當代大型語言模型(LLM)帶來突破性的語言理解與生成能力,但其龐大參數與計算成本對資源有限的部署環境造成挑戰。為此,技術發展著重於如何將這份智慧「濃縮」呈現,而蒸餾(Distillation)、模型壓縮(Compression)、與微調(Fine Tuning)成了最關鍵且彼此交織的三大技術路徑。
這三者技術既相互區隔又密不可分,蒸餾聚焦「智慧遷移」、壓縮專注「資源優化」、微調強調「專業提升」,合力推動語言模型在多樣應用環境的高效落地。本文將剖析它們在技術架構與應用場景中的定位與相互關聯,並以最新研究動態佐證業界趨勢與實務策略。
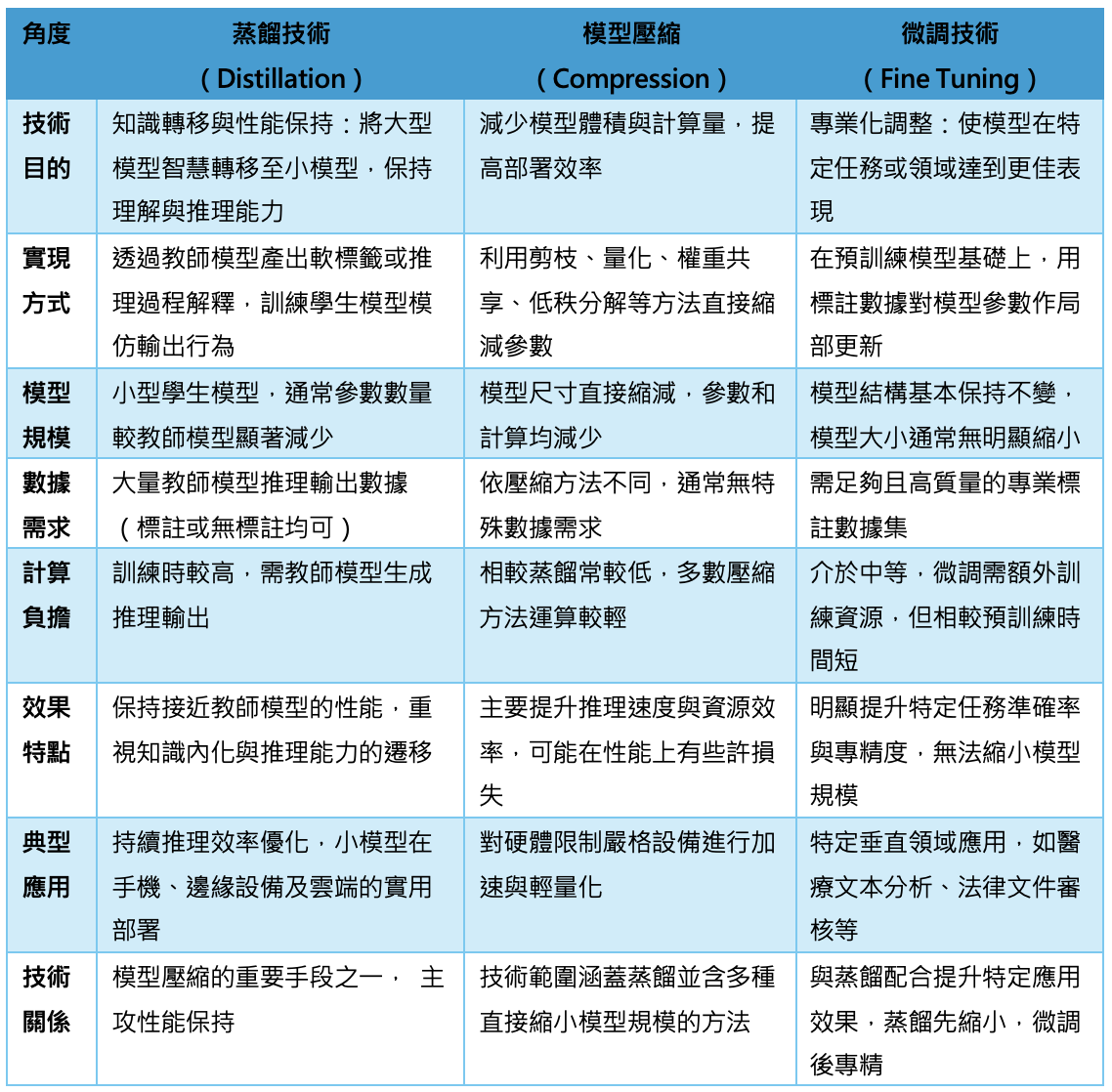
蒸餾、壓縮、微調技術比較表
LLM到SLM的關鍵技術:智慧濃縮的蒸餾法
大型語言模型因其龐大的參數量與訓練計算,雖達極佳自然語言理解與推理效果,但欠缺在移動端或邊緣設備上方便部署的靈活性。為此,從LLM(Large Language Model)縮減至小型語言模型(SLM,Small Language Model)成為研究重點,而「蒸餾技術」則是業界共認的核心手段。

蒸餾技術本質上是一個學生-教師框架。教師模型通常為性能卓越的大型模型,它先對大量輸入產生高品質推理結果及知識「標記」;學生模型隨後以此為訓練目標,模仿大型模型的行為。不同於傳統只靠標註資料微調,蒸餾能將大型模型內部抽象且複雜的推理機制「濃縮」,讓學生模型在參數與架構縮小數倍甚至數十倍的前提下,也能扛起大部分推理與語言理解任務。
更進階的研究如Google提出的「逐步蒸餾」(Distilling Step-by-Step),不僅把最終答案當作指標,更會抽取大型模型在推理過程中生成的自然語言解釋,再用這些中間步驟教導學生模型。此方法讓小模型學會多步邏輯推理,彷彿模仿教師模型「思考」的軌跡,不僅提升了模型的推理深度,也更有效降低對大量標註數據的依賴,使其在有限資料情況下超越以往微調效果,有時甚至超越部分大型模型。

Distilling Step-by-Step運作流程 (source)
總結來看,透過蒸餾,小模型能接近甚至超越以往需更大規模參數才有的卓越表現,同時達成推理延遲降低與部署成本可控的目標。如今多數語言模型實務部署方案的背後,蒸餾技術都是不可或缺的關鍵引擎。
蒸餾與模型壓縮:知識轉移與資源優化的協同策略
雖然在實踐中,知識蒸餾(Knowledge Distillation)與模型壓縮(Model Compression)常被並列討論,兩者卻非同義,而是一種技術內涵與目標的差異表現。
蒸餾重點在「知識轉移」
透過讓小模型模仿大模型對輸入所產生的輸出(特別是概率分佈,包含更多細節)來捕捉其內在智慧,使得小模型在縮小後仍能獲得過去需龐大參數方可達成的推理和理解能力。它可以視為性能保持的智慧濃縮,雖小模型通常較輕巧,但蒸餾本身未必直指「減少大小」,更多是「讓小模型變得更聰明」。
模型壓縮包含一系列「資源優化」技術
相較之下,模型壓縮是一系列「資源優化」技術的總稱,目標為直接降低模型的儲存與運算需求,使模型適合硬體限制嚴苛的環境,例如智慧手機或者嵌入式設備。
壓縮方法包含權重剪枝(去除不重要參數)、量化(減少數值精度)、權重共享(參數重複利用)、低秩分解(分解矩陣簡化計算)等多種途徑。值得注意的是,蒸餾技術本身被視為壓縮的子方法之一,尤其是對模型效能的輔助提升至關重要。
簡而言之,蒸餾是一種強調性能保持與知識內化的轉移技術,模型壓縮則聚焦於尺寸縮小與算法效率的提升。兩者可協同,先利用蒸餾讓小模型獲得教師智慧,再綜合其他壓縮技術完成輕量化部署,達成效能與資源消耗的最佳平衡。
蒸餾與微調:智慧縮小與專業化的雙重策略
再把視線切換到另一項重要技術——微調(Fine Tuning),它與蒸餾在技術定位上展現出不同的焦點及應用目的。
蒸餾的目的是將大模型的「智慧」和推理能力「縮小」、「轉移」到小模型。它強調的是縮小模型參數同時保留推理性能,為模型高效部署鋪路。而Fine Tuning是以預訓練好的模型為基礎,利用針對特定應用場景的標註數據,對模型進行「專精化調整」。微調不一定減少模型規模,但能使模型更精準地解決垂直領域問題,如醫療文本分類或法律文件解析。
這兩者在實務中並非對立,而是互補。理想流程往往是:先用蒸餾技術將大型模型智慧濃縮到小模型,提高小模型的基礎能力與效率,接著對該小模型進行微調,令其在具體領域或任務上表現更為出色。這樣,既達成部署的輕量化與經濟效益,又不犧牲特定應用的準確性與專業性。
從技術層面看,蒸餾關注的是「讓小模型變聰明」,突破大小模型的性能鴻溝;微調則是「讓模型更專業」,在特定環境下進行精准微調。細節上,蒸餾需要大量教師模型推理輸出做為指導且往往不依賴大量新標註數據,而微調則必須有標註且具代表性的數據。
結語
隨著語言模型的規模持續膨脹,如何將強大的自然語言理解與推理能力帶給更多應用場景,成為業界最重要的挑戰之一。在這場技術革命中,蒸餾技術的出現扮演了「智慧濃縮器」的角色,突破了大模型難以普及的瓶頸,讓小模型擁有接近大模型的「腦力」,成為部署在邊緣設備和移動端的實用利器。
與此同時,模型壓縮代表著深度優化資源利用的方向,蒸餾作為其中核心的知識轉移方法,與剪枝、量化等技術密不可分。另一邊微調則承擔起「專業化培育師」的職能,使模型在特定任務中更精準有效。三者的技術定位雖各有側重,卻共同構築起輕量、高效且專業的智能模型鏈條。
(責任編輯:歐敏銓)
》延伸閱讀:
Distilling step-by-step技術介紹(Google Research)

- 【產業觀察】Intel在VLA機器人市場的佈局與契機 - 2026/03/27
- AI如何讓機器人更有「人」味:跨越雙手協同鴻溝! - 2026/03/17
- 2026 Edge AI MCU技術趨勢與廠商方案現況比較 - 2026/03/12
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!



2025/08/21
讓外行人也可以看懂的好文章