近來VLM當紅,而實現VLM視覺辨識的關鍵技術之一為ViT,本文即來為各位介紹一下。
ViT(Vision Transformer)是一種基於 Transformer 架構的電腦視覺模型,由 Google 在 2020 年提出。與傳統的卷積神經網路(CNN) 不同,ViT 直接使用 Transformer 來處理影像數據,並在許多影像分類任務中達到與或超越 CNN 的效果。
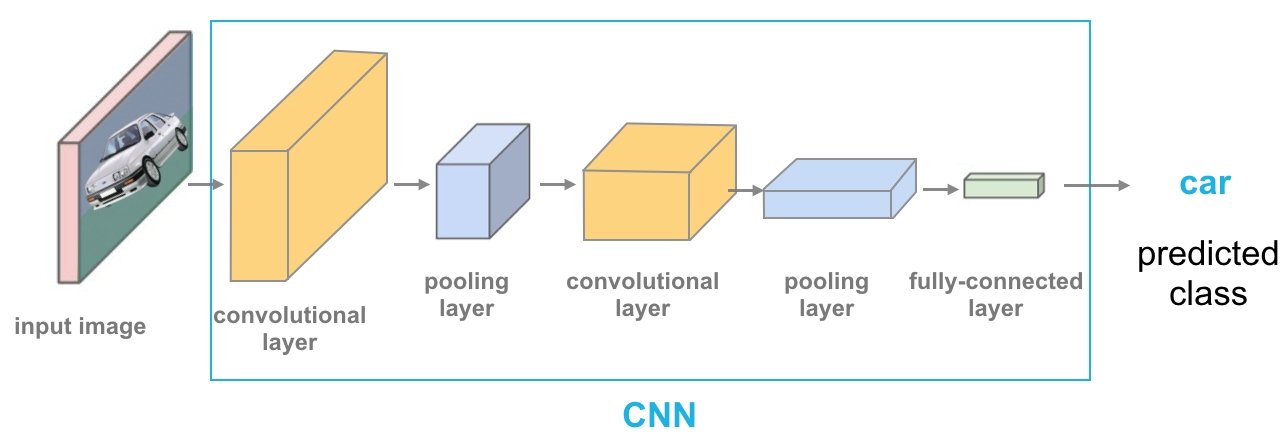
ViT 的工作方式類似於 CNN,但它使用自注意力機制(Self-Attention)來捕捉全局特徵,使其能夠更靈活地學習影像資訊。然而,它無法直接處理文字或跨模態(Multimodal)資訊。ViT 的主要特點是將影像分割成固定大小的補丁(Patches),然後像自然語言處理(NLP)中的詞嵌入(Word Embedding)一樣,將這些補丁展平成向量,並加上位置編碼(Positional Encoding),使模型能夠理解影像中的位置資訊。
接著輸入 Transformer 進行處理,透過 Transformer 的輸出結果,使用 MLP(多層感知機)進行分類,這作法類似於傳統 CNN 最後的全連接層(Fully Connected Layer)。
ViT常見應用包括:
- 影像分類(Image Classification)
- 物件偵測(Object Detection)
- 影像分割(Image Segmentation)
ViT 相較於CNN的優勢
1.全局特徵學習能力:
傳統 CNN 主要透過局部卷積來提取特徵,而 ViT 透過自注意力機制(Self-Attention),可以一次性考慮整張影像的全局關係,使其在理解長距離特徵時更有優勢。
2.擴展性強:
ViT 可以適應不同尺寸的影像,且隨著模型變大,效果提升更明顯,相比 CNN,ViT 受益於大規模數據的訓練更多。
3.可遷移性強:
ViT 在大規模數據(如 ImageNet 或 JFT-300M)上訓練後,可以 遷移(Transfer Learning) 到不同的視覺任務,例如物件偵測、語義分割等,並取得良好的效果。
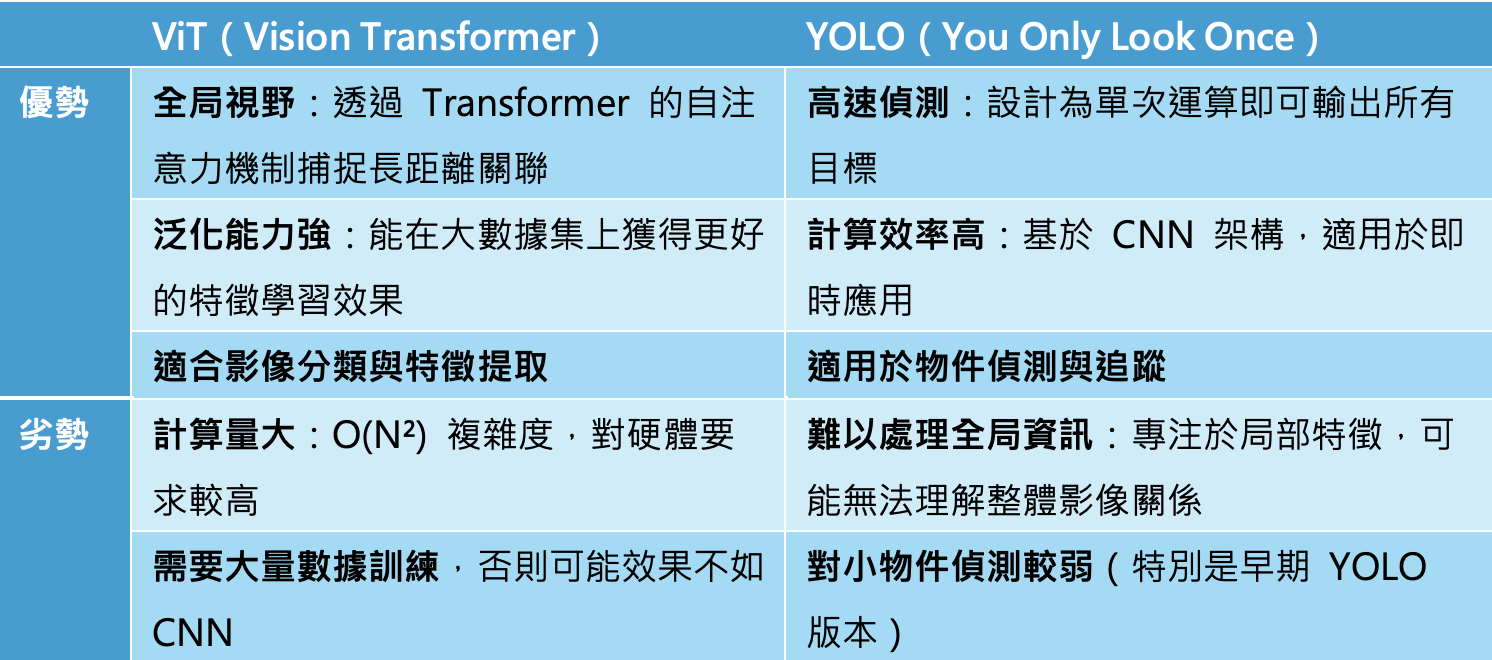
下表以YOLO(CNN為基礎)來與ViT進行比較:
ViT 的挑戰與克服
不過,ViT 也有其限制,它的表現高度依賴大規模數據集,如果數據不足,ViT 的效果可能不如 CNN,因為 CNN 透過卷積結構內建了一些先驗知識(如邊緣偵測)。此外,Transformer 需要大量計算資源,尤其在 高解析度影像 上,自注意力機制的計算量是 O(N²)(N 是補丁數量),相比 CNN 的 O(N),更消耗記憶體與算力。
為了克服 ViT 計算量大的問題,許多改進版本相繼出現,例如:
- DeiT(Data-efficient Image Transformer):由 Facebook 提出,透過更高效的訓練策略,使 ViT 在 小數據集 上也能獲得良好效果。
- Swin Transformer:引入「滑動窗口注意力(Shifted Window Attention)」,使 ViT 具備 CNN 的層次化特徵學習能力,並大幅降低計算量。
- CvT(Convolutional Vision Transformer):將 CNN 與 ViT 結合,既保留 CNN 的局部感知能力,也利用 Transformer 的全局特徵學習能力。
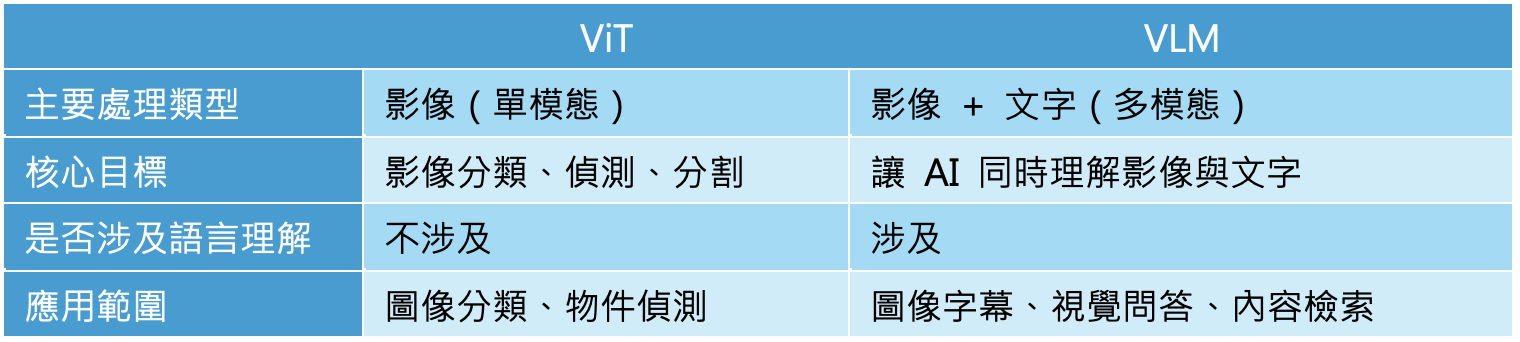
ViT vs. VLM
ViT 和 VLM(Vision-Language Model,視覺語言模型)之間的關係密切,因為 ViT 是許多 VLM 的核心組件之一,主要負責處理影像資訊。VLM的目標是讓 AI 同時理解影像與文字,並學會兩者之間的關聯。例如,當你輸入一張圖片與一段文字,VLM 可以用來:
- 影像字幕生成(Image Captioning):為圖片自動生成描述文字。
- 視覺問答(Visual Question Answering, VQA):根據圖片回答問題。
- 多模態內容檢索(Multimodal Retrieval):根據文字找到相關圖片,或根據圖片找到相關文字。
在技術上,VLM 進一步結合語言模型的多模態(Multimodal)模型,為了讓 VLM 能夠處理影像,它通常會使用 ViT 或 CNN 作為影像特徵提取器,然後與語言模型(如 Transformer 或 LLM)結合,讓 AI 能夠理解影像與文字的關聯,適用於更廣泛的 AI 應用,如 AI 助理、圖像描述等。兩者的定位差異比較如下表:
ViT 在許多 VLM 中扮演 影像特徵提取器的角色,與 NLP 模型(如 BERT、GPT)合作,讓模型能夠理解影像與文字的關聯。以CLIP為例,CLIP 由 OpenAI 提出,使用 ViT 作為影像編碼器,BERT-like Transformer 作為文字編碼器,透過對比學習(Contrastive Learning) 讓 AI 學會將影像與對應的文字配對。例如,當你輸入圖片時,CLIP 可以根據內容匹配最相關的描述。
小結
ViT 顛覆了傳統 CNN 在視覺領域的統治地位,透過 Transformer 直接處理影像,展現了極大的潛力。然而,它仍然面臨計算成本高、對數據需求大的挑戰。隨著技術發展,ViT 及其變體正在逐漸克服這些問題,未來有望在圖像分類、物件偵測、醫學影像分析、自動駕駛等領域發揮更大作用。
(責任編輯:歐敏銓)
》延伸閱讀:
【AI知多少】單模態到多模態:LLM、VLM、Video-LM
Vision Transformers (ViT) in Image Recognition

- 【Podcast】AI 機器人安全革命:從功能安全到軟體定義安全 - 2026/04/10
- RISC-V技術成熟度與全球AI落地應用現況剖析 - 2026/04/10
- 宇樹、智元出貨囊括八成 預估2026年中國人形機器人產量年增94% - 2026/04/09
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!

