作者:歐敏銓
AI能看到眼前的世界,並推測下一秒將會發生什麼?Meta最新發表的 V-JEPA 2 世界模型,正是向這個方向跨出關鍵一步——它不只是辨識影像,而是理解因果、預測未來,甚至在陌生環境中替機器人規劃行動。
喜歡用聽的?可收聽本文Podcast的精采對話喔(by GenAI):
從人類的物理直覺,到AI的世界模型
認知科學早已揭示,人類的學習過程,本質上是對「未來」的預測遊戲。嬰兒在搖晃手裡的玩具時,不僅感受當下的聲音和觸感,也在猜測下一次揮動會發生什麼。成年後,我們能直覺判斷球滾到桌邊會掉落,而不需經過任何計算。
這種建立在觀察與經驗之上的「物理直覺」,是人類與生俱來的生存工具。它的核心,是一個內建的「世界模型」——我們在心裡模擬世界的運作,推演行動的後果,再決定下一步要做什麼。
V-JEPA 2 的目標,就是把這種能力複製到人工智慧中。對Meta AI掌門人、圖靈獎得主 Yann LeCun 而言,這不僅是技術挑戰,更是對當前AI發展路線的一次「反叛」。
LeCun的異議與賭注
在生成式AI爆紅的今天,大型語言模型(LLM)主宰了輿論與資金流向。但LeCun一直直言,僅憑文字與圖像生成,AI無法真正「理解」世界。它們雖然能對提問給出看似合理的回答,卻缺乏對物理現實的感知與推理能力。
他認為,智慧的核心不在於對像素或文字的模仿,而在於抽象層級的理解與預測。V-JEPA 2正是這一理念的實驗場:它放棄了在像素層級重建畫面,而是學會在高層次的「語意表示空間」中進行推演。
「與其預測影片中每個像素的變化,不如學會在抽象層面理解事件的因果與動態,這才是智慧的基礎。」LeCun說。

Yann LeCun在這支影片中說明了世界模型的重要性(影片請見本網頁)
V-JEPA 2是怎麼學會「預測」的?
V-JEPA,全名 Video Joint Embedding Predictive Architecture,是一個專為影片環境設計的世界模型。它的核心訓練過程分為兩大階段,結合了海量的自我監督學習與針對機器人控制的微調:
第一階段:自我監督的影片預訓練
模型先「看」超過一百萬小時的線上影片,以及大量靜態圖片。透過一種名為「遮蔽潛在特徵預測」的技術,V-JEPA 2學會在不完整的影像片段中,推測被遮蔽的動態與結果。例如,看見球滾動到桌邊的片段時,它能在心中「補齊」球掉下去的情景。
(source)
第二階段:少量機器人資料的微調
接著,V-JEPA 2只用了來自 Droid 開放資料集、不到62小時的機器人影片,就學會了如何在現實環境中操控機械手臂。它會根據任務目標生成路徑,並在執行過程中不斷預測下一步的可能結果,根據情況動態調整策略。
這種訓練方式打破了傳統依賴大量專家示範資料的做法,讓機器人在零樣本(Zero-Shot)條件下,也能在新場景中完成任務。
(source)
從理解影片,到控制機械手臂
在Meta的測試中,V-JEPA 2展現了令人驚訝的泛化能力。在兩個互不相同的實驗室環境裡,它被直接部署到Franka機械手臂上,沒有針對這些場景做過任何訓練,也沒有收集額外數據。
結果,它在「抓取與放置」任務中達到65%至80%的成功率——對於一個從未見過該環境的模型來說,這幾乎是人類等級的適應力。
它的規劃過程也極具啟發性:
- 先把當前畫面與目標畫面轉換成抽象的語意嵌入
- 在表示空間中模擬多組可能的動作序列
- 透過「模型預測控制」(Model-Predictive Control, MPC)挑選最佳路徑
- 對於需要多步驟的長程任務,則拆解成多個子目標,逐一完成
換句話說,V-JEPA 2並不是死記硬背任務流程,而是「先想像再行動」。
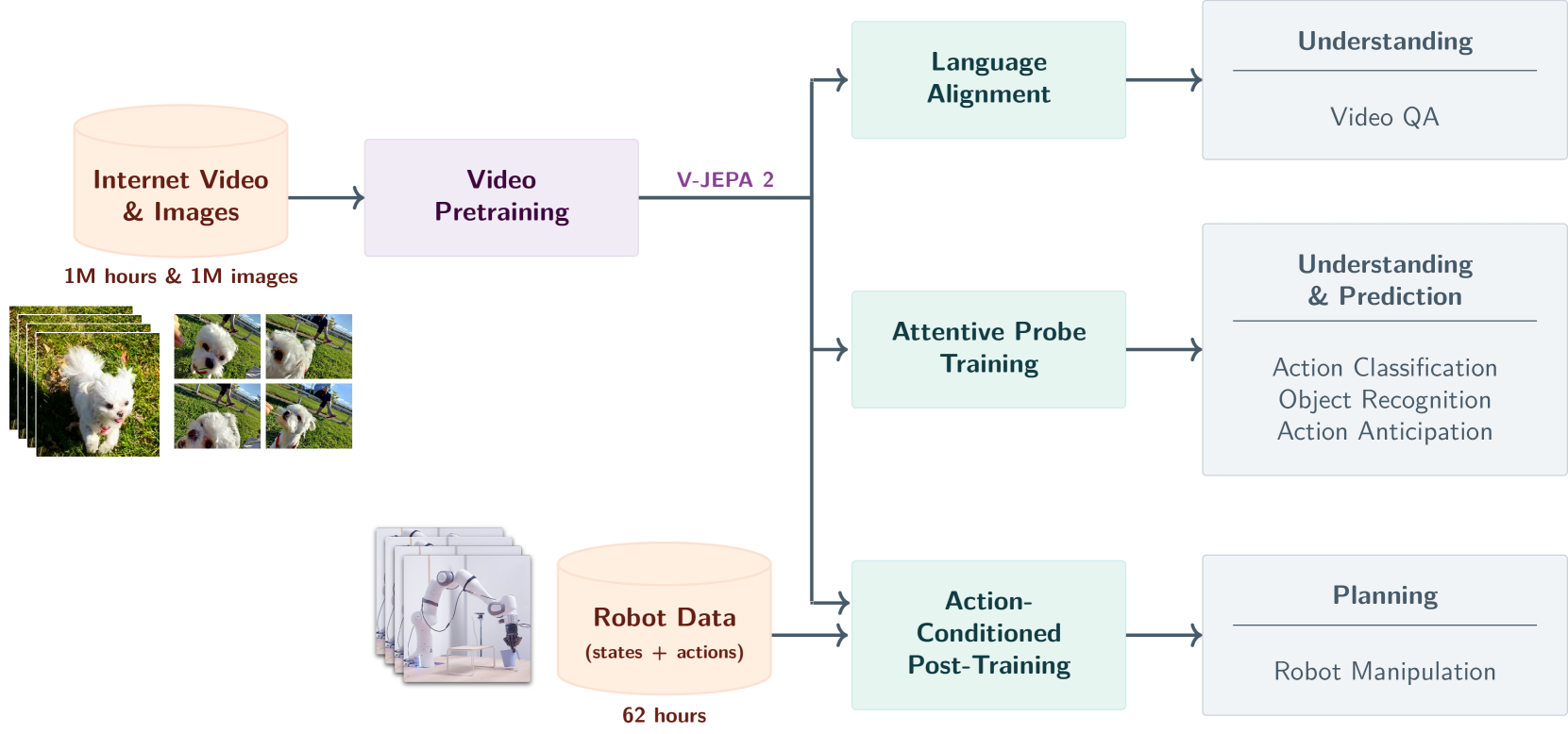
V-JEPA 2 利用 100 萬小時的網路規模視訊和 100 萬張圖像,使用視覺掩模去噪目標對 V-JEPA 2 視頻模型進行了預訓練,並透過將該模型與 LLM 主幹模型對齊,將其用於動作分類、物體識別、動作預測和視訊問答等下游任務。預訓練之後,還可以凍結視訊編碼器,並在學習到的表徵基礎上,使用少量機器人互動資料訓練一個新的動作條件預測器,並利用該動作條件模型 V-JEPA 2-AC,在模型預測控制迴路中進行規劃,完成下游機器人操控任務。(source)
(source)
挑戰物理與因果的極限測試
為了檢驗V-JEPA 2的能力,Meta還推出了三個全新的評測基準,專門測試AI在物理直覺與因果推理上的表現。
1. IntPhys 2
讓AI在兩段極為相似的影片中,判斷哪一段違反了物理定律——例如,物體無端漂浮或穿透牆壁。人類幾乎能100%識別,但多數AI模型的表現接近隨機猜測。
2. MVPBench
透過最小化視覺差異的影片對,檢驗AI是否能察覺細微變化背後的物理意涵。只有在兩段影片都答對時,才算通過。
3. CausalVQA
測試AI是否能回答涉及因果推論的問題,例如「如果A發生了,B還會發生嗎?」或「為了達到目標,下一步該做什麼?」
這些基準不僅揭示了V-JEPA 2的強項,也暴露了AI在物理與因果推理上的不足——尤其是在「推測可能發生什麼」與「規劃應該怎麼做」上,仍落後於人類。
世界模型的下一站
V-JEPA 2的誕生,讓「讓AI擁有世界模型」這個概念,從學術理想走向可驗證的成果。但LeCun與Meta的團隊顯然不打算就此止步。
未來,他們計劃推進:
- 分層時間規劃:讓AI同時理解短期與長期的事件結構,能像人類一樣制定跨多步驟的計劃。
- 多模態感知:將視覺與聽覺、觸覺訊號結合,讓AI對物理世界的理解更立體。
- 開源與社群合作:透過開放模型與基準數據,讓全球研究者共同驗證與優化V-JEPA 2。
這不僅是技術路線的延伸,更是對未來AI形態的探索——從純對話的生成模型,走向能觀察、能推理、能行動的智慧體。
結語
從一顆滾向桌邊的球,到一隻在陌生桌面上操作機械手臂的AI,V-JEPA 2的進步,不在於它能生成多麼華麗的畫面,而在於它學會了像人類一樣,在行動前先模擬未來。
這種能力,意味著AI正在跨越一條關鍵的鴻溝:從對世界的靜態描述,走向對世界的動態理解與改變。對機器人領域而言,這或許是通往人類級智能的一扇門;對AI研究本身,則是一次重新思考「智慧」真正含義的契機。
正如LeCun所言,「我們要的是能理解現實的AI,而不是只會編故事的AI。」V-JEPA 2或許還不完美,但它已經讓我們看見,AI的未來,可能比我們想像的更接近人類的思考方式。
》延伸閱讀:
Introducing the V-JEPA 2 world model and new benchmarks for physical reasoning

- 2026 Edge AI MCU技術趨勢與廠商方案現況比較 - 2026/03/12
- 大自然的逆向工程:Festo用20年打造的仿生螞蟻、蜜蜂與水母 - 2026/03/10
- 讓AI成為雨林金礦盜採防線:Amazon Mining Watch計畫介紹 - 2026/02/23
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


