你是否好奇如何防止AI 聊天機器人偶爾給出過時或不準確的答案?檢索增強生成 (Retrieval-Augmented Generation,RAG) 技術提供了一種強大的解決方案,能夠顯著提升答案的準確性和相關性。
本文將探討RAG的效能優勢,並分享在基於Arm Neoverse平台的Google Axion處理器上建構 RAG 應用的指導,以最佳化AI工作負載。在本文的測試中,Google Axion處理器相較於x86架構處理器,效能提升了2.5倍,並節省了64%的成本。Google Axion處理器透過更好的RAG效能加速推論過程,進而實現更快的知識檢索、更低的回應延遲和更高效的AI推論,這對於即時、動態AI應用相當重要。
了解RAG:高效率的AI文字生成方法
RAG是一種主流 AI 框架,能夠即時檢索相關外部知識,進而提升大型語言模型(LLM)生成文字的品質和相關性。與僅依賴靜態預訓練資料集的方法不同,RAG動態整合了最新外部資源資訊,能夠生成更精確且貼近上下文的輸出結果。這使得RAG在實際應用場景中表現出色,例如客服聊天機器人、智慧代理工具和動態內容生成等場景。
何時該選擇RAG而非微調或重新訓練?
基礎LLM透過類似人類的文字生成功能徹底改變了AI領域,但其有效性取決於模型是否擁有企業所需的最新資訊。對於經過預訓練的LLM模型進行重新訓練(re-training)和微調(fine-tuning),是整合額外知識的兩種常用方法;重新訓練LLM是一個資源密集型的複雜過程,微調則能夠使用特定資料集對LLM進行訓練,調整模型的權重,可更好地完成目標任務。不過,模型仍然需要定期重新部署,以保持它能與時俱進。
通常,在將LLM納入AI策略時,必須評估其能力和侷限性。主要考慮因素包括:
- 訓練資料集的侷限性:對於訓練資料集未包含的主題,LLM可能難以提供準確或最新的資訊。
- 資源需求高:重新訓練這些大模型需要大量的算力和工程資源,使得頻繁更新難以實施。
- 對內部知識的存取受到限制:由於企業的主要業務資料受到防火牆的保護,因此LLM無法透過定期重新訓練納入專有資訊,這可能會限制LLM在企業內部使用時的相關性。
RAG的優勢
RAG無需修改LLM,只需利用外部資料來源更新知識庫,將動態資訊檢索與語言模型的生成能力相結合。如果你所在的領域知識經常變化,那麼RAG是保持準確性和相關性,並減少LLM幻覺的理想解決方案。
RAG 的實際應用:對比分析
在以下所舉的例子中,比較了通用LLM (左)和經過RAG (右)增強的聊天機器人。左圖中,由於資訊過時或缺乏特定領域的知識,聊天機器人難以準確回答使用者的詢問。而RAG增強型聊天機器人能夠從上傳的檔中檢索最新資訊,提供準確且相關的回覆。
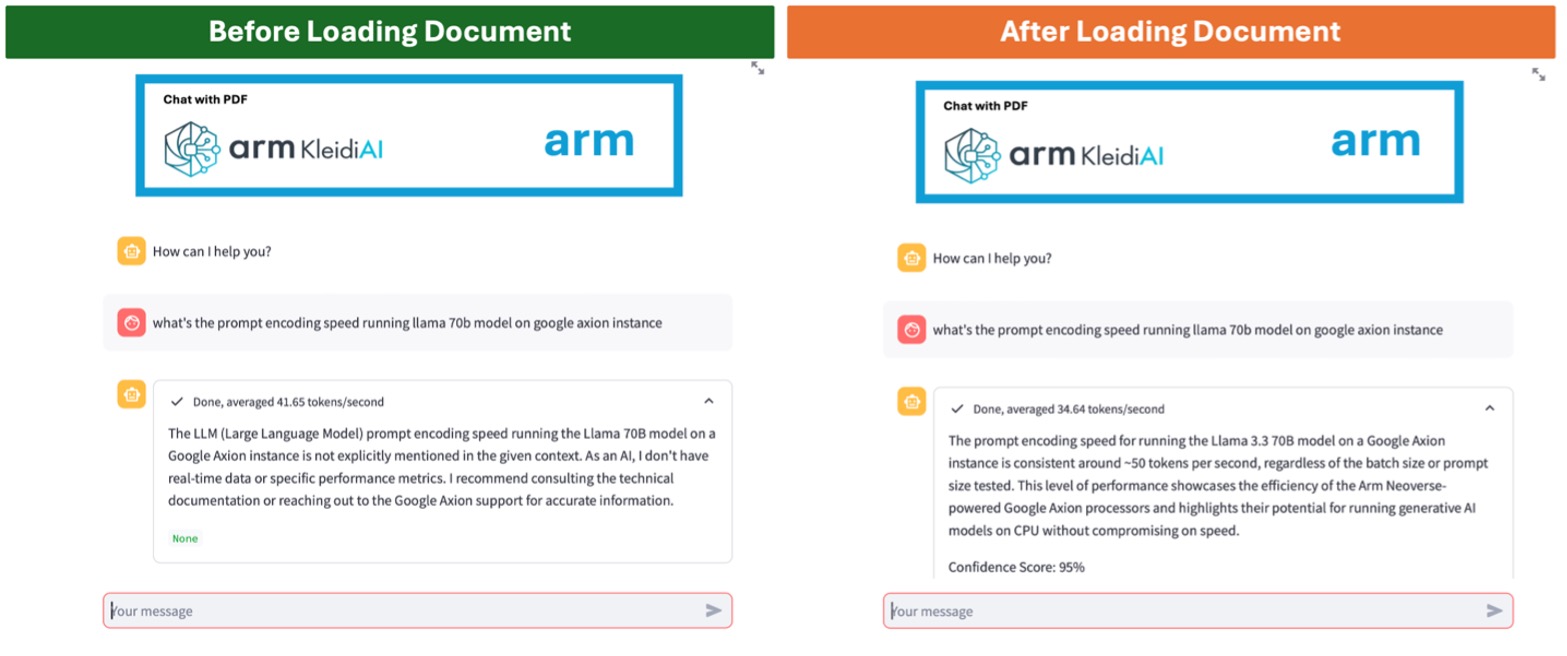
圖1:透過LLM實現的聊天機器人(左)和經過RAG增強的聊天機器人(右)
為何選擇Google Axion來實現RAG解決方案?
以Arm Neoverse平台為基礎的Google Axion處理器,為執行LLM的AI推論功能提供了理想平台,該處理器能夠以高效能和高效率支援RAG應用的運作。
最佳化AI加速:基於Neoverse平台的CPU具有高輸送量向量處理和矩陣乘法功能,這對於高效處理RAG十分重要。
雲端運算的效率和可擴展性:基於Neoverse平台的CPU可大幅地提高每瓦效能,在高速處理和能效之間取得平衡。因此,特別適用於需要在雲端快速推論並兼顧成本效益的RAG應用。基於Neoverse的處理器還可用於擴展AI工作負載,確保無縫整合各種RAG應用場景。
針對AI開發人員的軟體生態系:對於希望在基於 Arm 架構的基礎設施上運用最新 AI 功能的開發人員,Arm Kleidi技術能夠顯著提升RAG應用的效能和效率。Arm Kleidi已經整合到PyTorch、TensorFlow和llama.cpp等開源AI和機器學習(ML)框架中,使開發人員能夠實現立即可用的預設推論效能,而無需使用供應商的外掛程式或進行複雜的最佳化。
這些特性的結合帶來了顯著的效能提升,第一個基於Google Axion的雲端虛擬機器C4A與x86同類方案相比,大幅提升了基於CPU的AI推論和通用雲端工作負載的效能,使C4A虛擬機器成為在Google Cloud上運作RAG應用的理想選擇[1]-[2]。
Google Axion效能基準測試:更快的處理速度與更高的效率
使用 RAG 系統進行推論涉及兩個關鍵階段:資訊檢索和生成回應。
- 資訊檢索:系統搜索向量資料庫,根據使用者的查詢找到相關內容。
- 生成回應:檢索到的內容與使用者查詢相結合,生成與上下文相關的準確回覆。
一般來說,檢索速度取決於資料庫的大小和搜索演算法的效率。在基於Neoverse平台的CPU 上執行時,經最佳化的演算法可在幾毫秒內回饋結果。然後,將檢索到的資訊與使用者的輸入相結合,建構新的提示詞,並將其發送給LLM進行推論和生成回應。相較於檢索階段,生成回應階段耗時更長,RAG系統的整體推論延遲在很大程度上受LLM推論速度的影響。
我們使用llama.cpp基準和Llama 3.1 8B模型(Q4_0 量化方案)評估了多個Google Cloud虛擬機器的RAG推論效能。使用48個執行緒進行了所有測試,輸入大小為2058的詞元(token),輸出詞元大小為256。以下是測試配置:
Google Axion (C4A, Neoverse V2): 在 c4a-standard-48 執行個體(instance,編按:或譯為「實例」)上進行了評估。
Intel Xeon (C4, Emerald Rapids): 在c4-standard-48上進行了效能測試。
AMD EPYC (C3D, Genoa): 在啟用48個核心的c3d-standard-60上進行了測試。
更快的處理速度與更高效率
推論效能根據提示詞處理速度和詞元生成速度來測定。圖表1的基準測試結果顯示,與當前一代x86架構的執行個體相比,基於Google Axion的C4A虛擬機器在提示詞處理和詞元生成方面實現高達2.5倍的效能提升。

圖表1:執行Llama 3.1 8B/Q4模型時,提示詞處理(左)和詞元生成(右)與當前一代x86執行個體的效能比較。
成本效益:降低RAG推論成本
為了評估推論任務的執行個體成本,我們測量了從提交提示詞到生成響應的延遲。有幾個因素會影響延遲,包括檢索速度、提示處理效率、詞元生成速率、輸入和輸出詞元大小,以及使用者批次處理規模。由於資訊檢索延遲通常在毫秒級,與其他因素相比可以忽略不計,因此未納入計算。我們選擇的批次大小為 1,以確保在單個使用者級別進行公平的比較。
為了與基準測試保持一致,我們將輸入和輸出詞元大小分別設置為2048和256。我們首先透過提示詞編碼速度和詞元生成速度,計算提示詞處理和詞元生成的延遲,然後根據Google Cloud上的執行個體定價圖表[3]計算每次請求的成本,然後將這些數字歸一化為所有三個執行個體的最大成本。圖表2中的結果顯示,基於Axion的虛擬機器可節省高達64%的成本,處理每次請求所需的成本僅為當前一代x86執行個體的三分之一左右。
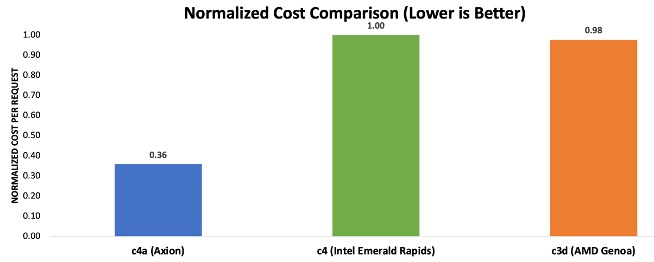
圖表2:使用RAG處理推論請求的歸一化成本對比。(備註:成本計算基於截至2025年3月5日公佈的執行個體定價,可參見:https://cloud.google.com/compute/vm-instance-pricing)
快速入門:在Arm平台上建構RAG應用
以Neoverse平台為核心,由Google Axion驅動的執行個體能以更低的成本提供高效能,協助企業建構可擴展且高效的RAG應用,同時與x86方案相比,顯著降低了基礎設施開支。
為了幫助開發人員快速入門,Arm 開發了逐步示範和LearningPath 教學課程[4],以便開發人員使用自己選擇的LLM和資料來源建構基本的RAG系統。
準備好開始了嗎?
- 試試我們的示範並跟著我們的Learning Path 教學課程,在基於 Arm 架構的 Google Axion 處理器上體驗 RAG
如果您才剛剛開始接觸 Arm 生態系,以下資源將協助開發人員順利開展旅程:
- 透過Arm Learning Path遷移到Axion:依照詳細的指南和最佳做法,簡化向 Axion 執行個體的遷移過程。
- Arm Software Ecosystem Dashboard:立即了解Arm平台可支援的最新軟體資訊。
- Arm 開發人員中心:無論是剛剛接觸Arm平台、還是正在尋找資源來開發高效能軟體解決方案,Arm開發人員中心應有盡有,可以幫助開發人員建構更好的軟體,為數十億個裝置提供豐富的體驗。在Arm不斷壯大的全球開發人員社群中,開發人員可以存取資源、交流學習和提問探討。
即刻展開你的遷移之旅,利用Arm Neoverse平台釋放雲端和AI工作負載的全部潛力!
參考資源:
- Google Axion處理器現已在Google Cloud全面上線,詳見: https://cloud.google.com/blog/products/compute/try-c4a-the-first-google-axion-processor
- https://community.arm.com/arm-community-blogs/b/servers-and-cloud-computing-blog/posts/ai-inference-on-google-axion-cpu
- https://cloud.google.com/compute/vm-instance-pricing(截至 2025 年 3 月 5 日)
- https://learn.arm.com/learning-paths/servers-and-cloud-computing/rag/
(參考原文:Harness the Power of Retrieval-Augmented Generation with Arm Neoverse-powered Google Axion Processors;本文英文版原文共同作者為Arm首席機器學習解決方案架構師Na Li及Arm終端產品事業部產品行銷資深經理Koray Ozkal; 中文版校閱者為Arm 主任應用工程師林宜均)
- 【Arm的AI世界】按步驟學習在Arm Ethos-U85上部署PaddlePaddle模型 - 2026/07/08
- 【Arm的AI世界】打造車用裝置端多模態助理 - 2026/06/16
- 【Arm的AI世界】運算平台開發者必看:無須硬體也能進行OpenBMC+UEFI模擬與驗證! - 2026/04/09
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


