作者:歐敏銓
隨著生成式AI席捲全球,無論是聊天機器人、AI繪圖還是企業智慧應用,背後都依賴龐大的運算能量支撐。當AI演算法從實驗室走向商業化,如何建構能同時兼顧效能、能效與成本的硬體基礎設施,成為產業的核心課題。眼下,這場AI算力競爭逐漸分裂為兩條主軸:一是由NVIDIA主導的「AI Factory」一站式解決方案;另一則是AWS、Google、Meta、OpenAI等雲端巨頭自研的專用AI晶片。這不僅是一場技術之爭,更是一場商業生態的角力。
GPU霸主的「工廠夢」
NVIDIA創辦人黃仁勳近來常以AI Factory一詞來形容未來的數據中心。他認為,數據中心已不再只是儲存與處理資料的倉庫,而是類似「工廠」般的生產線,專門將資料轉換成AI模型與智慧服務。

NVIDIA的AI Factory戰略,正是以其最新一代Blackwell架構GPU為核心,並搭配Grace CPU、Spectrum-X網路交換技術與BlueField DPU,打造一套完整的AI運算平台。這套系統能支援超大規模的模型訓練與推理,從OpenAI的ChatGPT到全球汽車廠的自駕系統訓練,幾乎都能在NVIDIA的硬體上找到合適的運行空間。
不同於單純銷售晶片,NVIDIA更強調「軟硬體一體化」:CUDA程式框架、NeMo訓練工具、以及新近推出的NIM微服務,讓開發者能更快把AI模型從原型推向生產環境。這種「一站式整合」的模式,使NVIDIA的方案對於企業而言更具吸引力,因為它不只是提供零件,而是交付一座可立即啟動的「AI工廠」。
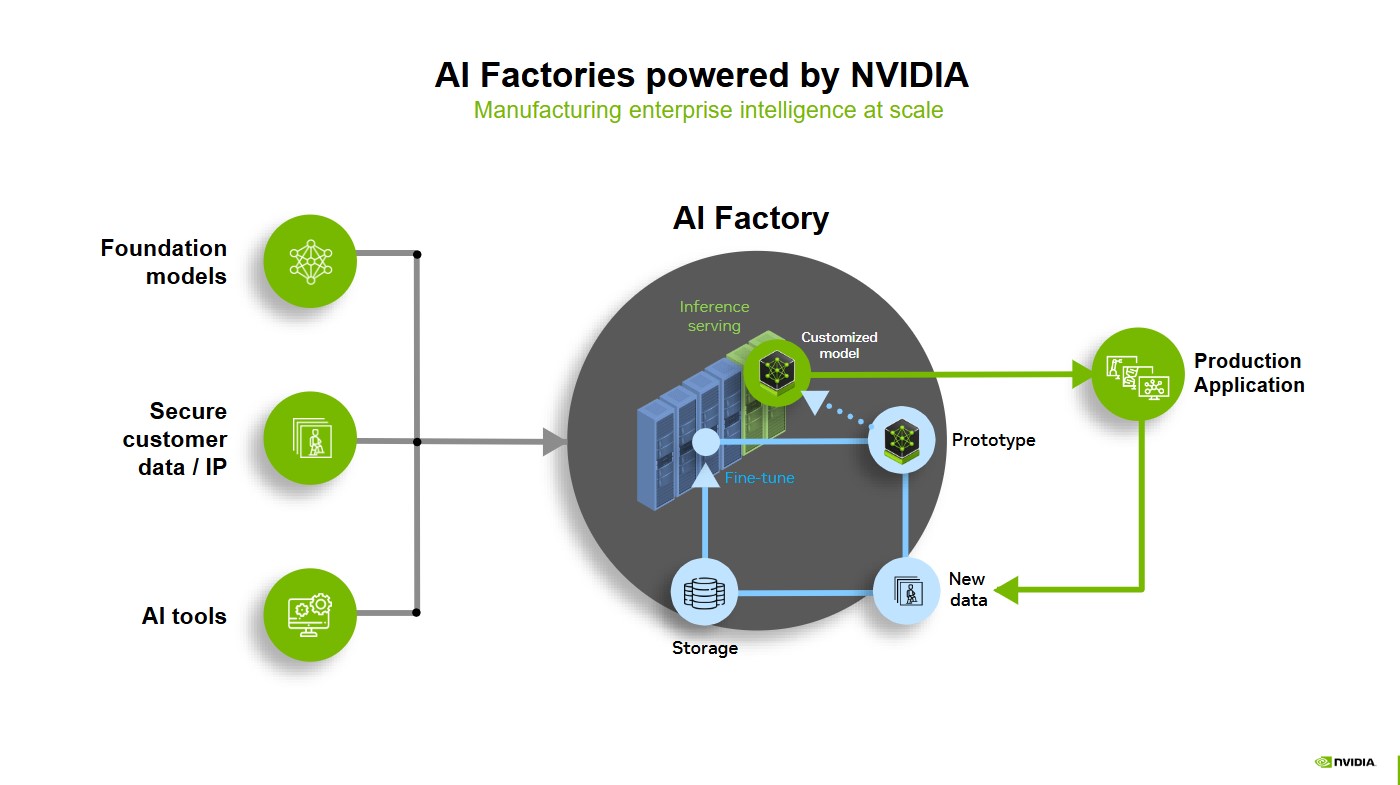
然而,這座工廠的成本也不容忽視。GPU作為通用架構,在靈活性與兼容性上無疑佔盡優勢,但也意味著其能效不及專用晶片。動輒數萬美元的GPU伺服器,加上高昂的能耗支出,對雲端服務商而言是一筆不小的負擔。
雲端巨頭的「自製武器」
與NVIDIA形成鮮明對比的,是亞馬遜AWS、Google與Meta這些雲端巨頭的策略。他們選擇不再完全依賴外部供應,而是投入巨資打造自有AI專用晶片。
AWS
AWS推出的Trainium與Inferentia,就是最具代表性的案例。Trainium專注於模型訓練,能在相同功耗下提供比GPU更高的吞吐量;Inferentia則針對推理優化,以低延遲與高能效著稱。對AWS來說,這不僅是提升效能,更是降低運算成本的關鍵武器。
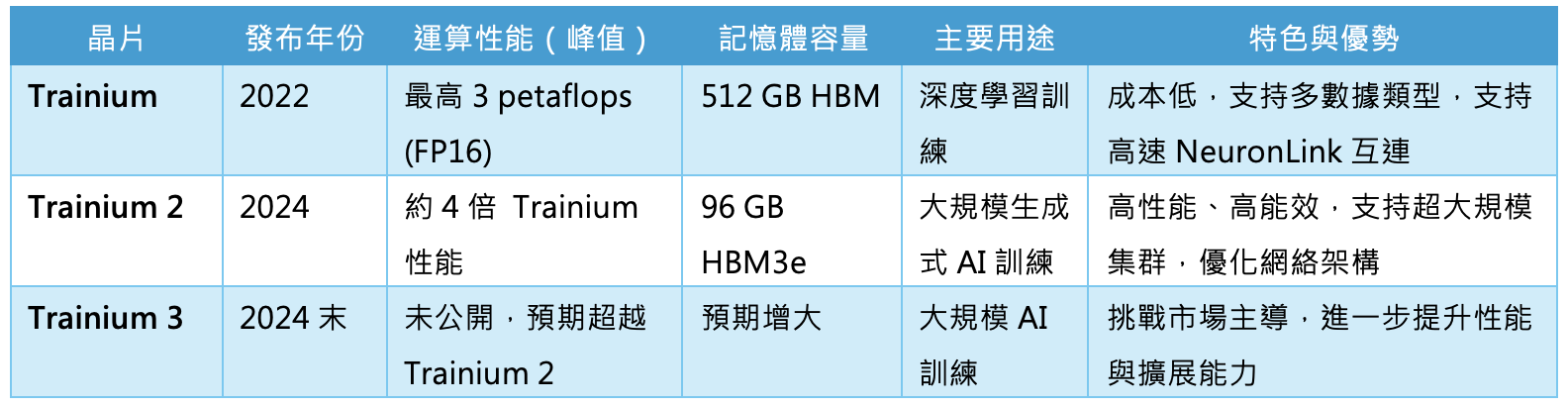
Trainium版本比較表
Google則憑藉TPU(Tensor Processing Unit)打響自研晶片名號。自2015年首款TPU亮相以來,Google已經推出多個世代產品。最新的TPU v5與v6,不僅在大規模生成式AI模型上展現驚人效能,還導入稀疏運算等新技術,以提高能效比。對Google而言,TPU是推動其雲端服務與AI研究的雙重引擎。
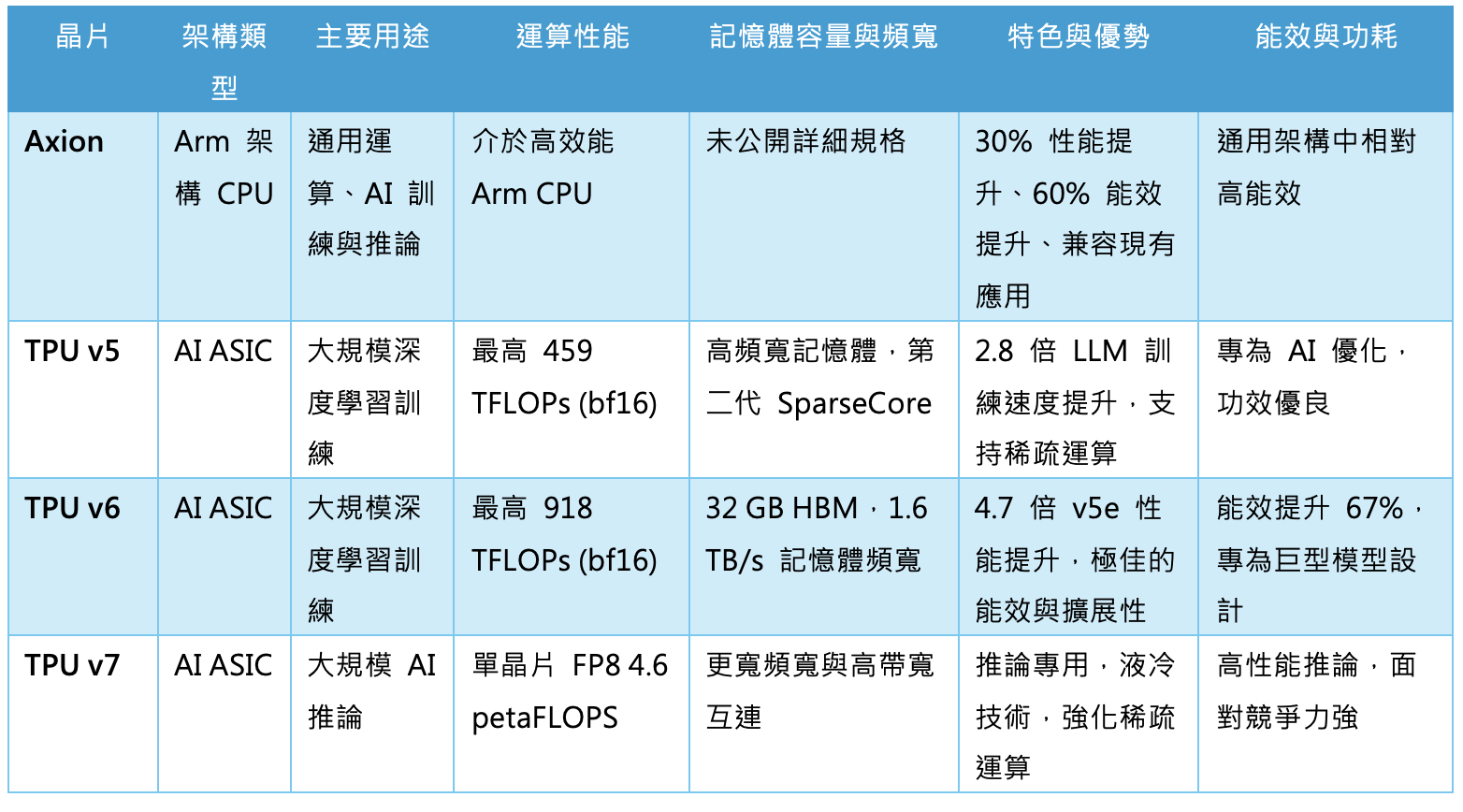
Google AI 晶片比較表
Meta
至於Meta,它的MTIA晶片則主要針對自家龐大的推薦系統與生成式AI應用。MTIA v1與v2為Meta自研AI ASIC,聚焦推薦系統與生成式AI推理與訓練,強調記憶體帶寬與運算平衡。MTIA v2在性能與稀疏運算能力相較於v1提升3倍以上,適合Meta多元AI負載。
相較於NVIDIA GPU的「全能型」,MTIA更像是為特定工序量身訂做的工具。雖然通用性不足,但在Meta核心業務上卻能發揮極致效益。
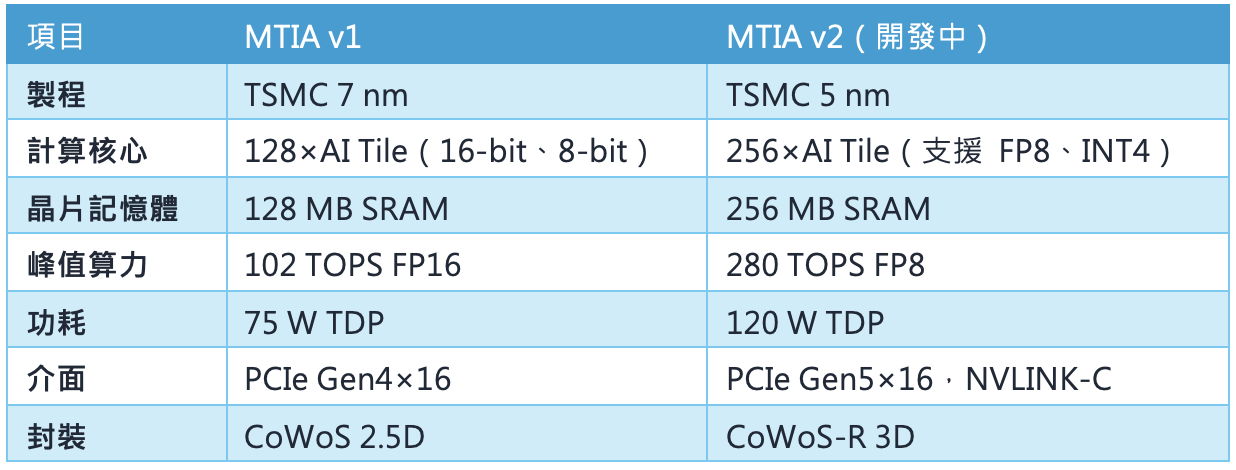
MITA v1與v2技術規格比較
雲端巨頭的自研晶片策略,不僅是技術選擇,更是商業佈局。透過自有硬體,他們能擺脫對NVIDIA的高度依賴,同時在AI服務上形成差異化。
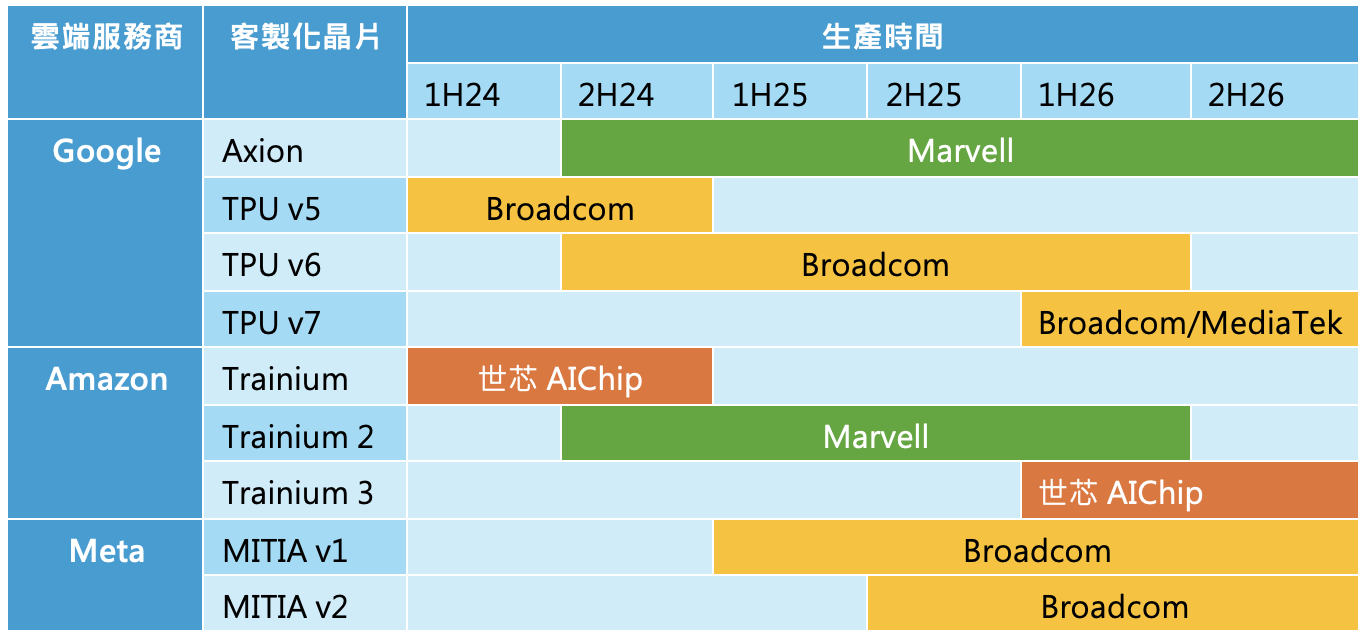
雲端巨頭自己研發的AI客製化晶片生產進程與協力開發晶片商
技術與商業的雙重較量
這場GPU與ASIC的對決,本質上是一場「通用性」與「專用性」的拉鋸。
NVIDIA的優勢在於其龐大的生態系統。從CUDA程式語言到龐大的開發者社群,從全球雲端業者到AI新創,NVIDIA早已築起一道深厚的護城河。任何一間企業若選擇NVIDIA,幾乎能確保與主流AI工具無縫兼容。
相對的,雲端巨頭自研晶片的優勢則在於「極致效率」。由於晶片針對特定工作負載設計,功耗比與成本效益往往遠勝GPU。例如AWS聲稱,使用Trainium進行訓練,成本可比GPU降低四成。對需要大規模佈署AI的雲端平台來說,這是一筆相當可觀的節省。
但專用晶片也面臨挑戰:缺乏廣泛的軟體生態支持,意味著開發者必須學習新的工具鏈,甚至重新調整模型,才能充分發揮效能。這對於希望快速上線AI服務的企業而言,可能成為阻力。
市場趨勢:兩條道路,殊途同歸
市場研究機構預估,到2025年,全球AI加速器市場規模將突破數百億美元。驅動這股成長的,正是生成式AI與邊緣AI的爆發需求。
在這個快速演進的市場,NVIDIA與雲端巨頭的策略將持續並行:
- NVIDIA將繼續深化「AI工廠」戰略,透過NVLink Fusion等技術,把多顆GPU無縫連結成更大的算力池,並持續推出支援液冷的新一代伺服器,滿足高能耗AI訓練需求。
- AWS、Google與Meta則會加速推進自研晶片,不僅用於自家雲端服務,也可能逐步開放給外部客戶使用,形成與NVIDIA競爭的另一條供應鏈。
長遠來看,兩者並非完全對立。GPU與ASIC很可能將形成互補:GPU繼續擔任通用型平台,適合快速創新與多元應用;ASIC則專精於核心場景,提供更低成本的解決方案。
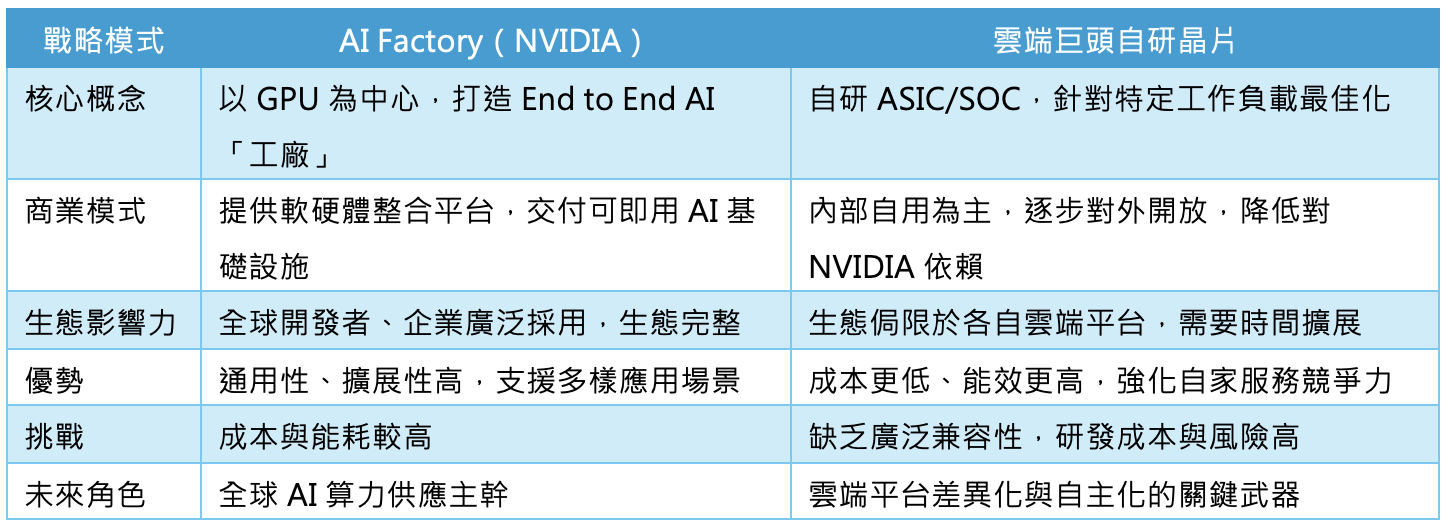
AI Foundry vs. 自研AI晶片比較表
結語:算力時代的雙軌競爭
AI的黃金時代,正由硬體基礎設施決定勝負。NVIDIA憑藉AI工廠戰略,鞏固了其「通用型算力霸主」的地位;而AWS、Google與Meta等巨頭,則透過自研ASIC打造專屬武器,力求在效能與成本上取得優勢。
這不僅是技術的對決,更是商業模式的博弈。前者強調完整生態與廣泛兼容,後者追求效率極致與自主掌控。未來,這兩條路線將持續並行,甚至交織出更多合作與競爭。
》延伸閱讀:
AI Factories Are Redefining Data Centers and Enabling the Next Era of AI (NVIDIA Blog)

- 斷翼的國家隊?解析無人機國造的必要性與當前衝擊 - 2026/05/20
- 邁向具身智慧的下一站:群雄並起的「世界模型」競技場 - 2026/05/14
- 【從LLM到世界模型】AMI Labs為何強勢崛起? - 2026/05/13
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


