作者:Felix Lin
從Edge AI到AI PC
對於邊緣裝置應用的開發者而言,如何選擇合適的AI模型以及恰到好處的硬體,一直是個繁瑣且耗費時間與金錢的任務。選擇高階硬體規格將墊高成本,選擇低階硬體又擔心模型推論效能不佳,若將各等級的硬體都準備起來,不僅耗費金錢也花費逐一驗證的時間。有鑑於此,高通(Qualcomm)推出了AI Hub平台,提供了常見的預訓練模型,以及多面向的硬體裝置,開發者可以透過AI Hub將不同格式的模型實際載入到各不同晶片上進行推論,藉以快速評估出哪一個硬體平台適合團隊做採用。本篇筆者將以實作的方式操作AI Hub,並將最佳化的模型部署在Windows on Snapdragon AI PC上運行,體驗如何在短時間內完成AI應用的展示與評估。
在Windows on Snapdragon平台上的AI Stack架構圖如下,從最底層硬體提供了CPU、NPU與GPU等執行推論的實體,並且各自擁有相應的後端Backend低階Library 。在其之上使用的執行階段框架Runtime Framework則分為AI Engine Direct(又可稱 QNN SDK)以及ONNX Runtime。QNN SDK可以高度彈性的調配資源分配適合進階的開發者;而ONNX Runtime則是通用型的架構,讓入門開發者也能輕鬆駕馭,但也可別小看ONNX Runtime,目前已經也有針對CPU、QNN與DirectML的EP(Execution Provider),可以達到接近於QNN SDK 的效能!在上層則是模型格式,基本上只要是常見的ONNX、PyTorch、TensorFlow模型格式,都能經由轉換後載入Runtime進行推論,是否真有這麼簡單易用,接下來就跟著筆者一瞧端倪!
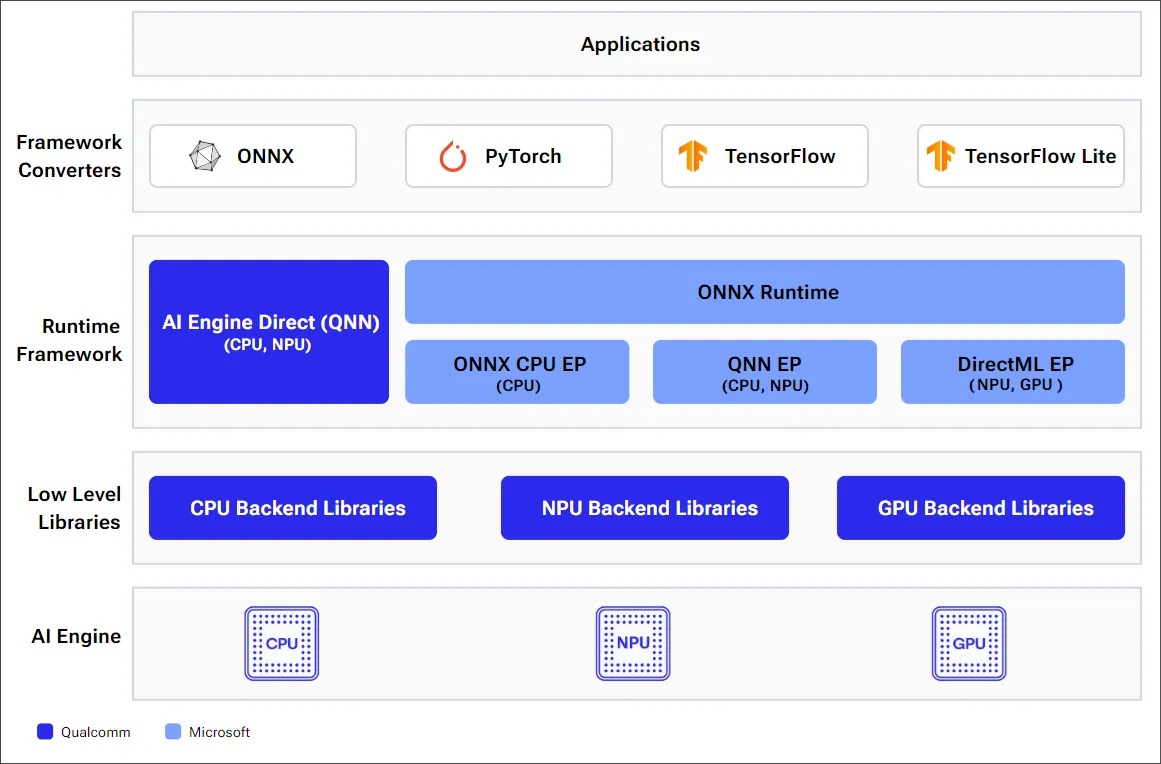
高通 WoS AI Stack 框架示意 (source: WoS Doc)
Qualcomm AI Hub
Qualcomm AI Hub是一個專為邊緣運算開發者所打造的AI模型開發平台,可以在幾分鐘內完成轉換、最佳化、驗證甚至是部署AI模型!最終幫助開發者將模型部署在 Snapdragon 的各式裝置如行動裝置、電腦、車載平台、物聯網設備等。目前 AI Hub 上提供超過 130 個預訓練模型(如下圖),類型涵蓋視覺、音頻、生成式、多模態等預訓練模型,除了線上評估模型效能外,還可以直接下載對應各高通晶片的模型直接使用。目前AI Hub模型仍然在持續增加中,若開發者找不到合適的對應模型,也可以自行使用AI Hub工具進行雲端的轉換與評估。
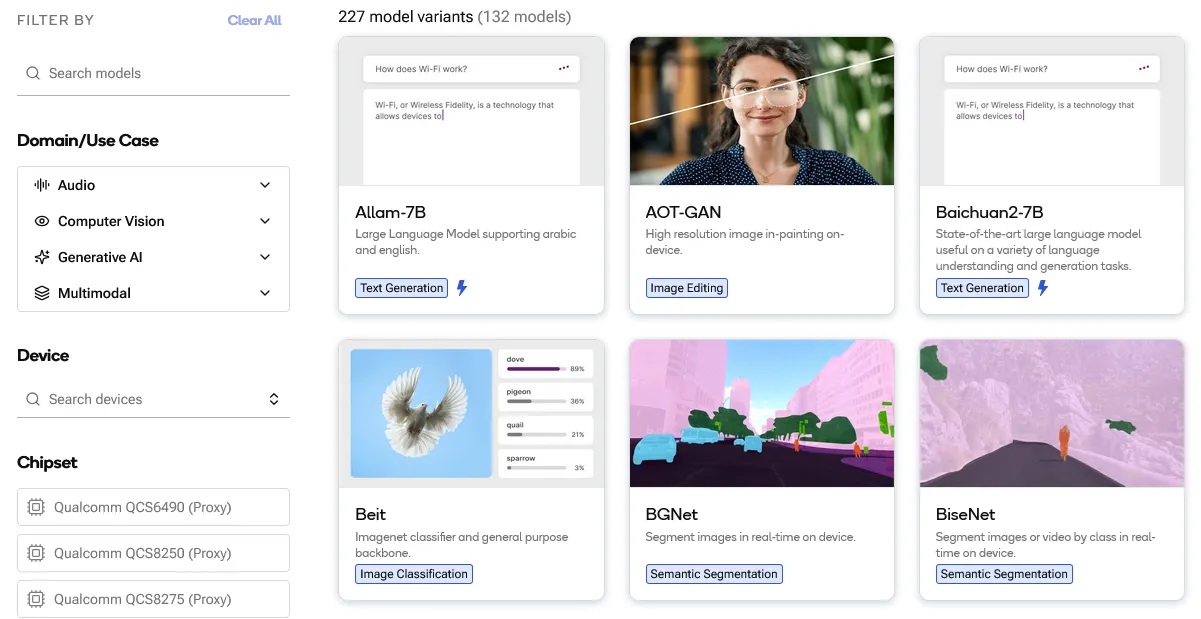
Qualcomm AI Hub平台目前已有超過130種直接可以用模型,並且持續增加中。
AI Hub提供了qai-hub python module 提供開發者以python程式與AI Hub進行互動操作,若是對其API較不熟悉的入門者也不用擔心,qai-hub也有提供CLI的指令與各類模型的操作示範腳本,只要帶入對應的參數即可執行。操作Qualcomm AI Hub的流程如下圖所示,可摘要成以下幾個步驟:
- 上傳模型:可以使用自行訓練的模型或是AI Hub清單中的預訓練模型。
- 進行最佳化:選定目標平台與執行階段參數進行最佳化。
- 驗證效能:取得從實體裝置運行後的效能數值進行評估。
- 最後評估通過即可從AI Hub下載最佳化模型部署到目標裝置上運行。
接下來筆者的實作將使用AI Hub建立YOLO v11物件偵測模型,並且部署於WoS進行推論。
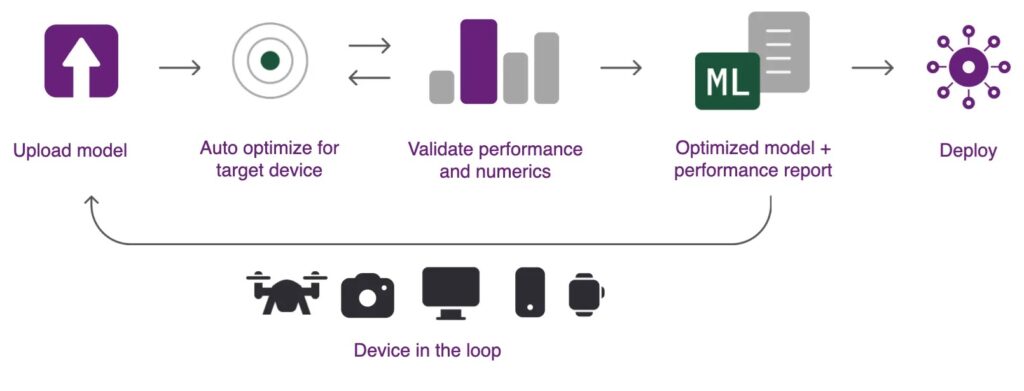
Qualcomm AI Hub可以針對特定裝置進行最佳化,並且查驗部署該裝置的各項數值 (source: qai-hub Doc)
登入AI Hub
前往Qualcomm AI Hub網站登入Qualcomm ID,若沒有帳號可以進行免費註冊, 一旦完成註冊可以使用Qualcomm網站上的大量資源。登入後,進入帳號設定頁面可以看到個人的帳號資訊,包含E-mail以及API Token。先將這一組API Token複製下來,後面使用qai-hub API操作AI Hub會使用到。
AI HUB Account Setting
於此同時也可以瀏覽一下AI Hub上眾多的預訓練模型,可以依據應用目的(影像、音訊、生成式AI)或是裝置類型(行動裝置、車載、AI PC )等方式進行查找。舉例而言筆者想要尋找在WoS執行的模型資訊,可從Models → By Industry → Compute開始尋找,再藉由Filter過濾Computer Vision電腦視覺相關模型,就能從中找到YOLOv11-Detection模型。點進 YOLOv11-Detection 模型頁面可以看到在 Snapdragon X Elite 的相關數據(如下圖),包含推論時間、記憶體用、NPU 用量等,並且可以切換不同的量化格式比較,若需要更詳盡的資料,還可以點進右下方 “see more metrics” 進行評估。在大部分的模型頁面還可以點選 “Download Model” 直接下載如 ONNX與QNN等格式的模型對應不同的硬體平台,若是自行轉換也不是什麼難事,只需要花上個五、六分鐘透過AI Hub平台進行線上轉換即可獲得!
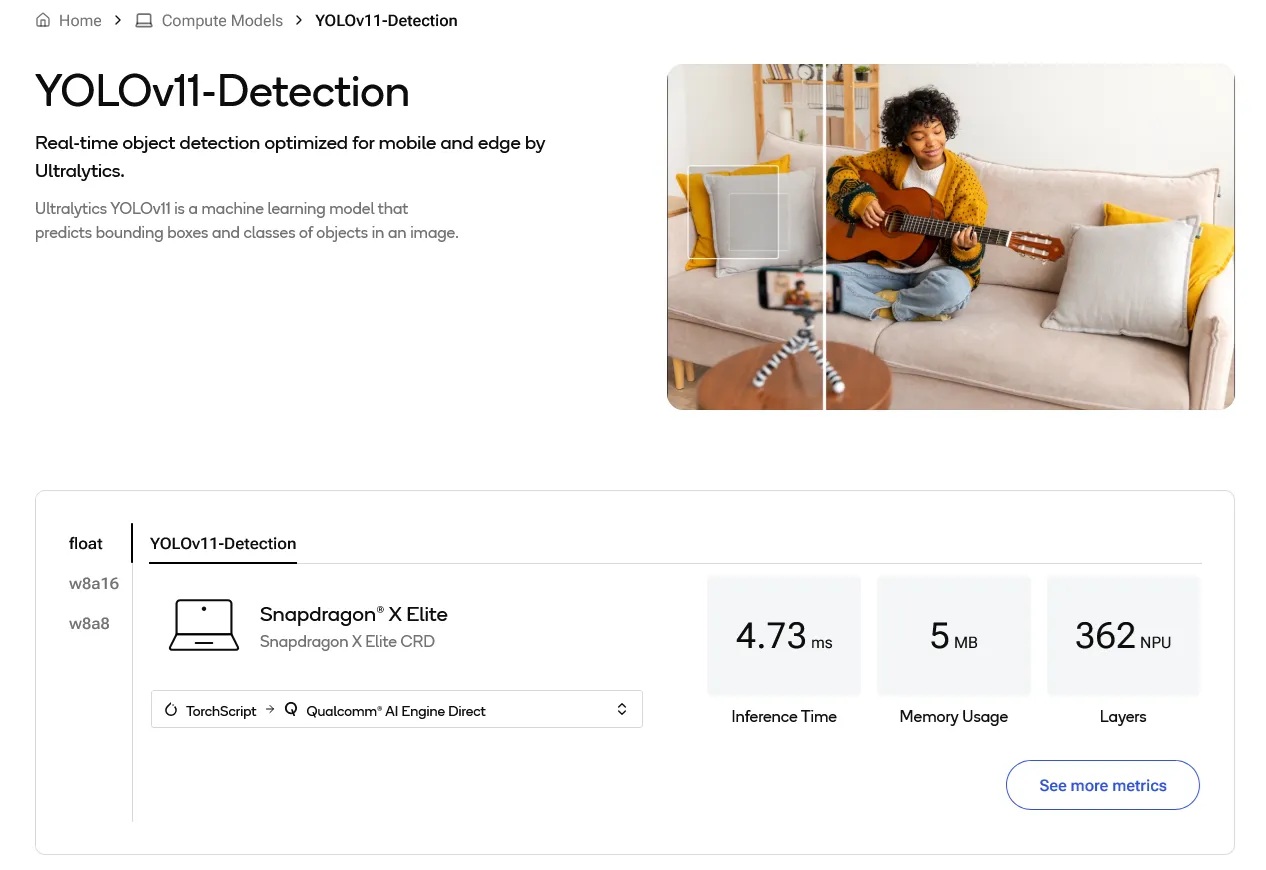
AI Hub 模型頁面提供各個平台詳盡的推論數值作為應用開發的評估
一鍵完成AI Hub模型轉換
要使用qai-hub python module操作AI Hub進行模型轉換在各平台皆可以執行,由於實際轉換工作會在AI Hub完成,因此電腦效能也不用太要求。唯獨需要留意的是qai-hub目前只能在Python AMD64的環境執行,尚不支援Python ARM64的版本,在安裝時務必留意一下!
STEP 1: 開啟命令提示字元,建立python虛擬環境
python -m venv aihub_env
aihub_env\Scripts\activate
STEP 2: 建立工作目錄(非必要,單純筆者個人習慣)
mkdir qai_hub
cd qai_hub
STEP 3: 安裝 qai_hub Python Package
pip install qai_hub_models
pip install torchmetrics
STEP 4: 設定AI Hub存取。下方指令 API_TOKEN 請替換成稍早從AI HUB帳戶中取得的token碼。
qai-hub configure --api_token API_TOKEN
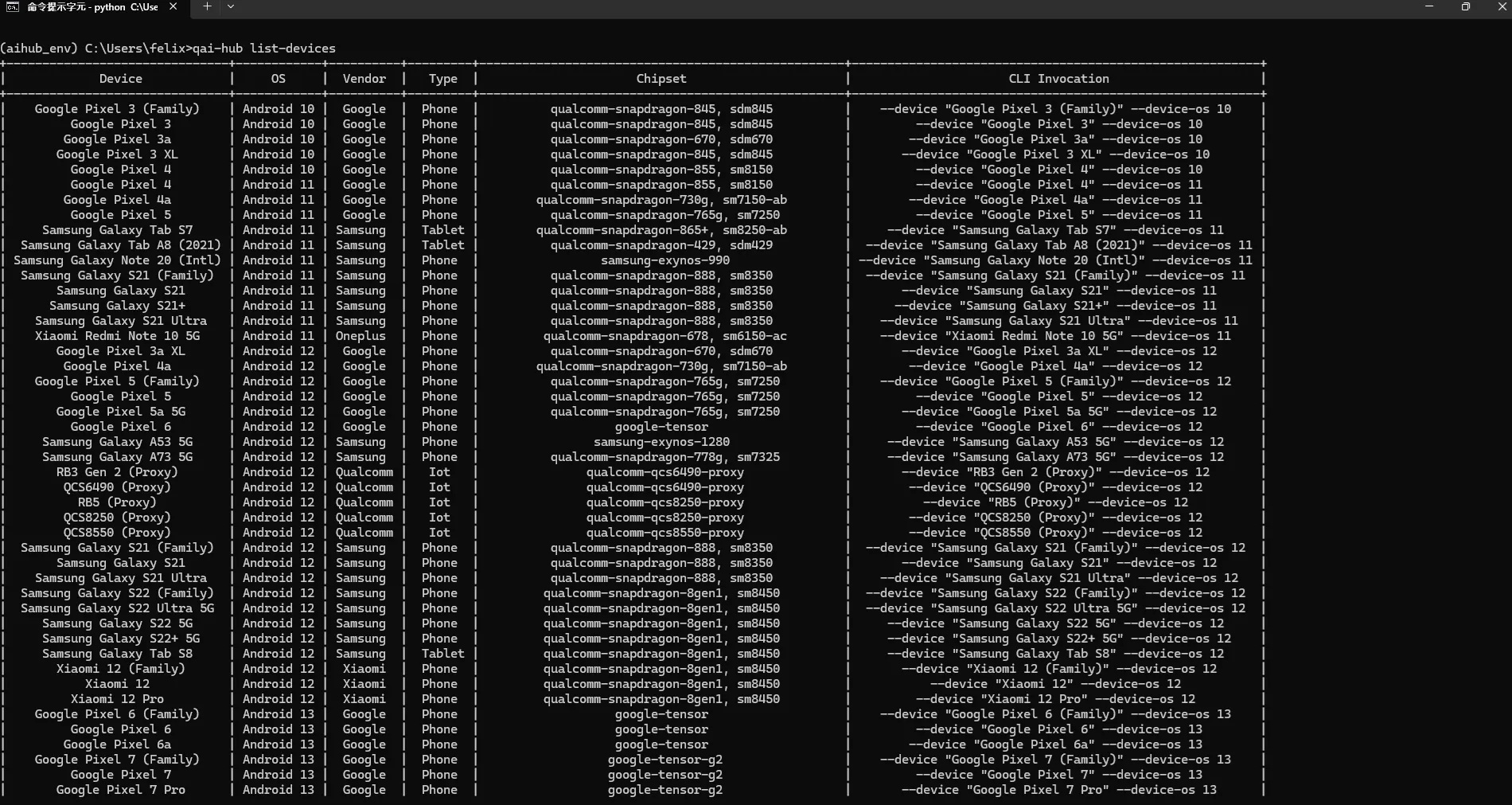
STEP 5: 查詢AI Hub可以使用的裝置列表,來確認已完成帳戶連結設定。
qai-hub list-devices
會出現如下圖的裝置列表,這些裝置都是可以做模型轉換的指定裝置,後續下達模型轉換指令也需要參照此表中CLI Invocation欄位內容 。若沒有出現此表格請往前檢查設定token是否有正確。
STEP 6: 安裝預訓練模型相依套件。qai-hub所有支援的預訓練模型可以從 repo 說明文件取得。由於筆者想轉換的是 YOLO v11 Object Detection 模型,以此帶入 yolov11_det 進行安裝。
pip install "qai_hub_models[yolov11_det]"
STEP 7: 一鍵操作完成 AI HUB 線上模型轉換。 後方指令參數說明:
: 指定 yolov11 的模型名稱(check point) , 預設為 yolo11n.pt,由於筆者想要測試 Snapdragon X 的性能極限,特地選擇參數量最多的 yolo11x.pt。
: 要針對哪一個執行階段框架做最佳化,可選 onnx, qnn 等。筆者選擇 precompiled_qnn_onnx 代表預先編譯好 QNN 模型的 ONNX 格式,這是筆者認為最容易操作的模型格式,且效能趨近於 QNN。
: 指定裝置,對應到前面的 list-devices。由於不同裝置的 NPU、GPU 皆有所差異,因此需要針對特定裝置平台進行最佳化。
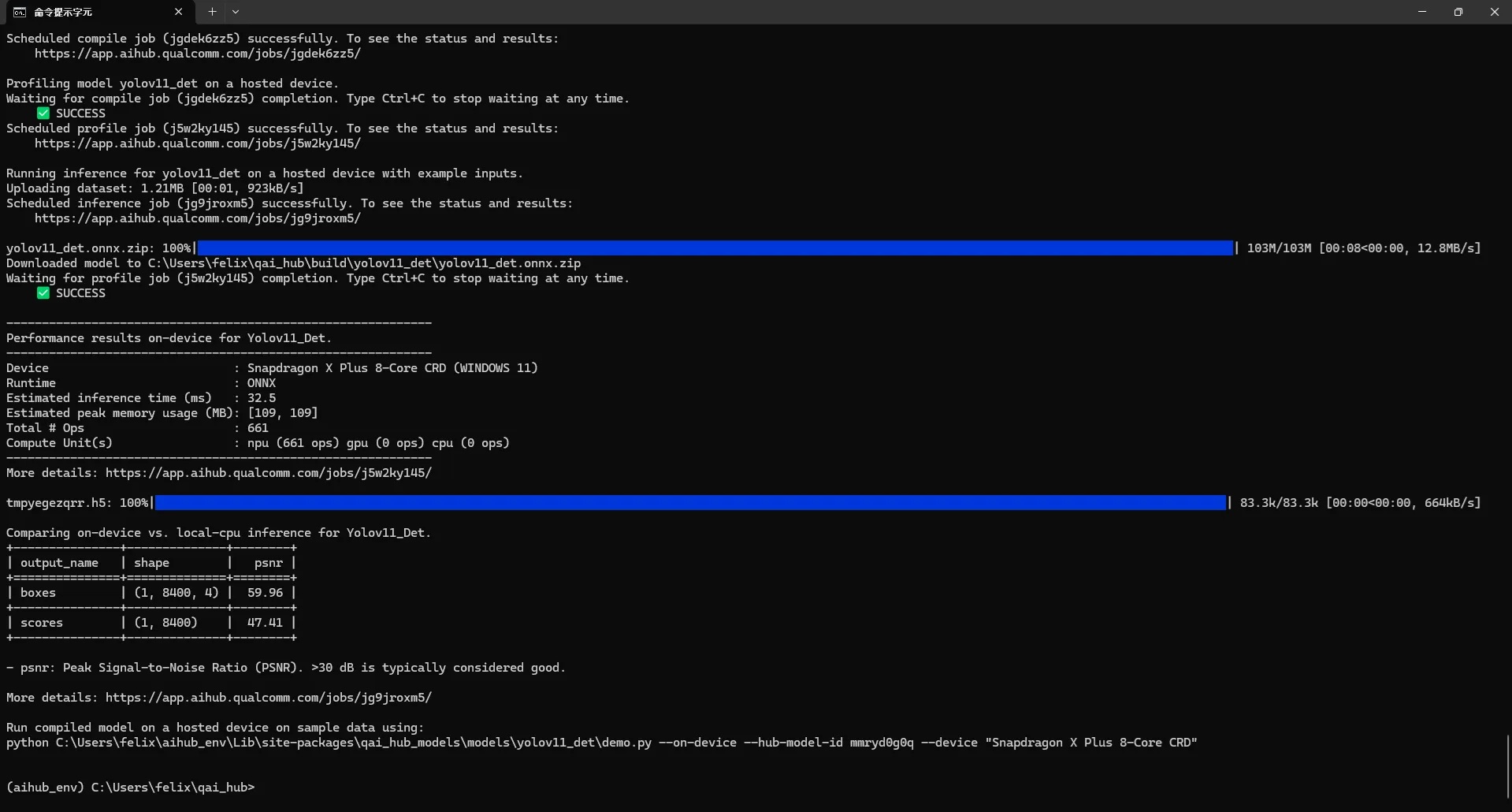
python -m qai_hub_models.models.yolov11_det.export --ckpt-name yolo11x.pt --target-runtime precompiled_qnn_onnx --device "Snapdragon X Plus 8-Core CRD"
輸入指令後就可以去泡一杯咖啡☕,約莫五分鐘回來後可以看到輸出以下結果即代表完成了!
STEP 8: 執行 on device DEMO。前步驟執行完成後有一個提示訊息(如上圖),表示可以執行該指令來進行模型 demo,不過該指令有些更新直接執行會報錯誤,需要把
改成
才可正確執行。也請留意每個人的路徑與模型 ID 皆會不同,注意別照著筆者的提示訊息照打了!
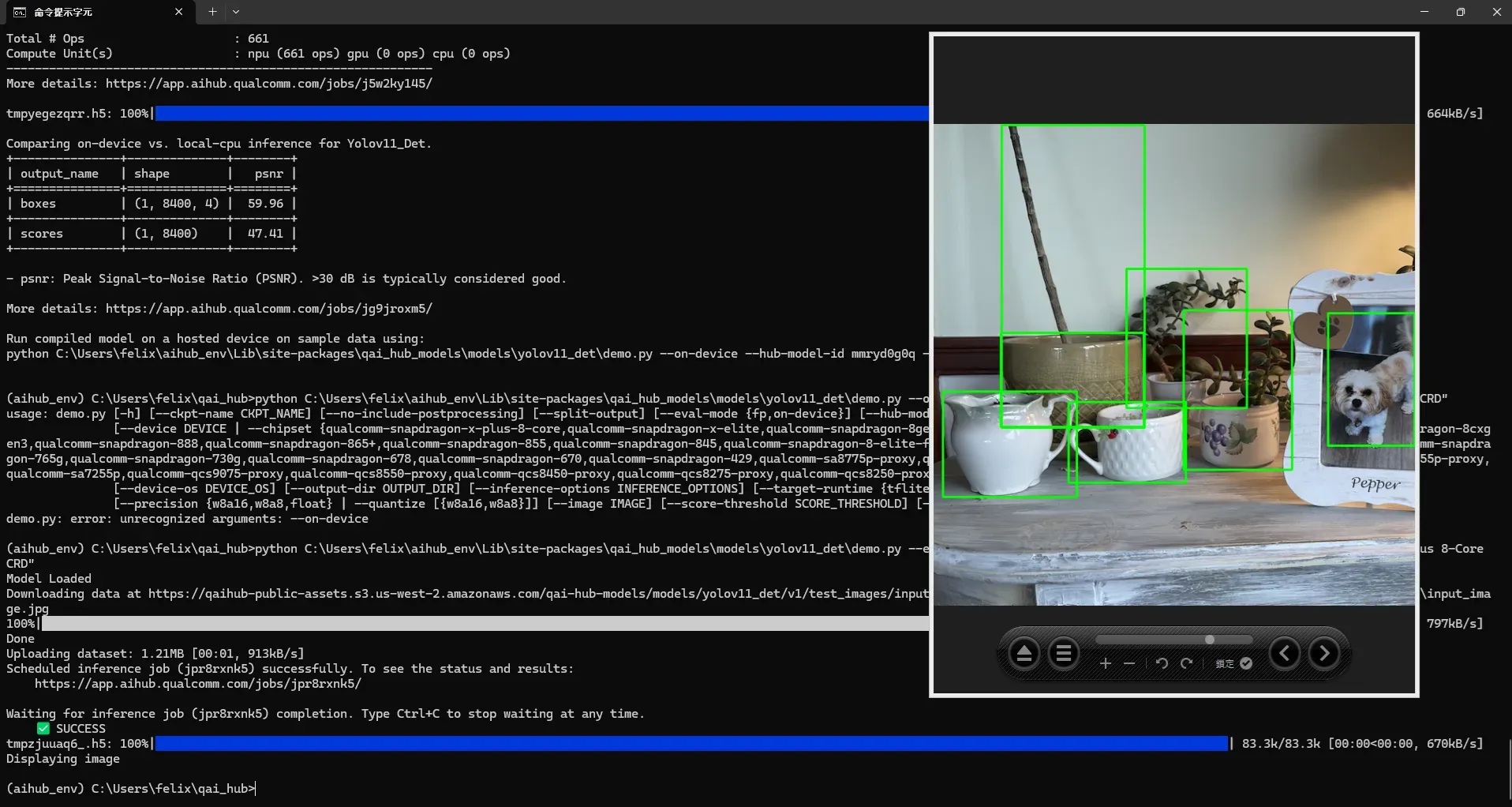
python C:\Users\felix\aihub_env\Lib\site-packages\qai_hub_models\models\yolov11_det\demo.py --eval-mode on-device --hub-model-id mmryd0g0q --device "Snapdragon X Plus 8-Core CRD"
這邊所謂的on-device demo會把實際的模型找一台 “真實” 裝置進行推論,並把測試的結果取回到本地端呈現,可以看到辨識的輸出結果如下圖。若看到的辨識結果沒問題,就代表轉換已完成可以前往AI Hub網站把模型下載到WoS進行推論啦!
管理Jobs與Models
回到Qualcomm AI Hub App進行登入,會看到稍早執行的模型轉換的工作清單(JOBS)列表。在工作清單中又可以分為Compile、Quantize、Link、Profile、Inference等任務。若依照筆者執行的指令這邊會自動產生Compile、Profile與Inference等任務,可以逐一進行查看。
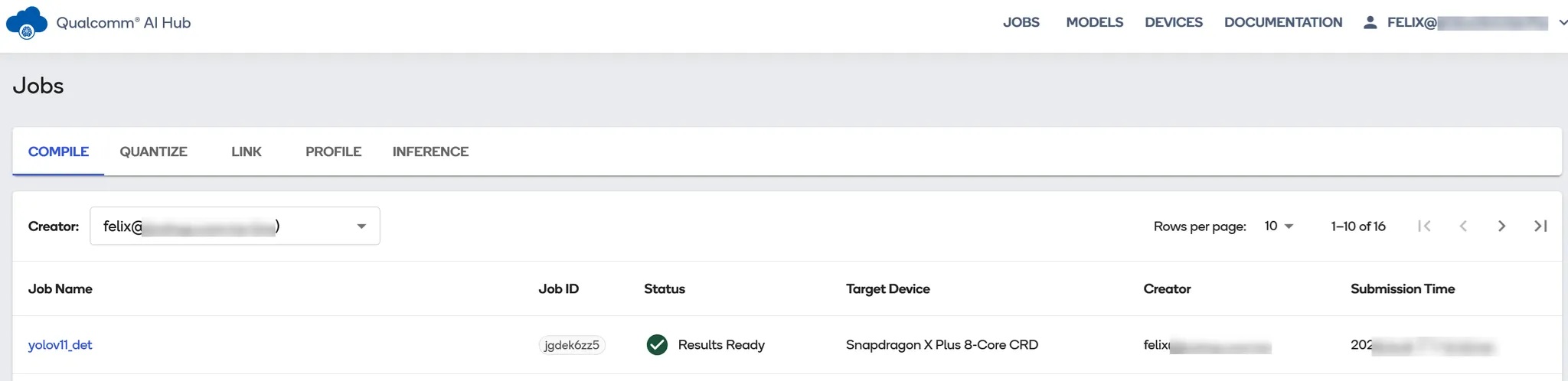
AI HUB上的工作清單
點進去Job Name可以看到該任務的名稱、來源模型、參數、目標裝置、甚至是版本等記錄,一旦任務多了這些資訊其實可以有效讓開發者辨別此任務執行環境,也可以在不同模型版本之間有個對照,下方甚至還有 compile log 可以查看。
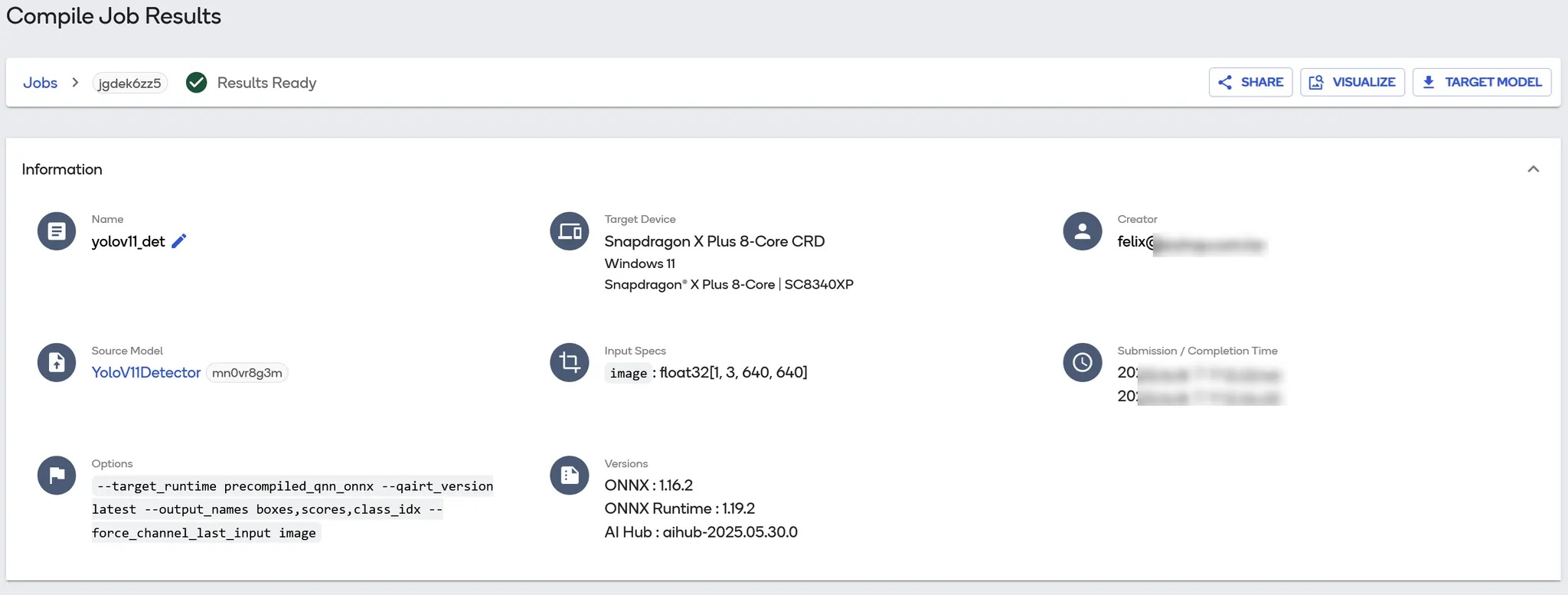
工作任務中的各項參數記錄
接著點選最上方主選單中的 “MODELS” 查看轉換好的模型清單,可以看到有四個模型其類型分別是 TorchScript、ONNX、QNN Context Binary與ONNX。這時可能會產生一個疑惑:「執行一個模型轉換,為什麼產生了四個模型檔案?」由於筆者指定的runtime 為 “precompiled_qnn_onnx”,在轉換前需要上傳原始的 YOLOv11 模型(TorchScript),接著qai-hub會先轉換為標準ONNX,再轉為 QNN Context Binay(此模型可給QNN SDK使用), 最後再將此QNN模型包進ONNX中,得到的最終模型就是“precompiled_qnn_onnx” 格式了,但這中間過度的模型檔都可以在平台上查找,甚至也可以分別下載回去使用,對於歷程的清除交代筆者也是頗為激賞!
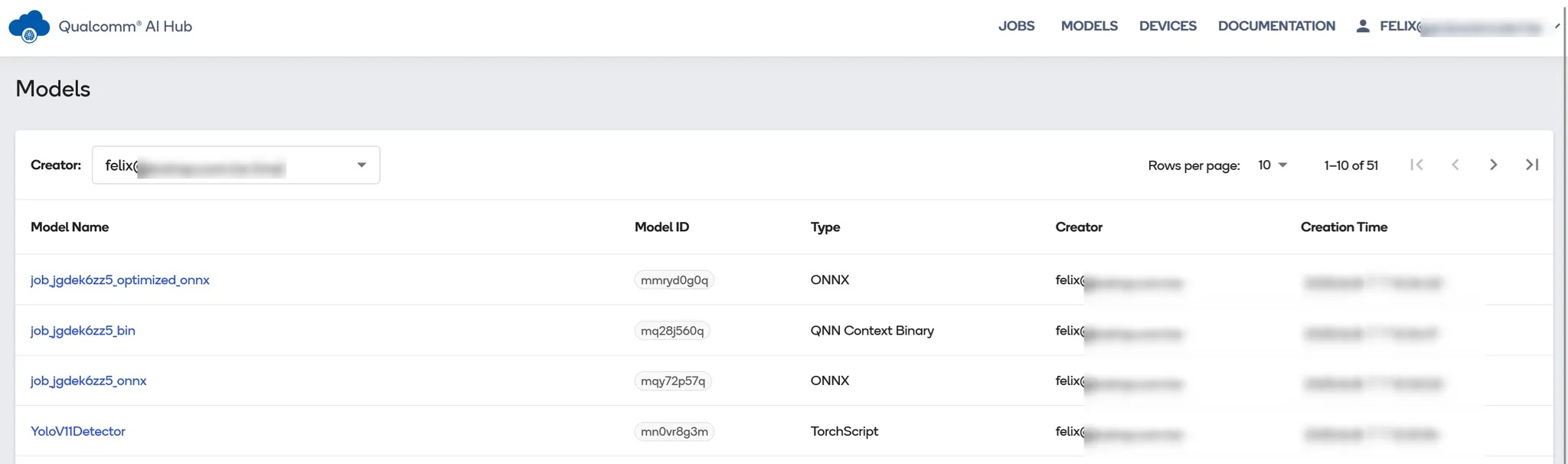
AI HUB上的模型清單
點選進去 optimized_onnx 模型可以查看到模型細節資料,包含執行版本與 Backend 等 meta data 都有清楚記錄於此頁面,若沒問題就點選右上角 “Download” 把模型下載回 WoS 準備推論。除此之外在 “Download” 按鈕旁邊還可以點選 Visualize 視覺化呈現模型架構。
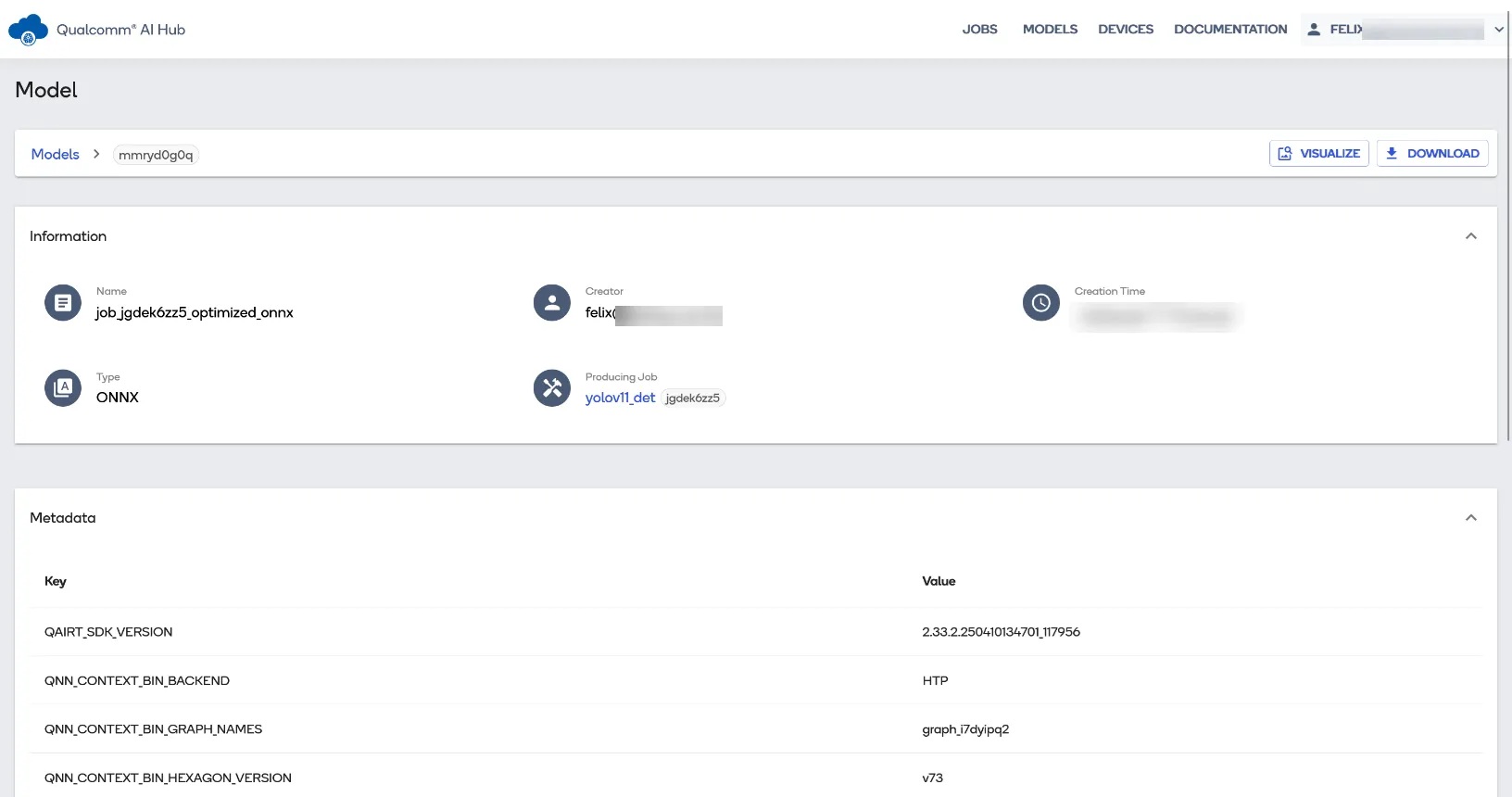
模型資料與metadata
以下圖為例就是過渡產生的QNN模型架構,也是最終會以binary形式包裹在ONNX格式中的結構。
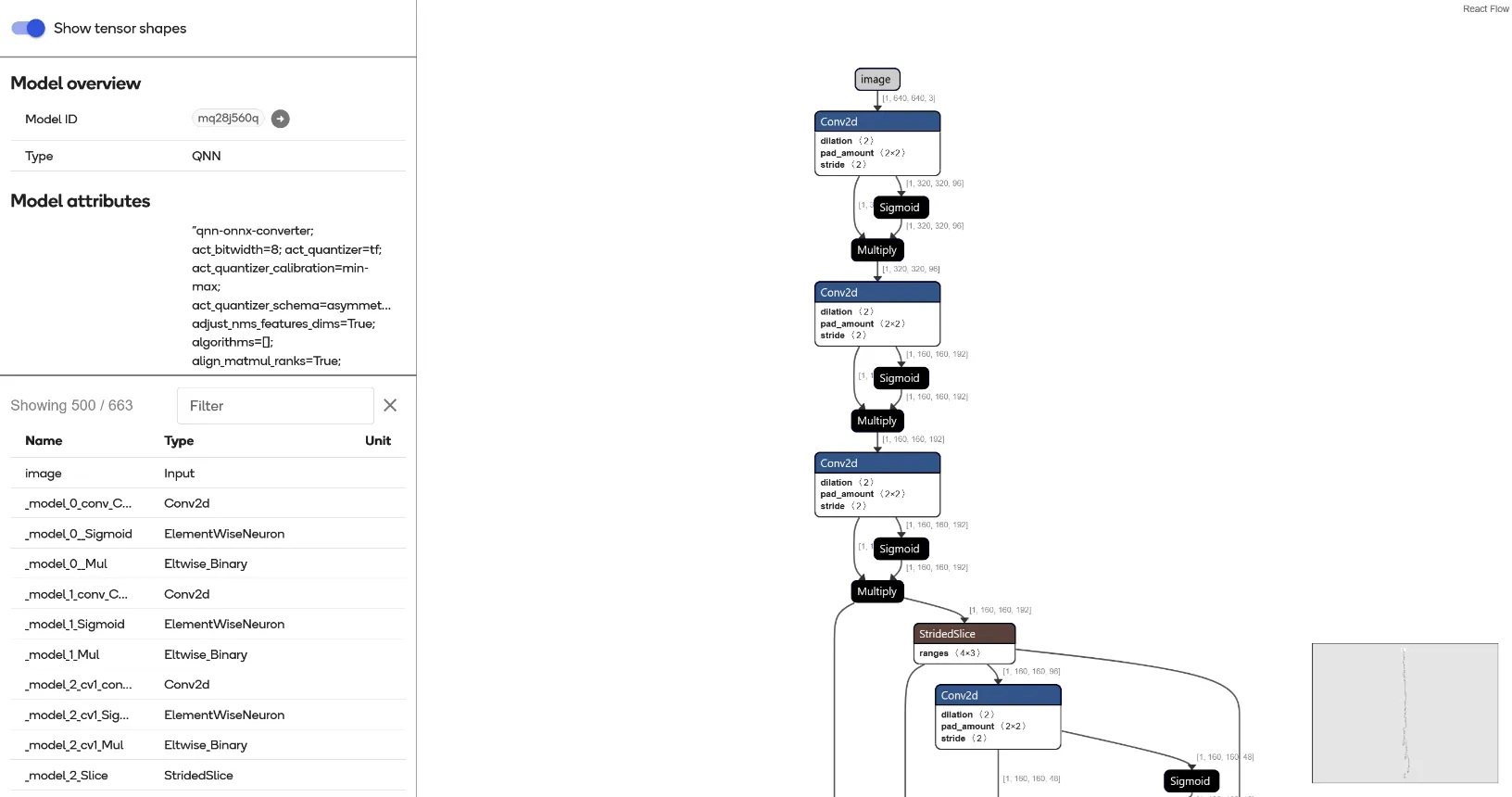
AI HUB提供視覺化模型結構圖
WoS 部署與推論
取得轉換好的模型後接下來就是在Windows on Snapdragon上進行部署與推論了!筆者的測試環境為DELL XPS Snapdragon X Plus (X1P-64-100),其他各品牌的WoS都能以相同的方式進行操作。整體安裝過程基本上官方都已經寫成 Power Shell 腳本,操作上算是相當友善。
STEP 1: 以系統管理員身分執行 Power Shell,建立路徑環境變數、建立資料夾。
$DIR_PATH = "C:\WoS_AI"
mkdir $DIR_PATH
STEP 2: 下載安裝腳本,移動到指令路徑。
Invoke-WebRequest -O ort_setup.ps1 https://raw.githubusercontent.com/quic/wos-ai/refs/heads/main/Scripts/ort_setup.ps1
Move-Item -Path ".\ort_setup.ps1" -Destination $DIR_PATH
STEP 3: 執行 ONNX Runtime (ORT) QNN EP 相依套件安裝。這指令將會自動安裝 python 3.12.6 (AMD64), Visual Studio 可轉發套件等,並且建立 python 虛擬環境。
cd $DIR_PATH
powershell -command "&{. .\ort_setup.ps1; ORT_QNN_Setup -rootDirPath $DIR_PATH}"
STEP 4: 進入虛擬環境(SDX_ORT_QNN_ENV)。此腳本預設會建立一個 mobilenet v2 的模型資料夾,讓開發者可以直接進行測試,有興趣的開發者後續可以自行操作看看。
${DIR_PATH} = "C:\WoS_AI"
powershell -NoExit -command "&{cd $DIR_PATH; . .\Downloads\Setup_Scripts\ort_setup.ps1; Activate_ORT_QNN_VENV -rootDirPath $DIR_PATH}"
筆者這邊會使用剛才下載的 YOLO v11 模型,先建立一個資料夾進行存放。
mkdir $DIR_PATH\Models\yolov11_det
cd $DIR_PATH\Models\yolov11_det
STEP 5: 將剛才從 AI Hub 下載的 “precompiled_qnn_onnx” 模型移動到此資料夾並解壓縮,會得到一個名為 model.onnx 資料夾,裡面包含 model.bin(QNN) 與 model.onnx(ONNX) 兩個檔案。
STEP 6: 準備推論應用程式。
安裝所需 python package 。
pip install opencv-python numpy pyyaml
開啟程式碼編輯器(如 VS Code),貼上以下程式碼,並且另存成 ort_yolo_webcam.py。
import cv2
import numpy as np
import onnxruntime as ort
import time
from PIL import Image
import requests
import os
import yaml
def preprocess(img_path):
"""
Preprocess image to shape [1, 640, 640, 3] and normalize to [0, 1]
"""
if os.path.exists(img_path):
img = Image.open(img_path)
else:
response = requests.get(img_path, stream=True)
response.raw.decode_content = True
img = Image.open(response.raw)
img = img.resize((640, 640))
img = np.array(img).astype(np.float32) / 255.0
img = np.expand_dims(img, axis=0) # [1, 640, 640, 3]
return img.astype(np.float32)
def load_class_names_from_yaml(url):
"""
下載 coco.yaml 並取得 names dict
"""
response = requests.get(url)
data = yaml.safe_load(response.text)
names = data.get("names", {})
if isinstance(names, dict):
# 轉換成 list,確保 index 對應
class_names = [names[k] for k in sorted(names.keys())]
else:
class_names = names # 已是 list 格式
return class_names
def postprocess_yolo(outputs, score_thresh=0.5, iou_thresh=0.5):
class_names = load_class_names_from_yaml(
"https://raw.githubusercontent.com/ultralytics/ultralytics/refs/heads/main/ultralytics/cfg/datasets/coco.yaml"
)
boxes, scores, class_idxs = outputs
boxes = boxes[0]
scores = scores[0]
class_idxs = class_idxs[0].astype(int)
filtered = [(i, box, scores[i], class_idxs[i])
for i, box in enumerate(boxes) if scores[i] > score_thresh]
if not filtered:
print("No detections above threshold.")
return
indices = nms(
boxes=np.array([f[1] for f in filtered]),
scores=np.array([f[2] for f in filtered]),
iou_threshold=iou_thresh
)
print("\n********** YOLOv11 Detections After NMS **********")
for idx in indices:
i, box, score, cls = filtered[idx]
class_name = class_names[cls] if cls < len(class_names) else f"id_{cls}" print(f"Class: {cls:3d} ({class_name}), Score: {score:.2f}, Box: {box}") def nms(boxes, scores, iou_threshold=0.5): """ Apply Non-Maximum Suppression (NMS) on bounding boxes """ indices = cv2.dnn.NMSBoxes( bboxes=boxes.tolist(), scores=scores.tolist(), score_threshold=0.5, nms_threshold=iou_threshold ) return indices.flatten() if len(indices) > 0 else []
# Load ONNX model
onnx_model_path = "model.onnx/model.onnx"
execution_provider_option = {
"backend_path": "QnnHtp.dll",
"enable_htp_fp16_precision": "1",
"htp_performance_mode": "high_performance"
}
session = ort.InferenceSession(
onnx_model_path,
providers=["QNNExecutionProvider"],
provider_options=[execution_provider_option]
)
input_name = session.get_inputs()[0].name
output_names = [o.name for o in session.get_outputs()]
class_names = load_class_names_from_yaml(
"https://raw.githubusercontent.com/ultralytics/ultralytics/refs/heads/main/ultralytics/cfg/datasets/coco.yaml"
)
# Open webcam
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print("❌ Cannot open camera")
exit()
while True:
start_time = time.time()
ret, frame = cap.read()
if not ret:
break
# --- 預處理與推論 ---
input_img = cv2.resize(frame, (640, 640))
norm_img = input_img.astype(np.float32) / 255.0
input_tensor = np.expand_dims(norm_img, axis=0)
outputs = session.run(output_names, {input_name: input_tensor})
boxes, scores, class_idxs = outputs
boxes = boxes[0]
scores = scores[0]
class_idxs = class_idxs[0].astype(int)
# --- 後處理 (含 NMS + 畫框) ---
filtered = [(i, box, scores[i], class_idxs[i])
for i, box in enumerate(boxes) if scores[i] > 0.4]
if filtered:
keep = nms(
boxes=np.array([f[1] for f in filtered]),
scores=np.array([f[2] for f in filtered])
)
for idx in keep:
_, box, score, cls = filtered[idx]
x1, y1, x2, y2 = map(int, box)
class_name = class_names[cls] if cls < len(class_names) else f"id_{cls}"
label = f"{class_name} {score:.2f}"
cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.putText(frame, label, (x1, y1 - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 2)
# --- FPS 計算與顯示 ---
end_time = time.time()
fps = 1.0 / (end_time - start_time)
cv2.putText(frame, f"FPS: {fps:.2f}", (10, 25),
cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 255), 2)
# --- 顯示影像 ---
cv2.imshow("YOLOv11 Detection", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
STEP 7: 執行推論應用程式。輸入以下指令啟動剛才建立的測試程式,該程式會抓取 Webcam 影像進行即時 YOLOv11 物件偵測,並且將辨識結果顯示出來。
python ort_yolo_webcam.py
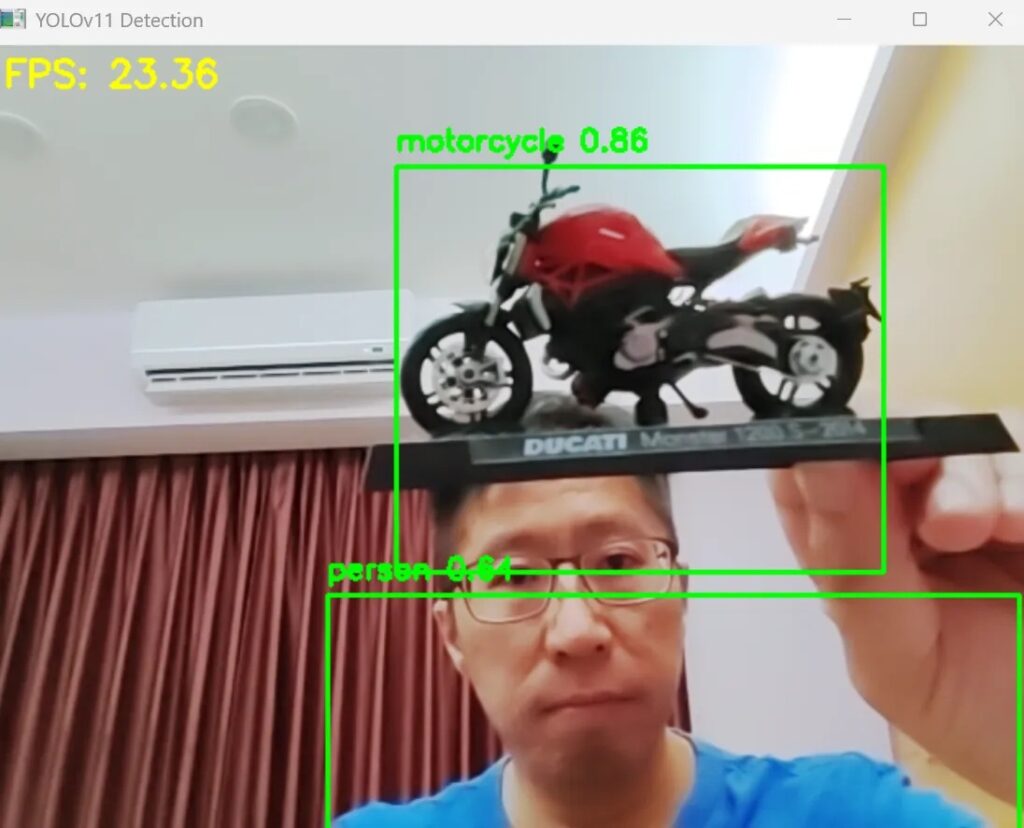
執行YOLOv11x 即時推論
載入的模型檔案為 YOLO11x.pt 參數量約有5,690萬個,是YOLOv11中最大的模型,辨識的效能挺不錯的!查看系統資源NPU的使用量約佔70% 上下,GPU約15%,主要是呈現辨識結果的影像,整體看來系統還是游刃有餘的!實際用程式估算推論時間,執行 yolo11x 大約 34.5ms,若是執行 yolo11n 推論則僅需 5.2ms!
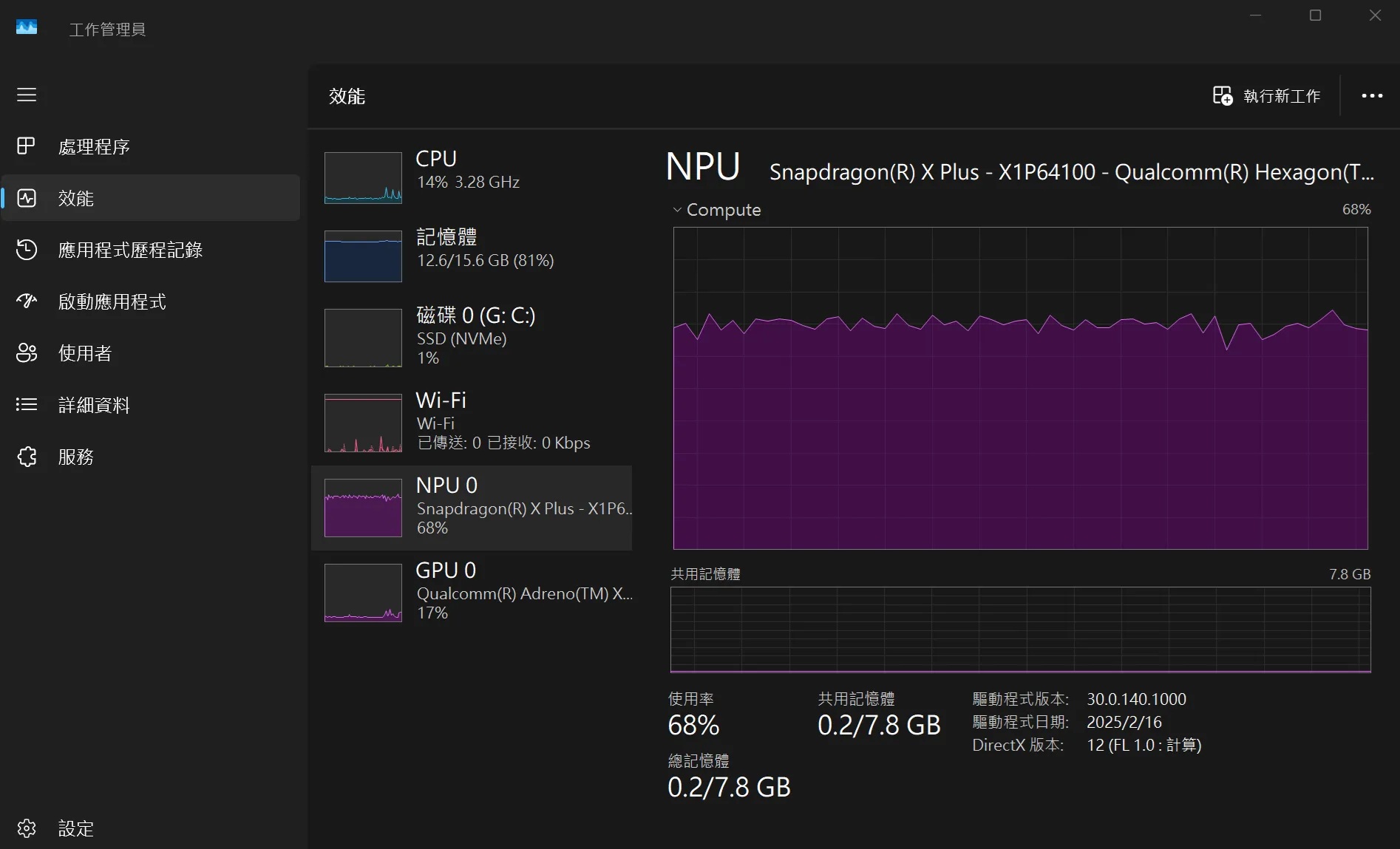
即便是YOLOv11x這樣運算量大的模型還沒辦法讓NPU效能榨乾。
沒有 WoS? Device Cloud 借你!
如果沒有WoS硬體或是還不確定該選用哪一等級的Snapdragon硬體也不用擔心,Qualcomm Device Cloud 平台上各類Qualcomm硬體平台免費借你用!同樣使用Qualcomm ID登入後就可以看到十來個硬體設備可以申請免費使用,只要填寫簡易的表單就能獲得免費評估使用時間。
Qualcomm Device Cloud提供超過十餘種真實硬體裝置。
申請了使用時數之後,點選該裝置啟動Interactive Session ,接著在Session設定中填入名稱、是否要預先上傳應用程式或AI模型等。筆者這裡會建議把操作模式選擇 ”Screen mirroring + SSH”,螢幕鏡射當然是最直接的操作沒問題,但是透過網頁包裹會犧牲傳輸品質,開啟SSH經由設定後可以直接用Windows遠端桌面RDP協定開發上更有效率! 這邊會要求產生一個public的SSH作為認證使用,產生後記得保存好在特定的路徑上。
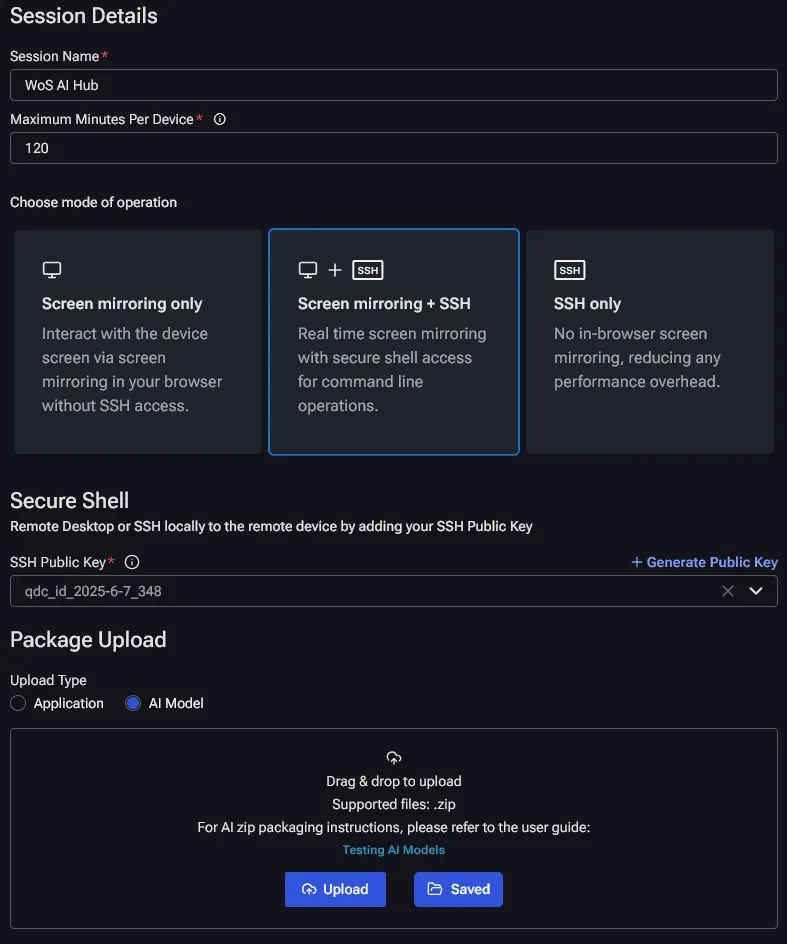
工作模式建議選擇螢幕鏡射 + SSH
啟動session後可以看到瀏覽器會開啟該WoS的桌面環境,可以直接在此環境上進行應用程式開發與測試。但透過網頁傳遞桌面畫面的效能並不好,整體操作體驗略顯遲緩,這時我們可以改由SSH與遠端桌面的方式進行連線。點選遠端session頁面中上方 “Connect” 按鈕。
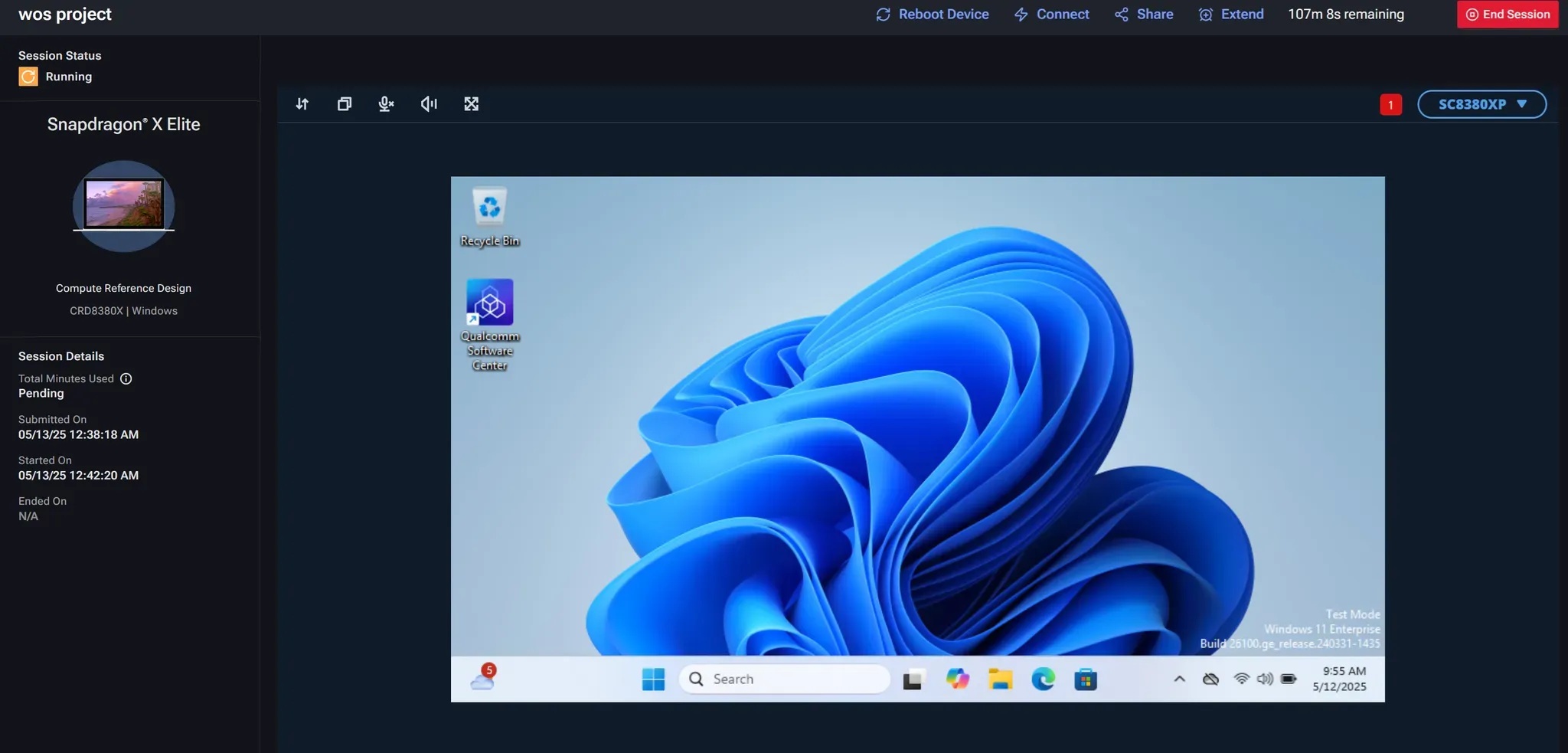
真實的Snapdragon X Elite CRD設備
這時會有彈出視窗進行教學如何使用SSH連線與遠端桌面。最上方三個欄位是由使用者自行填入的,分別是 SSH key 路徑、SSH Port 與 遠端桌面 Port,填寫完成後下方會自動產生所需要執行的指令,開啟命令提示字元貼上此指令。此指令會把 Device Cloud WoS 設備的 SSH 與 RDP 鏡射到本地端的指定 port。
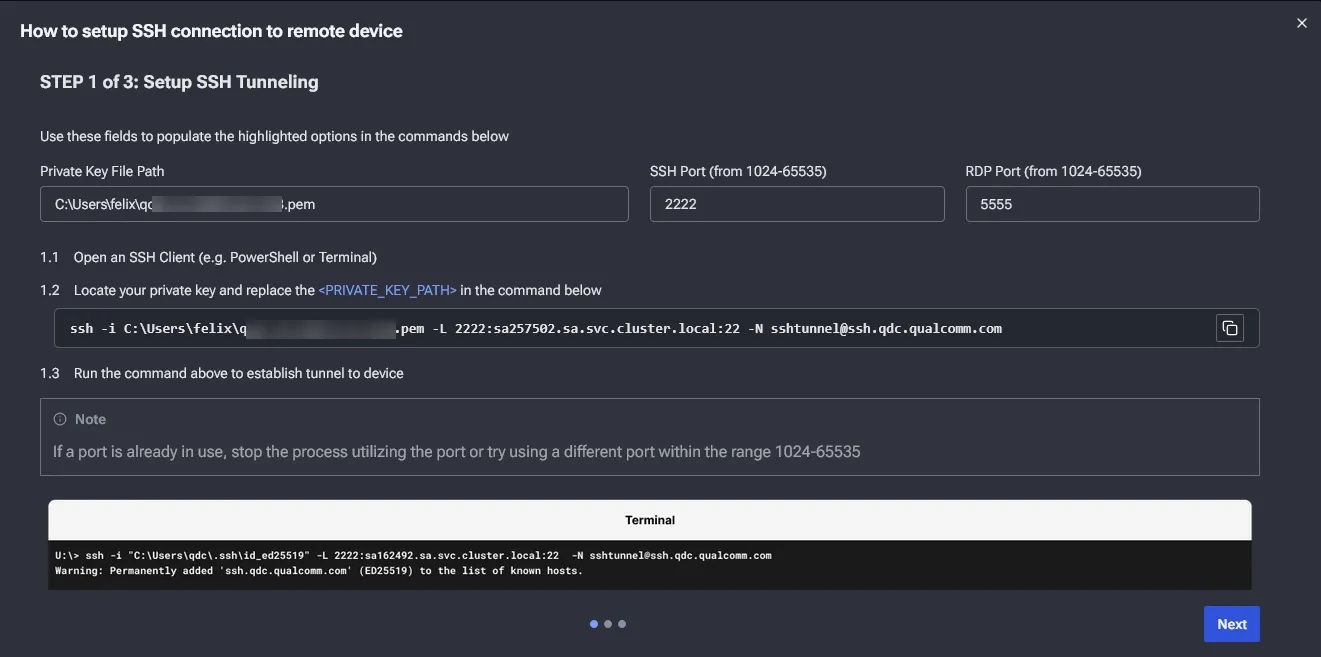
看到下圖提示訊息即代表已成功和 Device Cloud 設備完成連線。
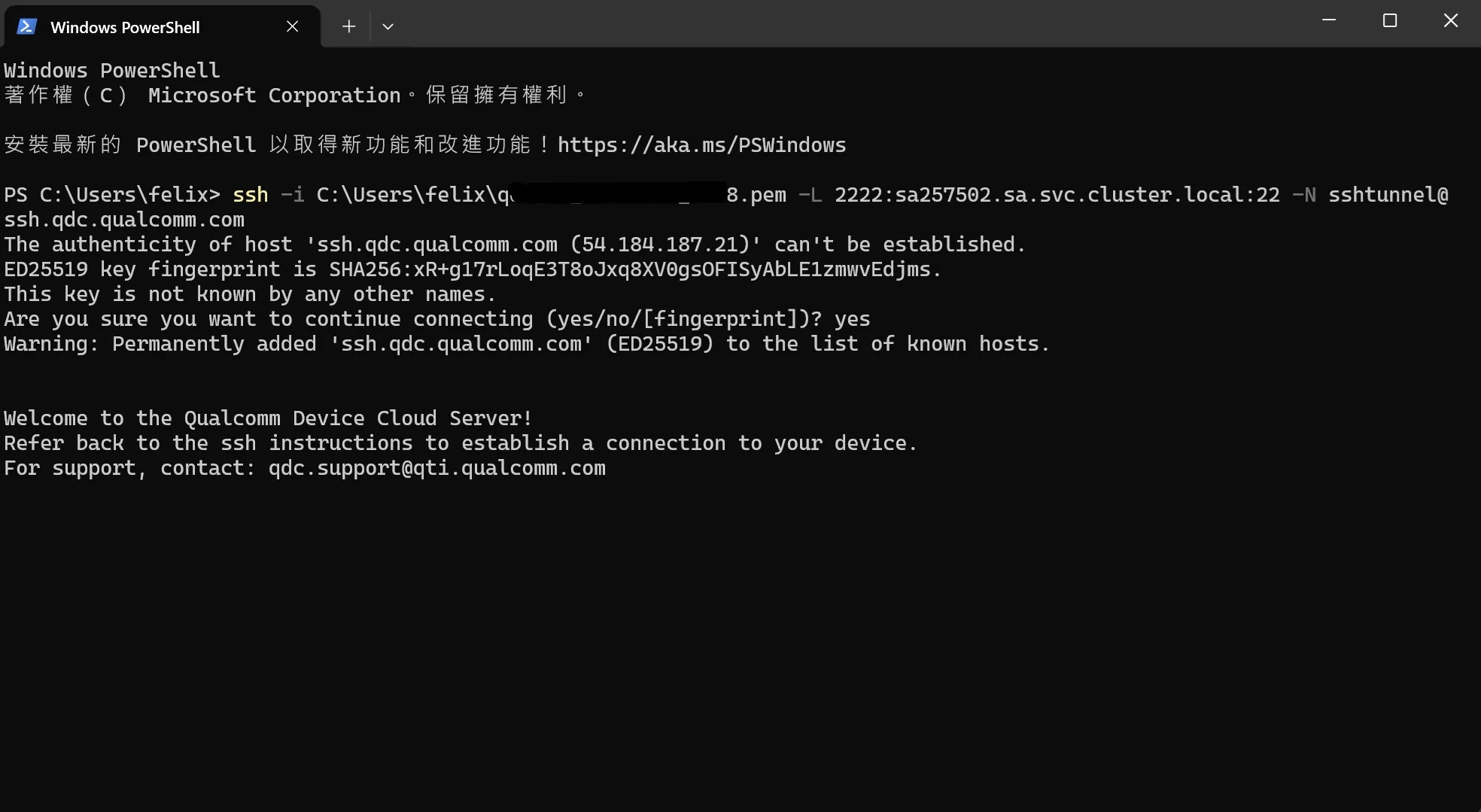
若要使用 SSH 連線命令列模式,則另外再開啟一個命令提示字元輸入 STEP 2 指令如下圖:
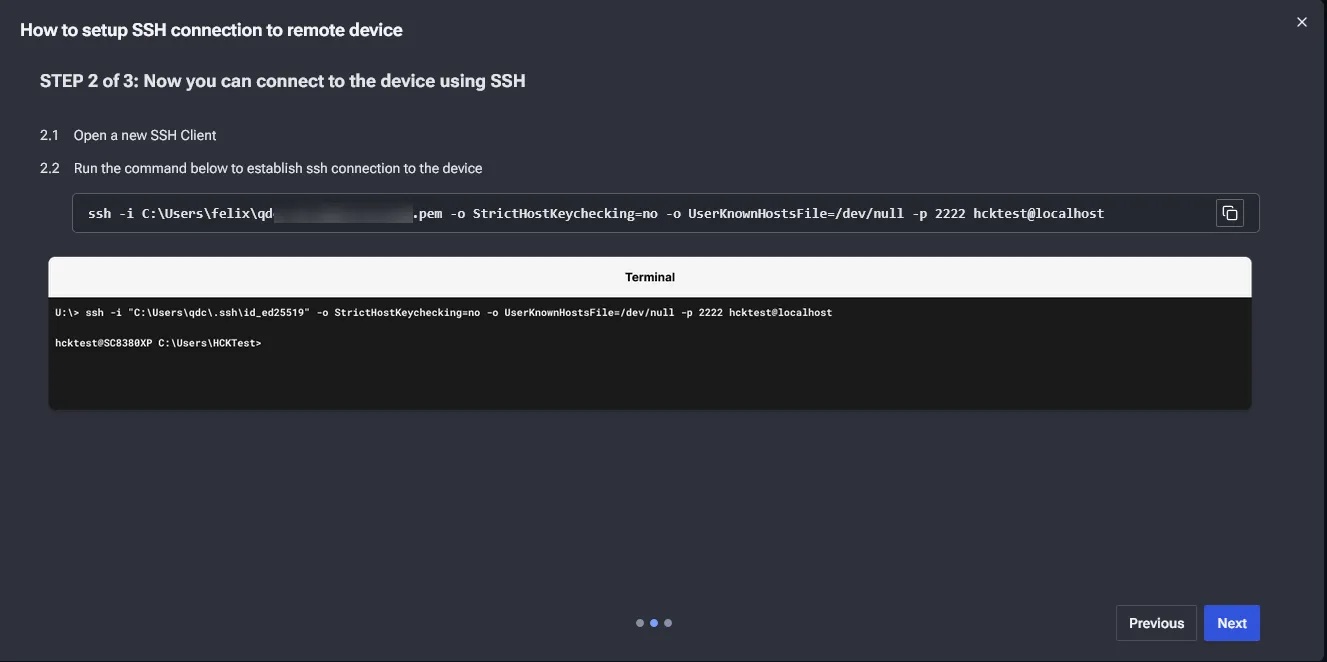
若要使用 RDP 連線則另外再開啟一個命令提示字元輸入 STEP 3 的指引命令如下圖:
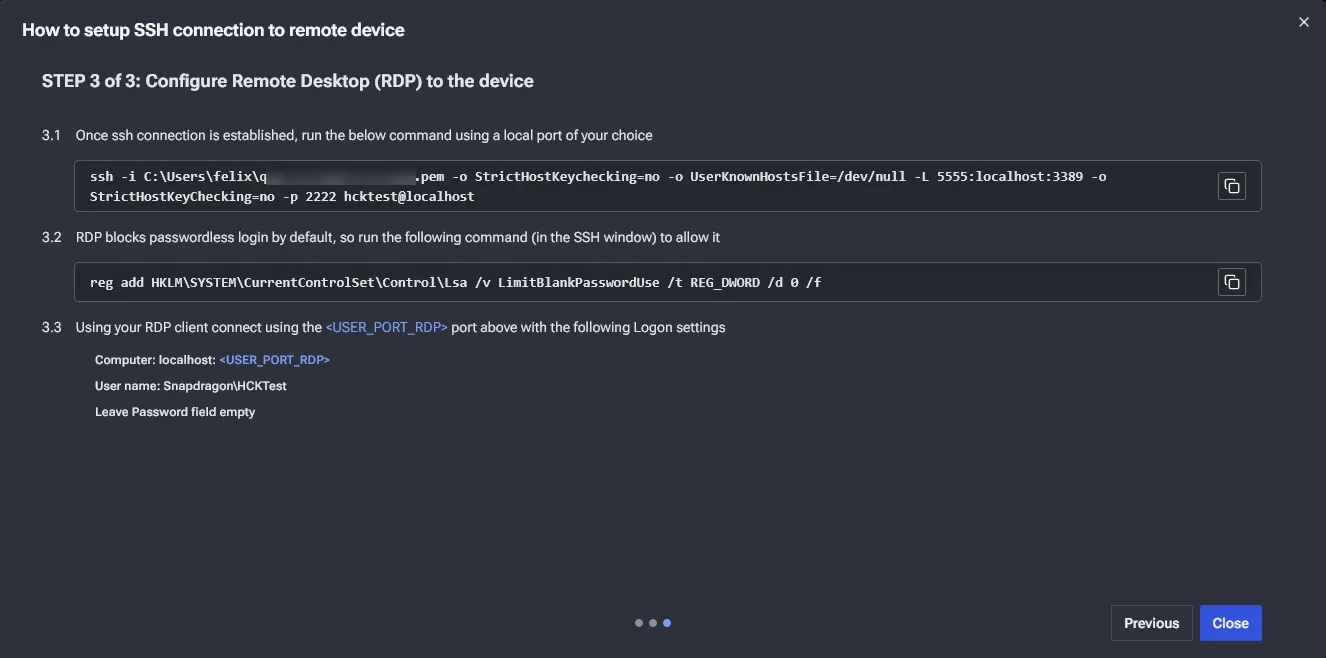
執行完上述兩個 RDP 指令後開啟遠端桌面程式,輸入 localhost:<RDP port>,即進行連線。使用者名稱為 Snapdragon\HCKTest,密碼則為空白。
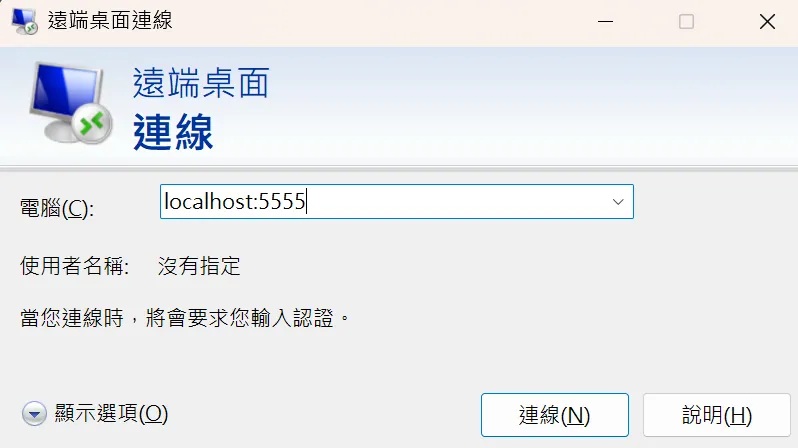
RDP 連線後即可擁有一台效能頂級、記憶體 64GB 的 WoS 設備進行體驗啦!傳入的檔案預設則會放在 C:\Temp\ 路徑下。
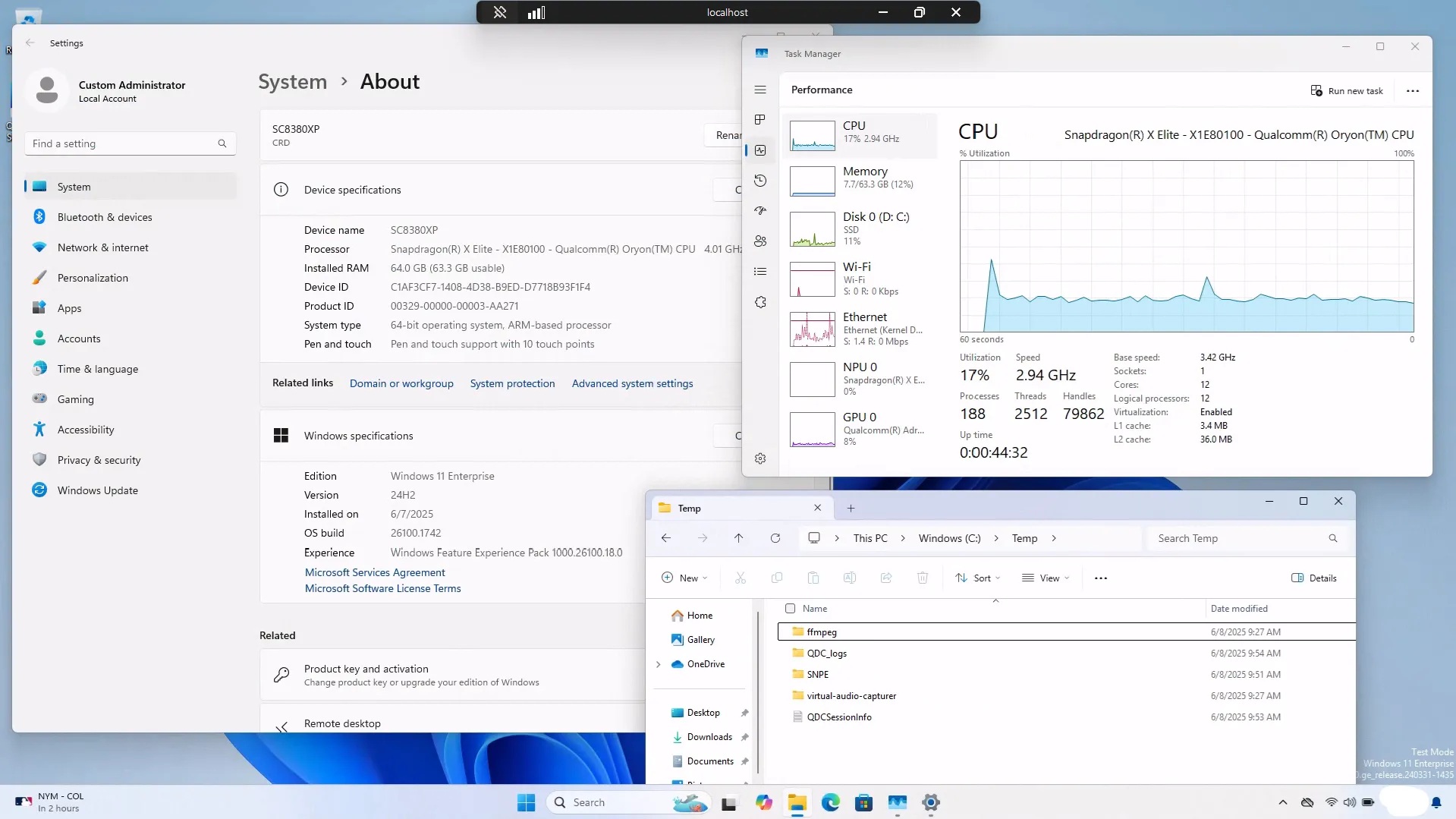
Qualcomm Device Cloud 上提供效能超群的 Snapdragon X Elite。
小結-令人驚艷的能耗比
即便對於WoS的能耗表現已有所期待,但隨者各類 AI 模型的載入,筆者對於WoS的驚艷感受也是出乎意料之外!在進行 AI 運算的同時,還可以騰出大量硬體資源,對於本地端AI應用程式的想像有了更多空間。除此之外,Qualcomm對於生態系的努力也是不在話下,縱然QNN SDK的熟悉並非一時半刻即可掌握,但目前已有成熟的 ONNX Runtime 協助工程師們便捷地開發 WoS AI 應用。
最後還是必須提到,此時此刻在Windows on Arm 系統上應用程式的完善程度仍然有進步空間,使用 x86 相容模式難免會遇到非預期狀況,但相信隨著Arm生態的發展,近期也將能陸續改善。

- 以MCU開啟Edge AI新境界:Renesas RA8P1實測 - 2025/10/22
- Windows on Snapdragon部署GenAI策略指南 - 2025/09/23
- 運用Qualcomm AI Hub結合WoS打造低功耗高效能推論平台 - 2025/08/01
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


