作者:陸向陽
OpenAI ChatGPT的爆紅給Google帶來警訊:倘若未來人們都不再使用搜尋引擎,改用ChatGPT詢問問題,未來網路廣告的撮合業務將轉往ChatGPT,為此Google在2023年3月提出Bard試圖抗衡ChatGPT,但很快在同年底推出Gemini取代Bard來抗衡ChatGPT。
Gemini改版快速,2024年2月推出1.5版,2025年1月推出2.0版,4月推出2.5版,但在推出2.0版後,或許受NVIDIA倡議Physical AI的影響,Google以2.0版為基礎衍生發展出Gemini Robotics模型,Gemini Robotics 1.0於2025年3月發表,版本一樣快速推進,9月推出1.5版。
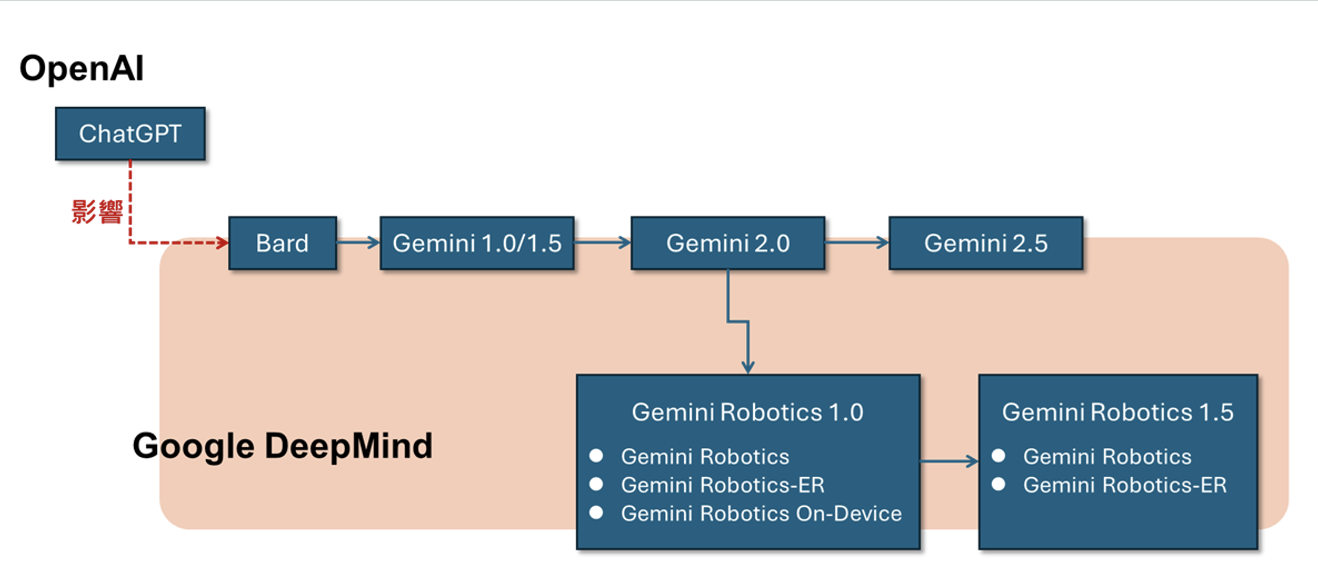
圖1:Gemini Robotics模型淵源圖(圖片來源:陸向陽)
Gemini Robotics 1.0/1.5其實是兩個AI模型,一個是Gemini Robotics,另一個是Gemini Robotics-ER,ER是Embodied Reasoning,中文目前翻譯成具身推理,目前LLM/GenAI開始強調導入推理(Reasoning)機制,使模型更具智慧性,推理是在過往單純的推論引擎(Inference Engine)前再加入一個知識庫(Knowledge Base),使推論能更了解一些事物間的關係性。
推理、知識庫只是一個概念,推理其實還可區分多種,如溯因推理(Abductive Reasoning)、代理推理(Agentic Reasoning)等,如此有十餘種,具身推理也是其一,具身推理適合用於自駕車之類的應用情境,當然也包含在真實世界移動或操作的機器人。知識庫也有知識圖譜(Knowledge Graphs)、本體論(Ontologies)、語義網絡(Semantic Networks)等。
回歸到Gemini Robotics,無論是Gemini Robotics或Gemini Robotics-ER其實都是多模態(Multimodal)模型,即輸入的內容型態不限一種,而是可同時兩種或兩種以上的輸入,例如Gemini Robotics可同時接受影像與文字的輸入,Gemini Robotics-ER可同時接受影像、影片、文字等輸入。
輸入多模態,但輸出不同,Gemini Robotics-ER是一個VLM(Vision-Language Model)型態,給予圖片、影像、文字輸入後輸出是一堆文字,但是是模型推理消化後產生的文字。
至於Gemini Robotics則是一個VLA(Vision-Language-Action)模型,給予圖片、文字輸入後會產生動作,所謂的動作其實是馬達的各種操控命令,命令用於驅動機器手臂或人形機器人實際動作。
說到此各位或許已經猜到,Gemini Robotics-ER形同大腦,用於理解外部空間現況等,然後產生文字,文字再輸送給Gemini Robotics,由其產生需要的外部對應動作,Gemini Robotics形同神經、中樞系統。
無論是Gemini Robotics或Gemini Robotics-ER,Google DeepMind團隊(即Gemini Robotics開發者)為了彰顯其1.5新版模型的優異性,均端出了標竿測試數據,例如Gemini Robotics 1.5版比此前的1.0版、On-Device版(2025年6月推出的一個本機端版本,優點是不用連網,缺點是表現較受限)更好,或者Gemini Robotics-ER在具身推理學術標竿測試上居於領先。
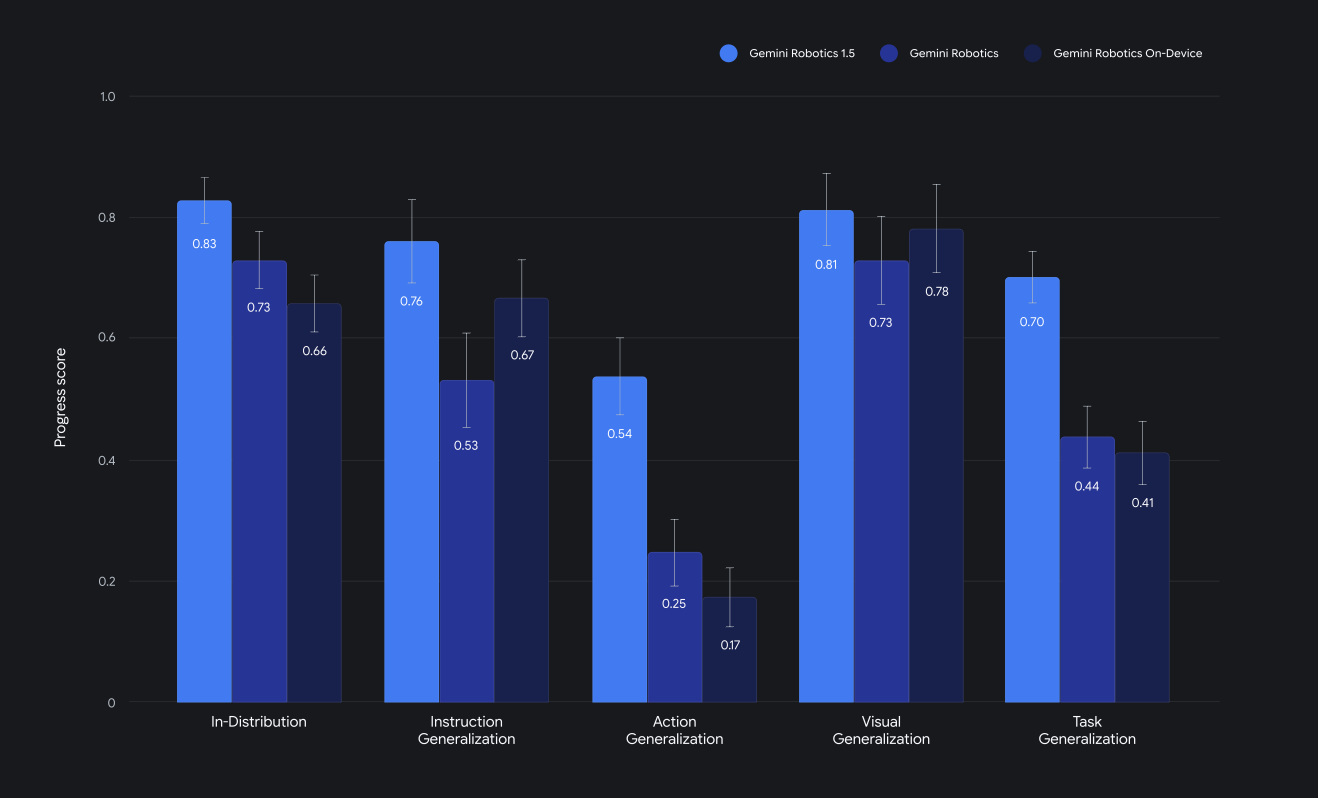
圖2:Gemini Robotics 1.5版模型勝過1.0版、On-Device版(圖片來源:Google DeepMind)
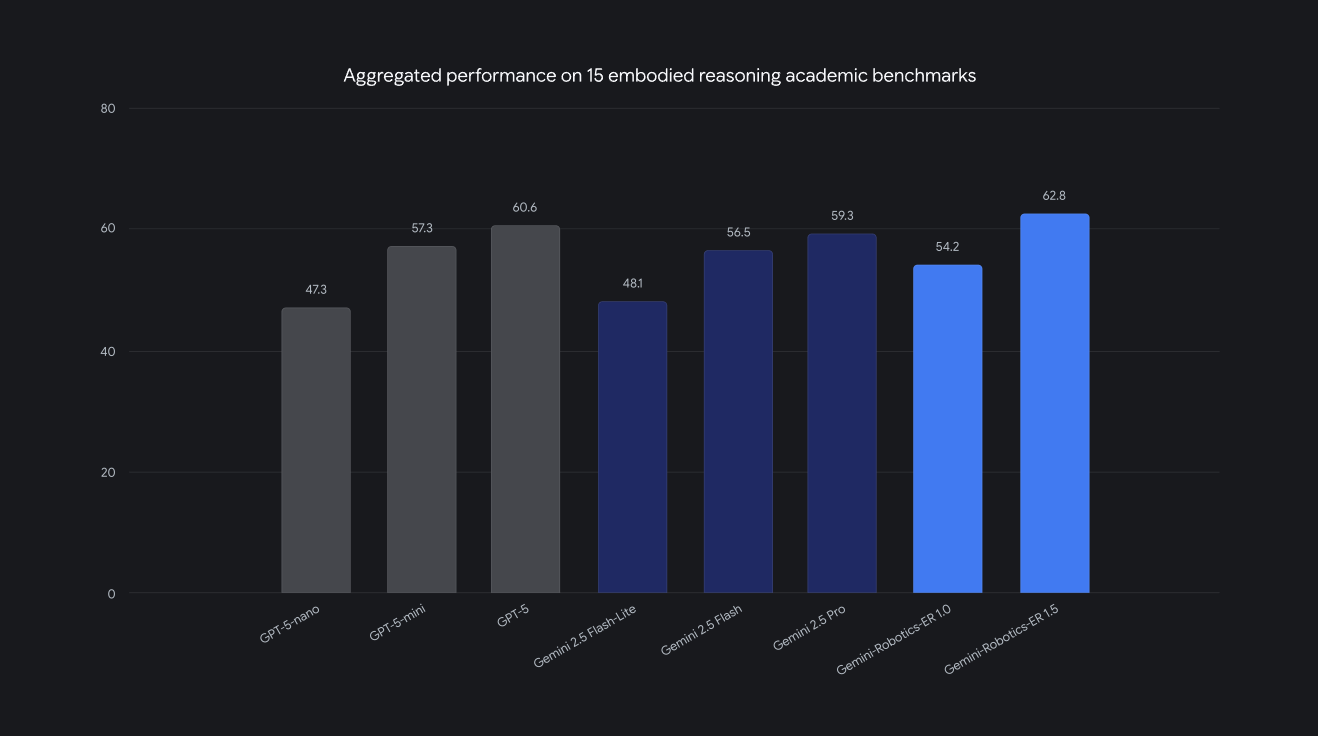
圖3:Gemini Robotics-ER在具身推理學術標竿測試上居領先性(圖片來源:Google DeepMind)
既然Gemini Robotics是輸出馬達控制訊號,那麼一般人拿到模型但卻沒有機器人、機械手臂也是沒用,因此Gemini Robotics 1.0/1.5目前是只給技術合作夥伴,沒有開放一般使用,Google方面是與9家業者合作,如Agility Robotics、Apptronik、Boston Dynamics、Agile Robots、Enchanted Tools、PAL Robotics、Rainbow Robotics、Collaborative Robotics、Universal Robots等。
如果不是這9家又想參與Gemini Robotics 1.5,Google也提供登記等待名單,Google方面審核後或許會接納,或者也可以先體驗看看Gemini Robotics On-Device(基於1.0版),也可以申請Gemini Robotics SDK軟體開發套件,一樣要排隊審核等候。
至於Gemini Robotics-ER 1.5因為是多模態進、文字出,所以Google開放可直接線上體驗,可以直接到Google AI Studio(簡稱AIS)體驗。
圖4:Google AI Studio可用來與Gemini Robotics-ER互動體驗(圖片來源:Google)
最後,其實Google期望透過Gemini Robotics系列模型實現真實世界的通用人工智慧(Artificial General Intelligence,AGI),所謂AGI是與窄人工智慧(Artificial Narrow Intelligence,ANI)相對的概念。
ANI的一個模型只能一種人類的簡單智慧表現,例如訓練出一個只能識別車牌的模型,但該模型無法識別車輛類型(卡車、汽車),必須再訓練另一個模型來識別車輛類型,或再訓練一個模型來識別車輛顏色等,過往的AlexNet只能用於相片分類、AlphaGo只能用來下圍棋,相互無關。
而AGI是一個模型就具有接近人類的多重智慧,畢竟一個真實的人的腦既可相片分類也能下圍棋,而多模態、推理等機制可以說是邁向AGI的一個必要技術歷程。AGI也是目前OpenAI積極參與Stargate星際之門專案投資的原因,OpenAI期望透過更龐大的運算力來練就AGI。
AGI其實難以一步實現,Gemini Robotics也只是真實物理層面的AGI,而非全方位的AGI,OpenAI執行長Sam Altman提出實現AGI的五步驟,其中即包含推理(Reason)、代理(Agent)技術。
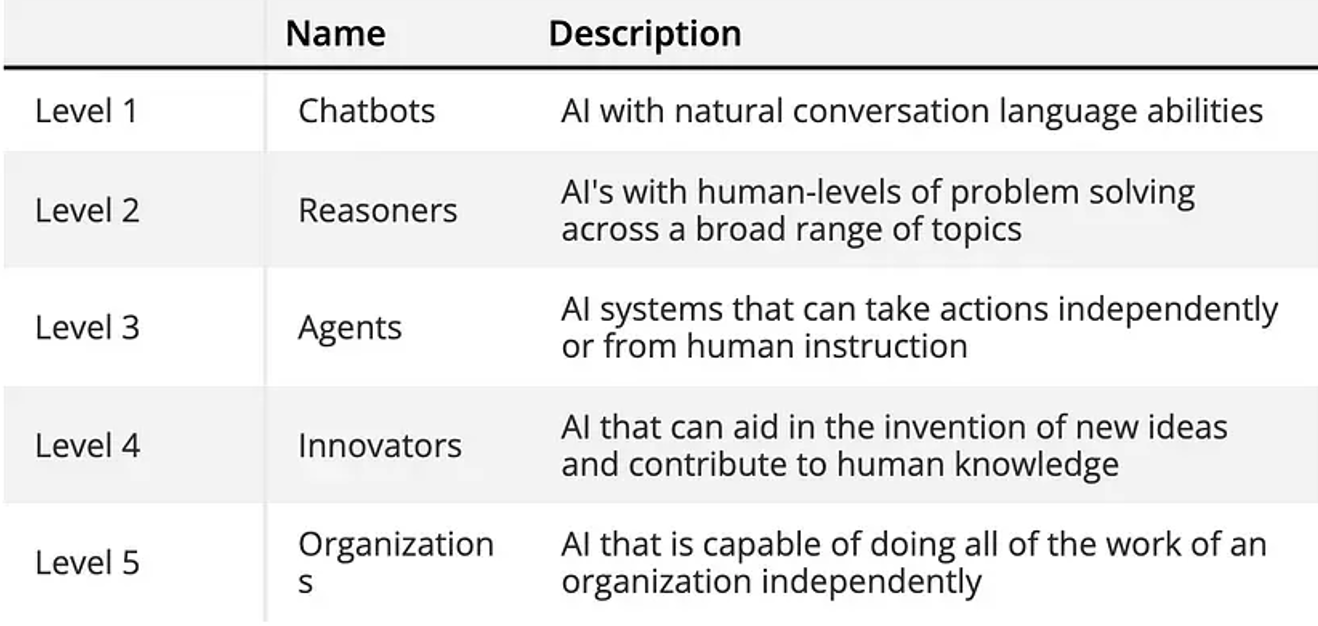
圖5:實現完整AGI的五個層次(圖片來源:Arnaud Stevins)
更往後看,人們正設想超人工智慧(Artificial Super Intelligence,ASI),即一個模型就能超越一個人、一群人,成為意見領袖,但這只是預先設想,從未實現過,且有點科幻,眼前實現物理世界的AGI,是Gemini Robotics希望實現的,此值得期待。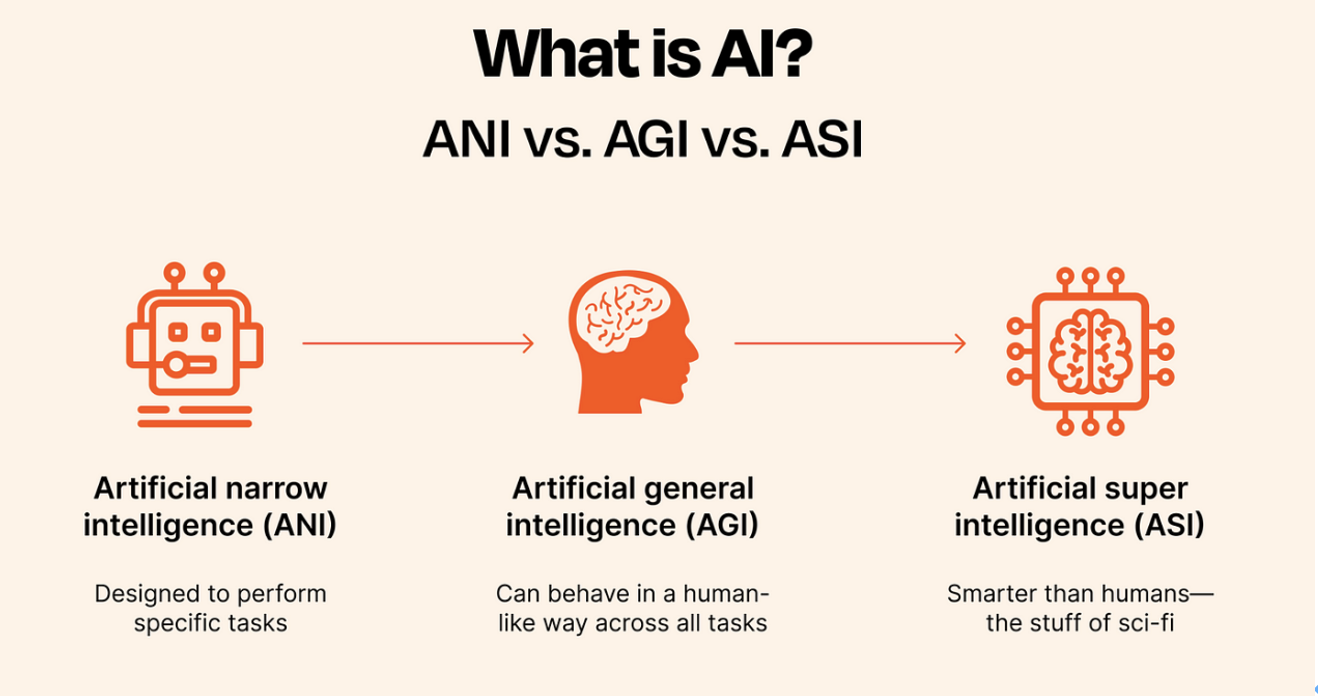
圖6:ANI、AGI與ASI差異圖(圖片來源:Shikhar Pandey)
延伸閱讀
- Gemini Robotics 1.5: Using agentic capabilities(Gemini Robotics 1.5應用示範影片,實現垃圾分類、打包行李、回應氣候問題,英文)

- 小孩才選擇!Arduino VENTUNO Q全都要 - 2026/03/26
- 樹莓派也能「養龍蝦」! - 2026/03/24
- Windows PC上安裝PicoClaw最基礎實務 - 2026/03/03
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!