2025 年 7 月底,來自舊金山的Deep Cogito 團隊推出新一代開源混合AI推論模型 —— Cogito v2。這是一次對推論邏輯與模型直覺的一大進展:從推論鏈(Reasoning Chain)的內化,到自我強化學習的落地,Cogito v2 為開源社群帶來了一種嶄新的 AI 發展路線,指向通用超級智能(General Super Intelligence)的未來。
技術定位:不只「大」,更是「聰明」
Cogito v2 系列共釋出四款模型,涵蓋中大型(70B、109B Mixture-of-Experts)及超大型(405B、671B MoE)兩個層級。其中,671B MoE 模型被視為全球最強的開源 AI 之一,不僅在標竿測試中追平 DeepSeek 最新版本,還逼近 OpenAI o3 與 Anthropic Claude 4 Opus 等封閉模型的表現。
但 Cogito v2 的核心突破並不僅僅來自參數規模,而是全新的訓練與推論模式:它嘗試將推理步驟「蒸餾」回模型參數,讓 AI 從被動的搜尋式推論,進化為主動的直覺式決策。這種內化策略,使其在推論鏈長度比 DeepSeek R1 短約 60% 的情況下,依然能保持甚至超越對手的精度與效果。

(source)
訓練創新:從推論到直覺
1. 疊代蒸餾與放大(IDA)
Cogito v2 的核心訓練機制是「Iterated Distillation and Amplification(IDA)」。簡而言之,先讓模型完整演練推論過程,將這段推論活動蒸餾到參數中,之後面對同類問題時,能直接跳過繁瑣步驟,以「直覺」得出高品質答案。這種方法在棋類與博弈 AI 已被驗證有效,如今被推廣至跨領域通用語言模型。
2. 雙線能力提升
在不同規模的模型中,Cogito v2 採取差異化訓練重點:
- 中大型(70B、109B MoE、405B Dense)專注於將推論模式的能力轉化為非推論模式下的直覺反應。
- 超大型(671B MoE)不僅強化直覺,更優化推論過程本身,獎勵高效決策,懲罰無效迂迴。
這種雙維訓練訊號避免了冗長推論路徑,使模型能在複雜問題中迅速找到正解。
技術細節與資源效率
Cogito v2 系列同時涵蓋 Dense(稠密)與 Mixture-of-Experts(專家混合)架構,對開源社群友好,並且訓練成本極低 —— 八款模型(3B 至 671B)總開銷不到 350 萬美元,遠低於主流 AI 巨頭動輒數千萬甚至上億美元的規模。
值得一提的是,即使僅用純文本訓練,Cogito v2 也展現了跨模態推論的潛力。例如,它能在無額外蒸餾的情況下比較兩張圖片的相同與差異點,為後續多模態訓練奠定了高起點。
性能與生態影響
在 Benchmark 測試中,Cogito 671B MoE 與最新一代 DeepSeek 模型平起平坐,並在推理與非推理模式下多次超越對手(見下圖)。更短的推論鏈意味著更快的響應與更低的運行成本,讓它在實際應用中具備明顯優勢。
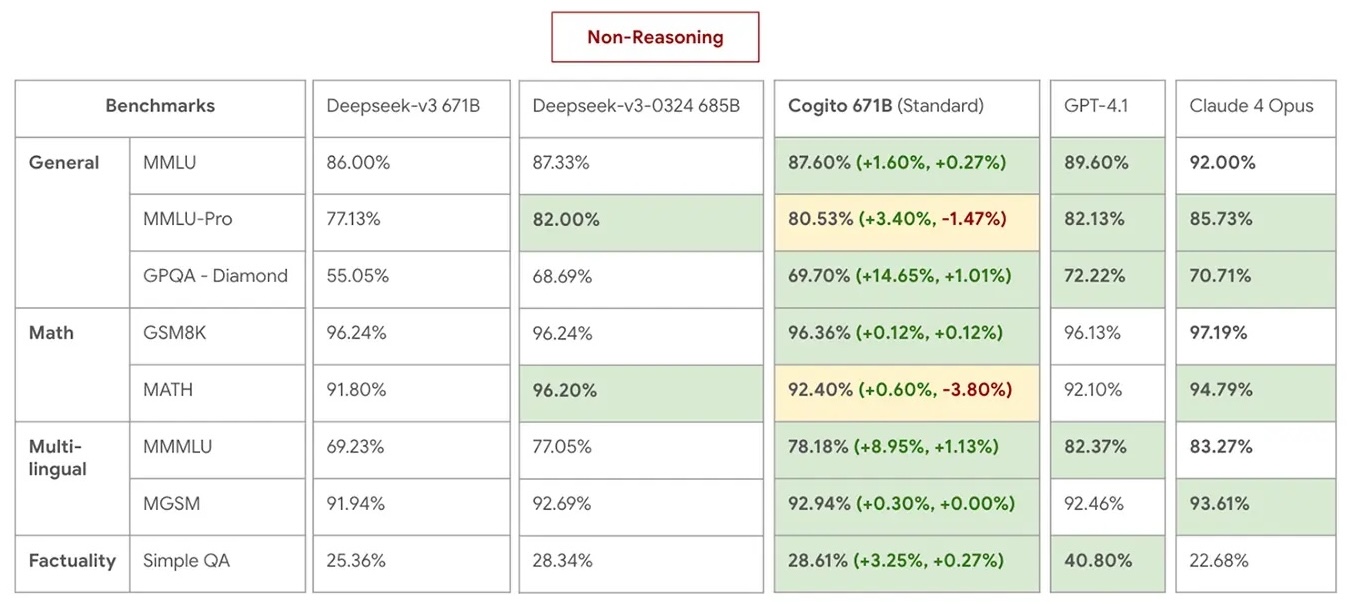
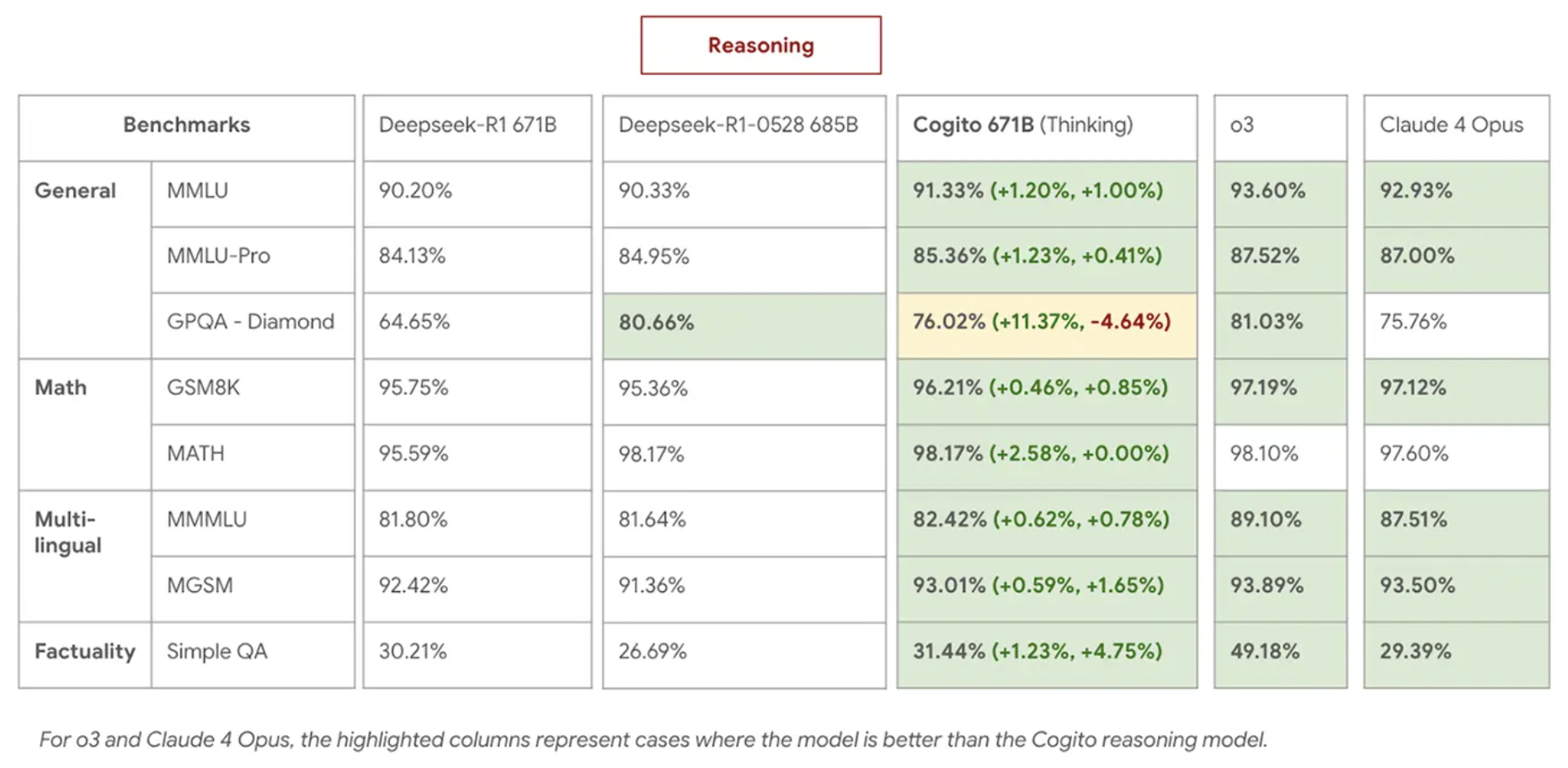
部署上,Cogito v2 可直接透過Together AI、Baseten或RunPod等平台接入,也能無縫在本地運行,降低使用門檻。所有型號完全開源,並整合 Hugging Face 等生態,促進開發者社群的快速迭代與落地應用。
展望
Cogito v2 的 IDA 技術開啟了 AI 自我優化的可能性,為「山丘攀爬式」智能提升提供路徑,有望突破依賴人類標註的瓶頸。它所展現的跨模態推理苗頭,也為未來的多模態 AI 與強化學習鋪平道路。
Cogito v2 的發布,意味著開源推論模型正式邁入「直覺時代」。它證明 AI 的進步不必依賴無限制地拉長推論鏈,而是可以透過內化與自我增強實現效率與精度的雙贏。
隨著規模擴張與多模態能力深化,Deep Cogito 旨在構建一個完全可持續的 AI 自我增強循環 —— 這不僅是前瞻技術的創新,也展現了開源專案的力量,更可能成為未來 AGI 發展歷程中的關鍵里程碑。
(責任編輯:歐敏銓)
》延伸閱讀:
[1] Cogito v2 Preview(官方資料)
[2] Deep Cogito v2: Open-source AI that hones its reasoning skills

- AI如何讓機器人更有「人」味:跨越雙手協同鴻溝! - 2026/03/17
- 2026 Edge AI MCU技術趨勢與廠商方案現況比較 - 2026/03/12
- 大自然的逆向工程:Festo用20年打造的仿生螞蟻、蜜蜂與水母 - 2026/03/10
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


