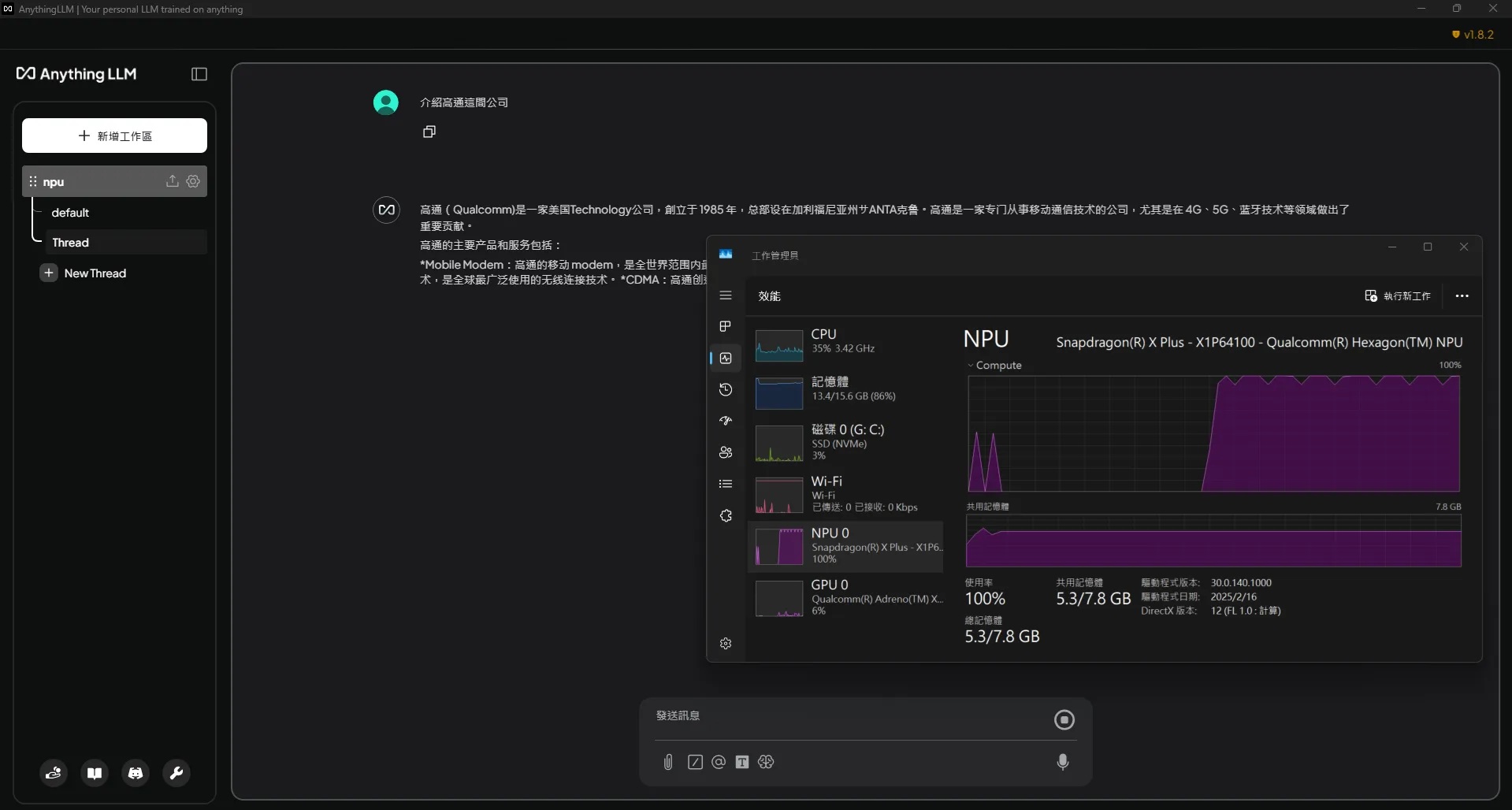
AnythingLLM提供的NPU模型表現也相當稱職
Ollama
Ollama可以說最熱門的本地端LLM運作工具,特色是輕量化且簡單易,使用者只需透過ollama run指令,就能快速下載並運作Llama、Mistral、Gemma等熱門開源模型,使其也活躍在本地端LLM使用者社群之中。即便目前Ollama並不支援Snapdragon X的NPU或GPU加速,但其提供的量化版本(如Q4、Q8等)在Snapdragon X上也有相當優異的性能表現。
Ollama下載模型到本地端並運作
安裝Ollama也是非常簡單,只要到官方網站下載對應的系統安裝執行檔,依循步驟即可完成。安裝完成後只要在命令列下執行ollama run <model>即可執行本地端模型,若沒有找到本地端模型則會自動從Ollama的模型庫進行下載。除此之外,Ollama也在2025年7月底v0.10版本之後增加本地端的簡易GUI,更方便使用者操作。
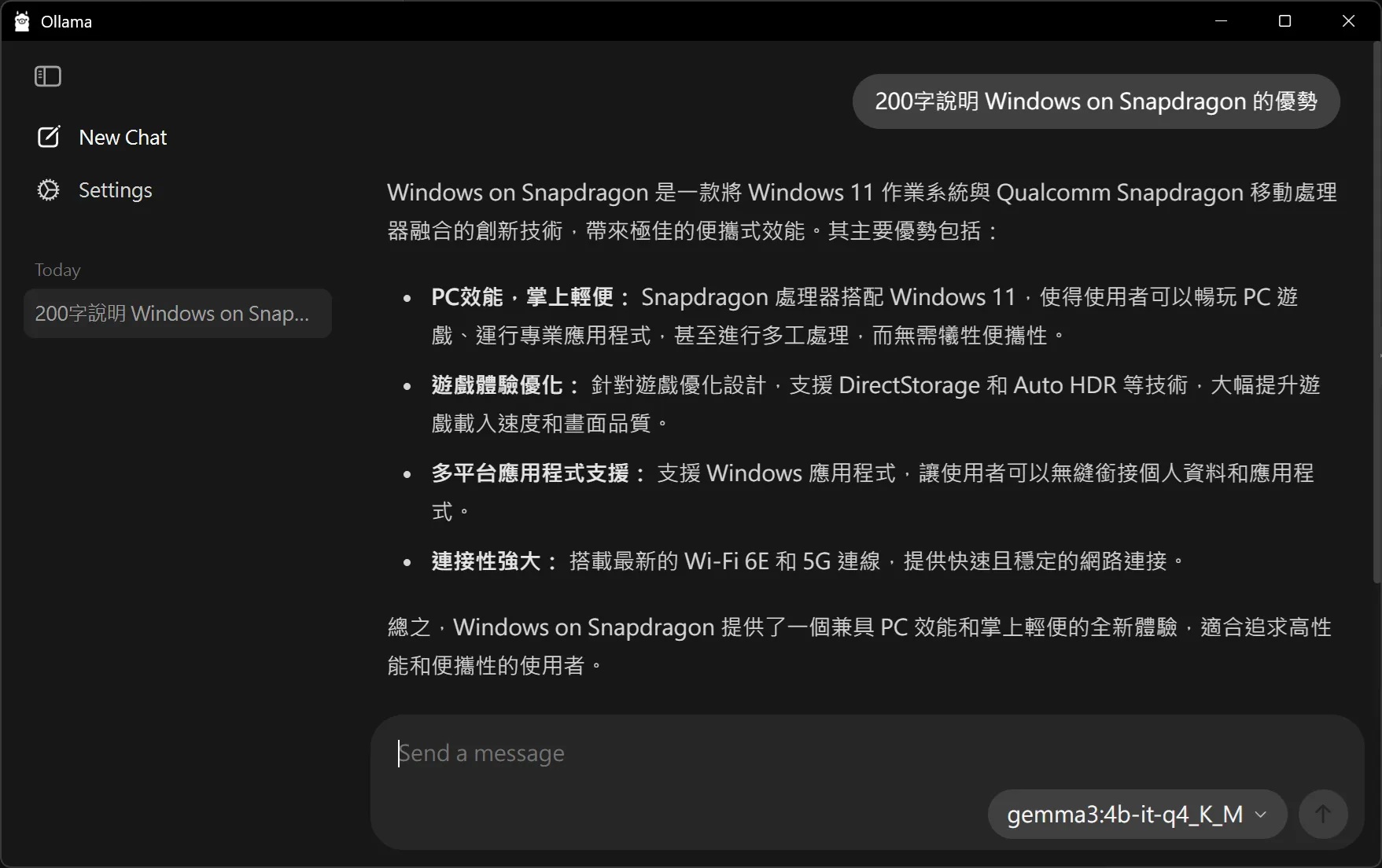
新版本Ollama的GUI
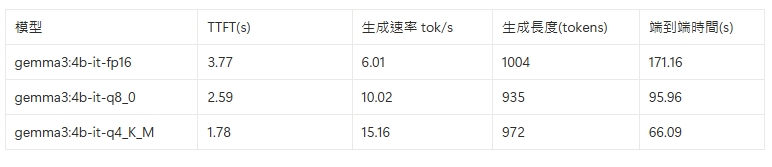
筆者在Snapdragon X上使用ollama-benchmark針對Gemma3 4b不同的量化模型做效能測試,從下表的測試結果約略可以看出,在純CPU推論Q4量化模型可達15.16,是Q8模型的1.5倍,FP16模型的2.5倍,可見即便是尚不支援NPU與GPU推論的模型,經過量化後的模型在Ollama上執行依然有相當程度之水準。
小結:前程似錦的WoS GenAI
以筆者近期的開發與使用心得來說,原先在測試前抱持的較為觀望的態度,在歷經一段時間的接觸後,也對Windows on Snapdragon改觀不少。除了軟體相容性的疑慮幾乎已完全去除,優異的運算與續航能力的開發體驗更是令人感到不同凡響,要做為開發與部署AI應用的主力平台也絕對不成問題。而目前能夠在Windows on Snapdragon平台開發Gen AI應用的工具也如雨後春筍般的出現,除了晶片本身低功耗高算力的特性,搭配ONNX標準化的EP介接,使Gen AI無論是在硬體資源調配或是開發彈性上都大有可為!

- 以MCU開啟Edge AI新境界:Renesas RA8P1實測 - 2025/10/22
- Windows on Snapdragon部署GenAI策略指南 - 2025/09/23
- 運用Qualcomm AI Hub結合WoS打造低功耗高效能推論平台 - 2025/08/01
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


