作者:歐敏銓
當大型語言模型的規模不斷擴張,算力與能耗的壓力也持續飆升,業界迫切需要一種能兼顧效率與性能的解方。BitNet 的出現,為這場硬體與模型的拉鋸戰帶來了新可能,它以「1-bit Transformer」的極致壓縮,展示了語言模型在記憶體與能源效率上的全新想像。而進一步的 Falcon-Edge (SLM)與 onebitllms(輕量級 Python 套件),更為這條技術路徑打開了可實用化的希望之門。
記憶體與算力的隱形戰爭
近年來,大型語言模型(LLM)的進展猶如賽車般飛速,從 GPT、LLaMA 到 DeepSeek,每一代都在規模與表現上刷新紀錄。然而,這股狂飆的背後,卻伴隨著龐大的計算與能源代價。模型愈大,所需的 GPU 記憶體、計算時間以及分散式部署的通訊成本也隨之急劇增加,這讓許多想要將模型真正落地的應用,陷入能耗與成本的困境。
為了讓巨獸般的模型能在資源有限的邊緣環境中運作,「模型量化」(Model Quantization)逐漸成為主流手法。傳統的做法大多是後訓練量化,即在完成全精度(如 FP16)訓練後,再將模型權重降精度到 FP8 或 INT8。雖然簡單直接,但這種做法往往會伴隨性能的顯著損失。而相對進階的「量化感知訓練」(Quantization-Aware Training, QAT)則允許模型在訓練過程中就意識到精度限制,進而保持更好的性能。
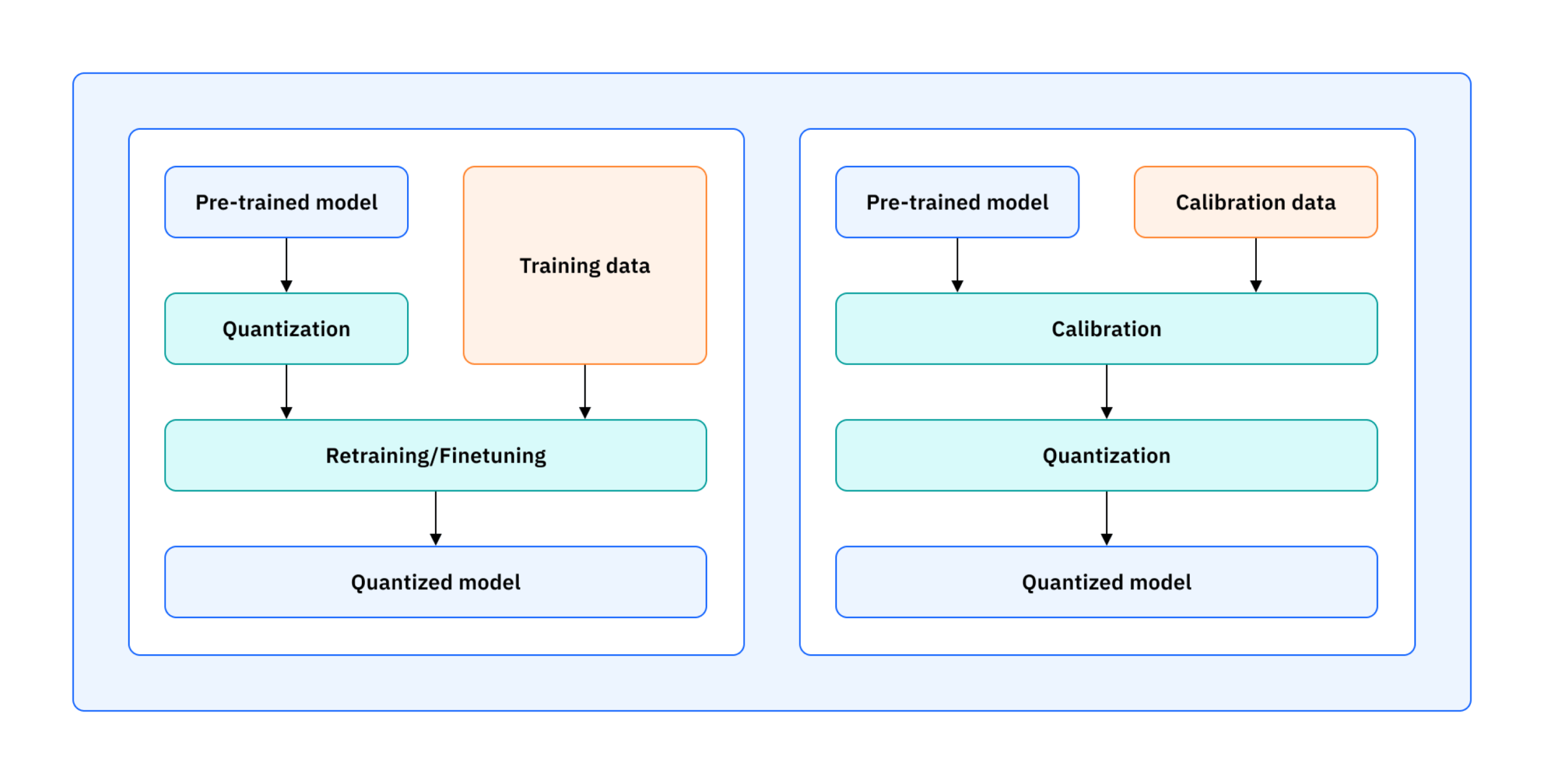
Quantization-Aware Training (QAT, 左) vs Post-Training Quantization (PTQ, 右)(source)
正是在這個背景下,BitNet 的出現顯得格外引人注目。它不是在訓練後「削減」權重,而是從一開始就以 1-bit 權重出發,徹底挑戰人們對語言模型精度的既有想像。
BitNet:1-bit Transformer 的誕生
BitNet 的核心創新在於「BitLinear」,這是一種專為 1-bit 訓練設計的替代層,取代了 PyTorch 中的 nn.Linear。透過這樣的替換,BitNet 不僅能以 1.58 bit 的權重進行運算,還能在多個語言建模基準上展現出與 FP16 或 8-bit Transformer 相競爭的性能。
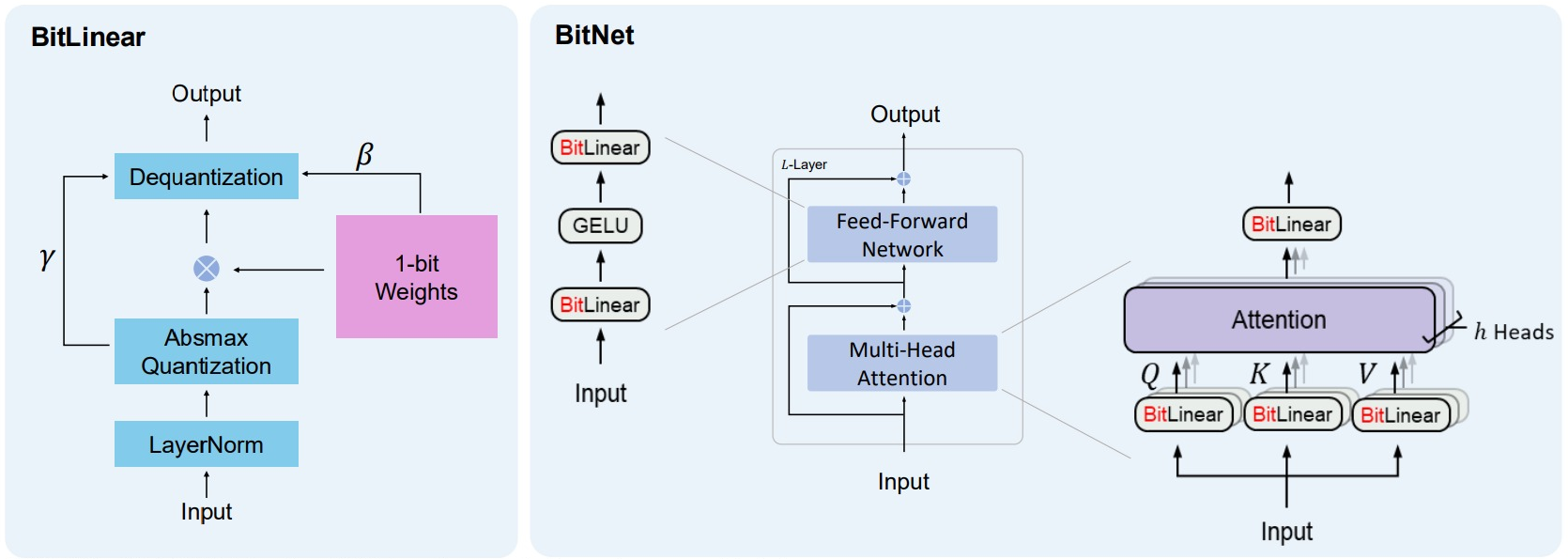
研究團隊的實驗顯示(見延伸閱讀論文),BitNet 在語言建模任務上維持了可觀的準確度,同時大幅降低了記憶體占用與能耗。更重要的是,它遵循了與全精度 Transformer 相同的縮放定律(Scaling Law),意味著這種 1-bit 模型並非短期權宜之計,而是具備擴展到更大規模的潛力。
換句話說,BitNet 並不是一個單純的「壓縮版本」,而是可能重新定義未來模型架構的一種新方式。
》延伸閱讀:
[1] BitNet: Scaling 1-bit Transformers for Large Language Models(2023/10/17發表論文)
[2] The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits(2024/2/27發表論文)
[3] 1-bit AI Infra: Part 1.1, Fast and Lossless BitNet b1.58 Inference on CPUs(2024/10/23發表)
[4] BitNet b1.58 2B4T Technical Report(2025/4/16發表論文)
為什麼 1-bit 意義重大?
相比 FP16 或 FP8,BitNet 的權重甚至不是傳統的二元,而是三元集合 {-1, 0, 1}。這樣的設計不僅壓縮了儲存成本,更在理論上為「無矩陣乘法」的語言模型設計鋪平道路。這意味著未來的模型推理可能跳脫傳統線性代數運算的框架,進一步提升速度與能源效率。
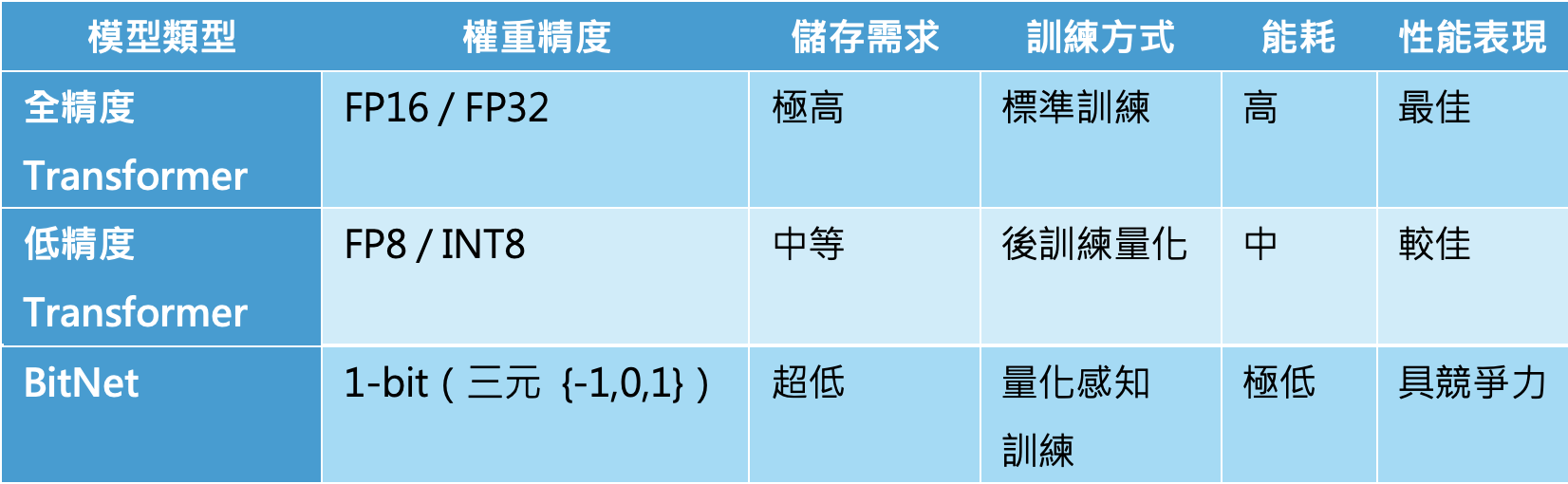
不同精度模型比較
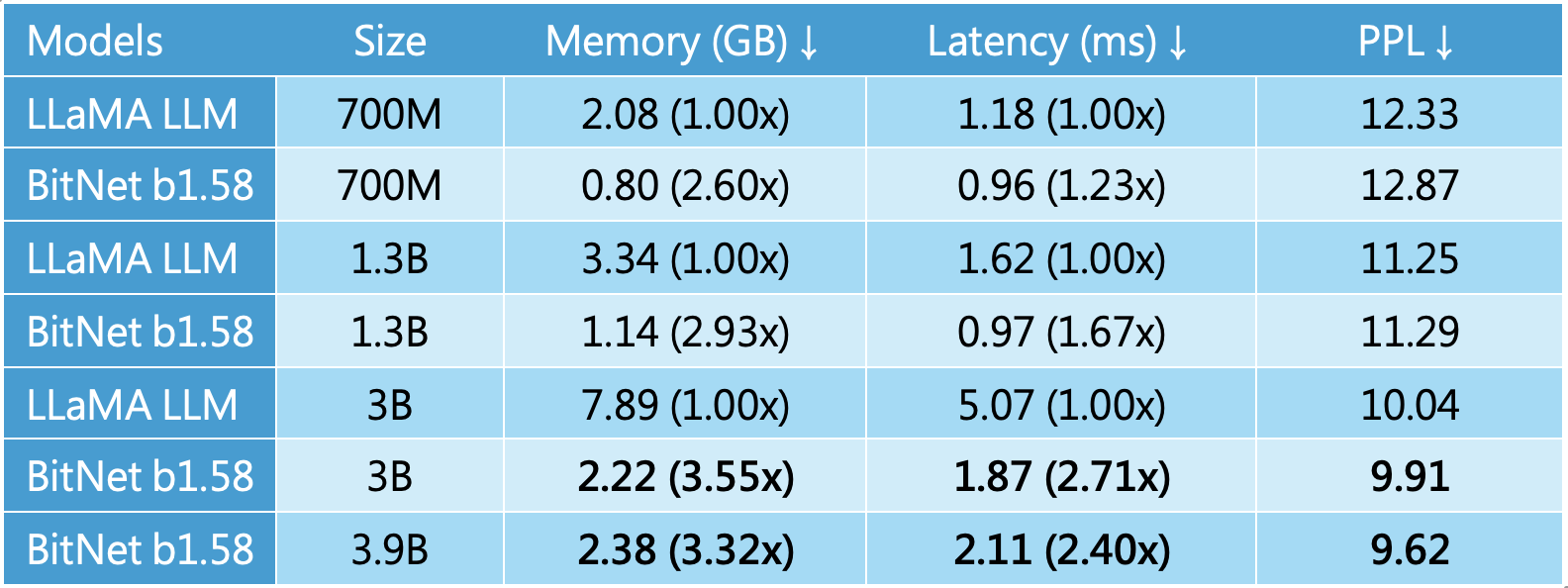
LlaMa LLM與BitNet b1.58效能比較
但挑戰也隨之而來。1-bit 模型必須從零開始訓練,因為現有的微調技術(如將非 BitNet 模型直接轉換為 BitNet 模型)效果不佳。這也使得社群在推動 BitNet 的落地上,面臨效能與實際部署時的便利性和可用性等難題。
社群挑戰與突破
去年(2024)10月微軟釋出了 bitnet.cpp 框架,使部分架構的 CPU 推理速度提升高達五倍,這讓 BitNet 在本地端部署更具吸引力。目前官方模型是BitNet-b1.58-2B-4T, 支援的1-bit模型如下:
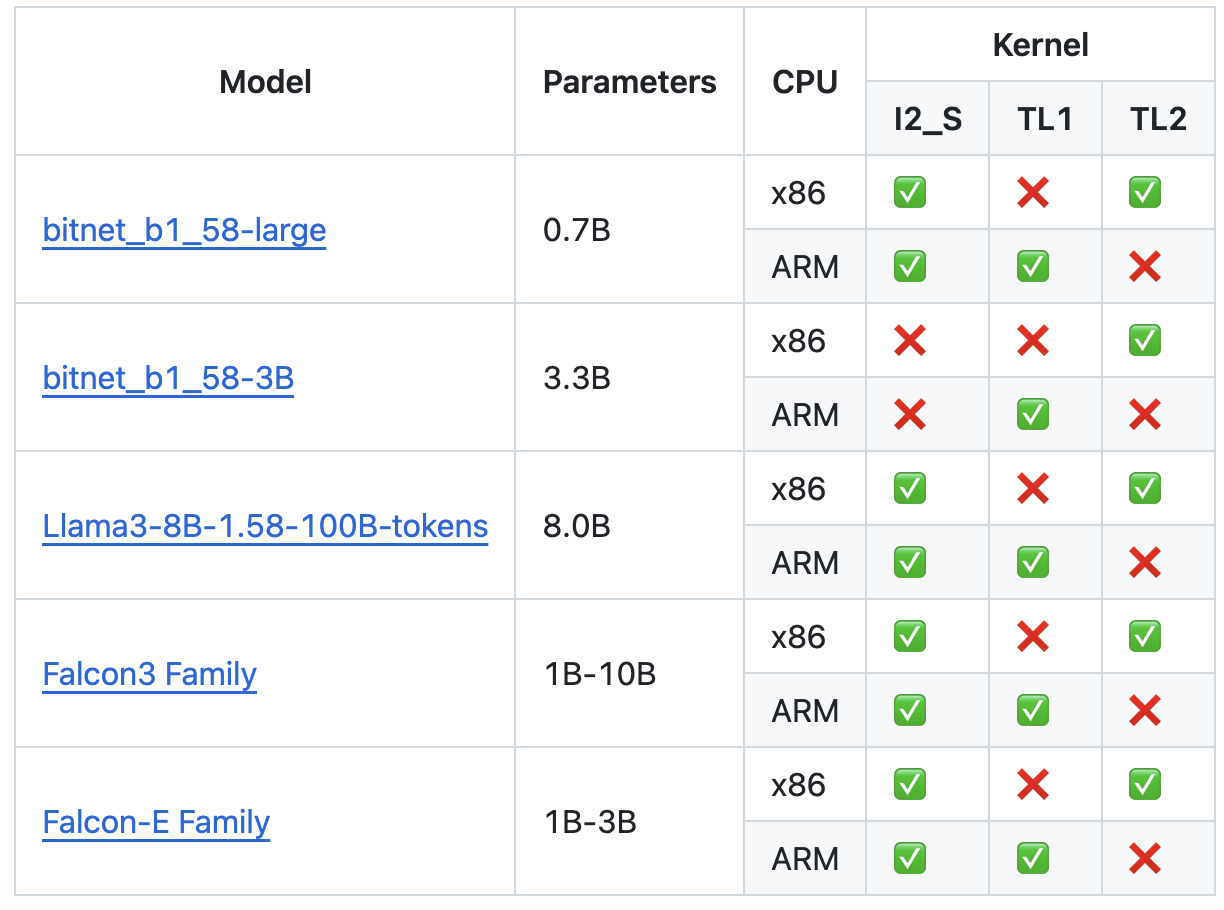
然而,社群普遍仍將 BitNet 視為「概念驗證」而非成熟技術,主要因為:
- 效能差距:現有 BitNet 模型尚未能全面匹敵同規模的傳統模型。
- 可取用性不足:由於需要從零開始訓練,使用門檻高昂,限制了其普及。
Falcon-Edge:全新訓練典範
在 BitNet 的啟發下,來自阿拉伯的TII先進研究組織進一步推出了 Falcon-Edge,採用一種全新的預訓練流程,能同時生成多種格式的模型:
- bfloat16 的非量化模型,保留高精度以便某些場景應用;
- 原生 BitNet 模型,追求極致的效率與能耗表現;
- 預先量化的 BitNet 變體,為微調與應用落地提供便利。
Falcon-Edge 目前提供 1B、3B與最新的2B等參數規模,並且區分基礎型與指令調優型,讓開發者能根據需求自由選擇。這種「一套流程,產出多種模型」的方法,為開發者節省了大量人力與計算資源,也打開了 BitNet 模型在邊緣端與多樣化應用中的可能性。
onebitllms:輕量級的微調方案
![]() 為了降低使用門檻,TII團隊還推出了 onebitllms,這是一個輕量級 Python 套件,可無縫插入常用的 LLM 微調工具鏈。它的功能包括:
為了降低使用門檻,TII團隊還推出了 onebitllms,這是一個輕量級 Python 套件,可無縫插入常用的 LLM 微調工具鏈。它的功能包括:
- 將預先量化的模型檢查點轉換為 BitNet 訓練格式;
- 提供 bfloat16 與 BitNet 兩種量化訓練檢查點的互轉方法;
- 支援更細粒度的控制,例如透過 BitLinear 注入裸核與 Triton 核心。
雖然目前僅支援完整微調,且規模偏小,但這為未來支援 參數高效微調(PEFT) 打下基礎。這意味著在不久的將來,BitNet 也能擁有類似 LoRA 的輕量化微調方法,大幅降低應用門檻。
未來的研究藍圖
BitNet 與 Falcon-Edge 的誕生不僅僅是一個技術突破,更像是一場未完成的實驗。研究團隊與社群正在探索的方向包括:
- 在 GPU 上開發更高效的推理核心,使 BitNet 不僅在 CPU 上,甚至在 GPU 上也能超越傳統模型;
- 引入 PEFT 微調方法,讓 BitNet 真正進入應用場景;
- 提升檢查點的通用性,減少 BitNet 與 bfloat16 模型之間的性能落差;
- 延伸至多模態應用,甚至打造第一個基於 BitNet 的視覺語言模型(VLM)。
這些方向的探索,不僅將決定 BitNet 能否從實驗室走向大規模應用,也可能徹底改變未來 AI 模型的設計方式。
1-bit 革命的開端
從 BitNet 的 1-bit Transformer,到 Falcon-Edge 的全新預訓練範式,再到 onebitllms 的輕量化工具鏈,我們看到的是一條從概念驗證走向實用化的技術路徑。雖然目前 BitNet 的效能與可用性仍在追趕傳統 LLM,但其在記憶體效率、能源消耗與未來可擴展性上的潛力,已足以讓人將其視為下一代 AI 架構的重要候選。
正如 GPU 曾為深度學習的黃金時代鋪路,BitNet 與其衍生生態系或許正在為「高效 AI」的時代拉開序幕。這場 1-bit 革命,才剛剛開始。
》延伸閱讀:
[5] Quantization aware training技術導讀
[6] Quantization-Aware Training for Large Language Models with PyTorch
[7] Bitnet.cpp an opensource LLM platform by Microsoft

- 1-bit LLM的革命:BitNet 的新典範與挑戰 - 2025/08/26
- Phi 4:「小而強」的專注型SLM模型 - 2025/08/21
- LLM如何「落地」?蒸餾、壓縮與微調技術比一比 - 2025/08/18
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!