「真正的文件理解,不只是把圖片轉成文字,而是讓模型能『看懂』文件背後的語意與邏輯。」
隨著生成式人工智慧快速滲透至各行各業,文件理解(Document Understanding)這一領域正迎來一場變革。從最早的光學文字辨識(Optical Character Recognition;OCR),到如今能同時理解文字、圖像甚至排版結構的多模態模型,AI 正讓文件的「可讀性」從人類專屬,轉向機器共通。
本文將針對兩個代表性模型做個比較,它們分別是OpenAI 的 GPT-5,以及來自中國團隊的 DeepSeek-OCR。前者以跨模態理解的深度與語意推理著稱,後者則以極致的文件精讀能力與高效率 OCR 表現贏得開發者青睞,兩者正代表了 AI 文件理解的兩條主流技術路線。
GPT-5:跨越語言與視覺的邊界
GPT-5 的誕生,意味著 OpenAI 在多模態人工智慧上的新里程碑。相較於 GPT-4,這一代模型的最大特點在於整合性的多模態結構。當使用者上傳一份含有表格、圖表與手寫註解的文件時,GPT-5 不僅能辨識內容,更能「理解」文件意圖,例如自動解析報告邏輯、歸納重點段落,甚至生成結論摘要。
與過去僅靠 OCR 提取文字的模型不同,GPT-5 的強項在於「語境推理」。當一份財報圖表中出現營收趨勢線,模型能根據旁邊的文字註解與時間軸推斷其含義,並延伸出語義層次的總結。這種能力讓 GPT-5 在商業報告分析、合約審閱、自動知識萃取等應用中展現驚人表現。
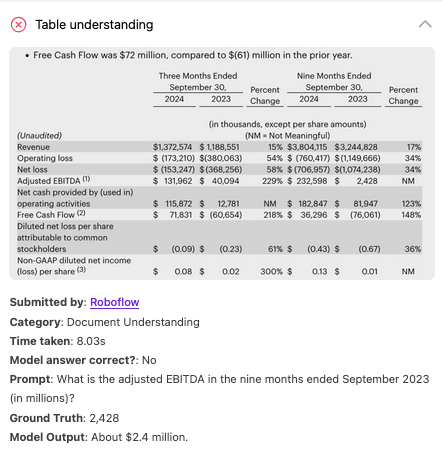
透過GPT-5詢問表單內容,得出正確解答(Source)
技術層面上,GPT-5 透過大規模的「視覺-文字對齊訓練」(Vision-Language Alignment),讓模型能將圖像特徵投影至語言空間,達到類似人類閱讀文件的理解方式。研究人員甚至觀察到,模型在多次反覆閱讀同一份文件時,會逐步形成「邏輯地圖」(logical map),自動捕捉段落關聯與重點詞彙,這讓它在處理長篇文件或跨頁內容時表現特別穩定。
DeepSeek-OCR:極致的文件精讀專家
與 GPT-5 的「通才」路線不同,DeepSeek-OCR 走的是極致專精的道路。這款模型原先只是高效文字辨識器,如今已演進成一套完整的文件理解系統。它不只辨識文字,更能重建文件的排版結構、表格欄位、圖片關聯與上下文意義。
DeepSeek-OCR 特別針對中文場景進行優化,能處理複雜的手寫字、票據、掃描文件與混合語言文本。這使得它在金融、政府與教育領域迅速普及。例如,企業可用它自動擷取發票與報表欄位,法院可自動整理判決書與證據資料,出版社則能利用它將歷史文獻轉化為可搜尋的數位文本,也可將印刷內容自動生成數位版本(如下圖):

在架構設計上,DeepSeek 採用「結構化 OCR + 語義建模」的混合策略。前端的 OCR 模組負責高速、準確的文字定位與轉換,後端的語義層模型則利用 Transformer 架構解析段落關係、摘要與標題層級。這種「先還原,再理解」的流程,使 DeepSeek-OCR 在真實文件處理中表現穩健,尤其對於多欄位排版或複雜表格結構的文檔,其準確度明顯高於傳統 OCR 系統。

DeepSeek-OCR技術架構(source)
有趣的是,DeepSeek 團隊並未追求與 GPT 系列相同的語言生成能力,而是更注重「可控性」與「可驗證性」。換言之,使用者可以在文件理解的每個階段檢視模型結果、手動修正或指定輸出格式。這讓 DeepSeek-OCR 更適合需要合規與精準度的應用場景,例如政府文件數位化或金融監理報告。
文件理解的哲學:通才對專家的較量
若以人類學習作比,GPT-5 像是博學的語言學家,而 DeepSeek-OCR 則像是專注於古籍校勘的學者。前者強調語境推理與語言生成,後者講究精確還原與結構重建。
這樣的分野,也映照出 AI 多模態發展的兩條技術哲學:語意導向(Semantic-first) 與 結構導向(Structure-first)。OpenAI 的 GPT-5 代表前者,它讓模型先理解語義、後再構建視覺資訊;DeepSeek 則走相反方向,先捕捉文件結構,再延伸語意解讀。兩者在最終輸出結果上可能相似——都能回答「這份文件在說什麼」——但背後的思維路徑卻截然不同。
這種差異,在實務應用上產生了明顯的效果分工。當使用者需要分析一份多語言報告、理解文字之間的隱含關聯時,GPT-5 的語意模型優勢無可取代;但若任務要求格式精準、欄位嚴格,例如OCR轉換發票、表格對齊等場景,DeepSeek-OCR 的穩定性與精度則更勝一籌。
從技術到應用:誰能定義下一代文件智慧?
目前,兩者的應用場景正在逐步交集。OpenAI 近期在 ChatGPT 的「文件上傳」功能中引入更強的表格與圖像解析能力,能直接理解 PDF 中的報表、圖片與註解。DeepSeek 則透過 API 與開源生態,讓開發者能在輕量化環境下整合文件理解模組。這意味著,文件 AI 的未來可能不是「一統天下」,而是「各擅勝場」。
更值得注意的是,兩者的發展方向正逐步靠近。OpenAI 開始強化 GPT-5 的結構辨識精度,而 DeepSeek 正積極引入生成式語言模型(LLM)模組,嘗試跨出 OCR 的框架,進入語義推理的領域。未來的文件理解,或許將結合二者的優勢:既能看懂格式,又能理解意圖。
小結
從打字稿到掃描件,從 OCR 到 GPT-5,多模態 AI 的發展已讓「閱讀」這一人類專屬的認知活動開始被機器共享。文件不再只是資料庫的輸入源,而成為能被理解、歸納與再創造的智慧載體。
正如一位研究員所說:「我們正在見證 AI 的識字革命。」GPT-5 讓機器能像人一樣閱讀思考,DeepSeek-OCR 則讓它能像專家一樣細讀分析。當這兩條路線最終在未來某處匯合時,AI 也許將真正學會「閱讀世界」。
(責任編輯:歐敏銓)
》延伸閱讀:
GPT-5 for Vision: Results from 80+ Real-World Tests
DeepSeek-OCR: Contexts Optical Compression(技術論文)

- 【Podcast】AI 機器人安全革命:從功能安全到軟體定義安全 - 2026/04/10
- RISC-V技術成熟度與全球AI落地應用現況剖析 - 2026/04/10
- 宇樹、智元出貨囊括八成 預估2026年中國人形機器人產量年增94% - 2026/04/09
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


