YOLOv12 是 YOLO 系列中的最新版本,首次成功地將 Transformer 的注意力機制整合進即時物件偵測架構中,實現了高準確率與即時性之間的平衡。這一版本引入了多項創新設計,使得注意力機制能夠在不犧牲速度的情況下,提升模型的辨識能力,以下是三大創新設計:
1. Area Attention Module(A²)
傳統的自注意力機制(Self-Attention)在處理高解析度影像時,計算成本高且效率低下。YOLOv12 引入了 Area Attention Module(A²),將特徵圖劃分為多個區域,對每個區域進行注意力計算,既保留了大範圍的感受野,又顯著降低了計算複雜度。這種方法有效地提升了模型在複雜場景下的辨識能力,同時維持了高效的推論速度。 (延伸閱讀)

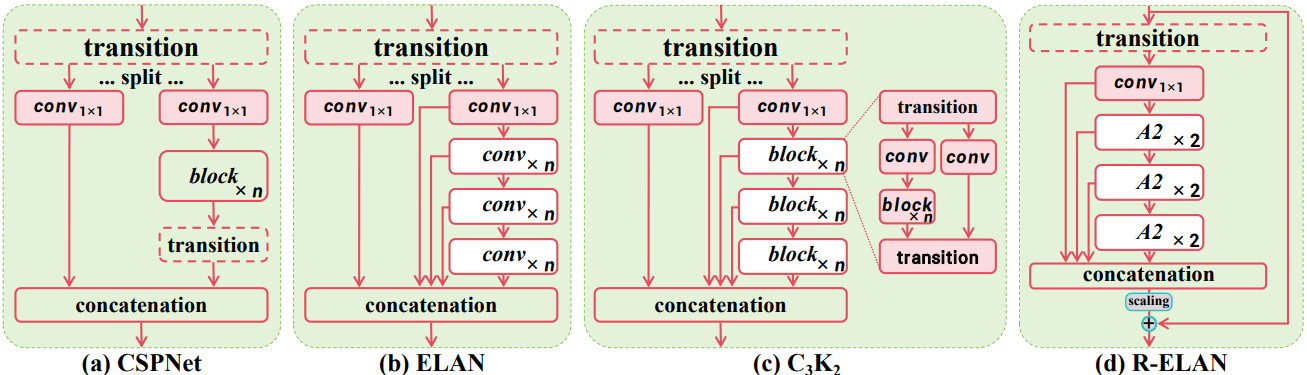
2. Residual Efficient Layer Aggregation Networks(R-ELAN)
為了改善深層模型的訓練效率和特徵融合能力,YOLOv12 採用了 R-ELAN 結構。這一設計在原有的 ELAN 基礎上,引入了殘差連接和瓶頸結構,提升了模型的表達能力和訓練穩定性,特別是在整合注意力機制後,能更有效地捕捉多尺度的特徵資訊。
3. FlashAttention 與其他優化
YOLOv12 還整合了 FlashAttention 技術,優化了記憶體存取模式,進一步提升了注意力計算的效率。此外,模型還進行了以下調整:
- 移除位置編碼(Positional Encoding),簡化模型結構。
- 調整 MLP 的擴展比例(從典型的 4 降至 1.2 或 2),平衡計算成本。
- 引入 7×7 的可分離卷積(Separable Convolution)作為位置感知模組,增強模型對空間資訊的理解。
效能與應用場景
根據實驗結果,YOLOv12 在保持即時推論速度的同時,實現了更高的準確率。例如,YOLOv12-N 在 COCO val2017 資料集上達到了 40.6% 的 mAP,推論延遲僅為 1.64 毫秒,超越了 YOLOv10-N 和 YOLOv11-N 等先前版本。 (資料來源)
這使得 YOLOv12 特別適用於需要高準確率和即時性的應用場景,如:自動駕駛與智慧交通系統、即時監控與安防系統、機器人視覺與工業自動化、醫療影像分析與診斷等。
小結
YOLOv12 的推出標誌著即時物件偵測技術的一大進步,成功地將 Transformer 的注意力機制與 YOLO 架構融合,實現了高效能與高準確率的完美結合。這一創新為各種需要即時且精確辨識的應用場景提供了強大的技術支援。
》延伸閱讀:
YOLOv12: Object Detection with Attention
YOLO12: Attention-Centric Object Detection – Ultralytics YOLO Docs
How to Use YOLO12 for Object Detection with the Ultralytics Package | Is YOLO12 Fast or Slow?

- Anritsu攜手合作夥伴共同驗證AI天線最佳化技術 - 2026/03/31
- 從AI PC到邊緣終端 Intel以最新Core Ultra系列擴大混合運算版圖 - 2026/03/30
- NVIDIA與全球機器人生態系推動具生產規模的實體AI - 2026/03/27
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!
