AI技術名詞層出不窮,你知道LLM與VLM有何差異?VLM的V是指圖片還是影片,還是都涵蓋呢?
從單模態LLM到多模態
先談LLM和VLM的差異,一個是大型語言模型(Large Language Model),一個是視覺語言模型(Vision-Language Model),這裏的視覺指的是平面的影像(或稱圖片);前者只處理單一模態:文字(Text),後者則處理兩種模態:圖片 + 文字,也就是進入了所謂多模態(Multimodal)的領域了。

事實上,多模態AI通常以LLM的文字處理能力為基礎,透過融合視覺(Vision)、語音(Speech)、影片(Video)、感測數據(Sensor Data)等其他模態的編碼器來發展出多模態系統,例如:GPT-4V(V 是 Vision)在 GPT-4 內加入視覺的處理能力,讓它能「看圖回答問題」;Google的Gemini則是融合 LLM 與視覺、語音處理能力,變成真正的多模態 AI。

VLM vs. Video-LM
再來看VLM的V,Vision和Video都是V,很容易讓人混淆,而VLM的V是Vision,所以可以清楚它是處理平面的視覺影像,以及語言文字。不過,Vision和Video兩者確實有關係性:影片是一連串的圖片串連在一起,但多了時間資訊,而處理影片 + 語言的多模態AI模型,稱為影片語言模型Video-LM(Video Language Model)。
(註:還有一個V是Visual,它和Vision都指視覺,但Visual是形容詞用法,如Visual Processing,Vision則是名詞,如Computer Vision)
VLM與Video-LM通常屬於不同的模型領域,代表性的VLM處理功能如下:
-
- CLIP(OpenAI):學習圖像與文字的關聯。
- BLIP:生成圖片描述,或根據文字搜尋圖片。
- LLaVA:類似 ChatGPT,但可以看圖回答問題。
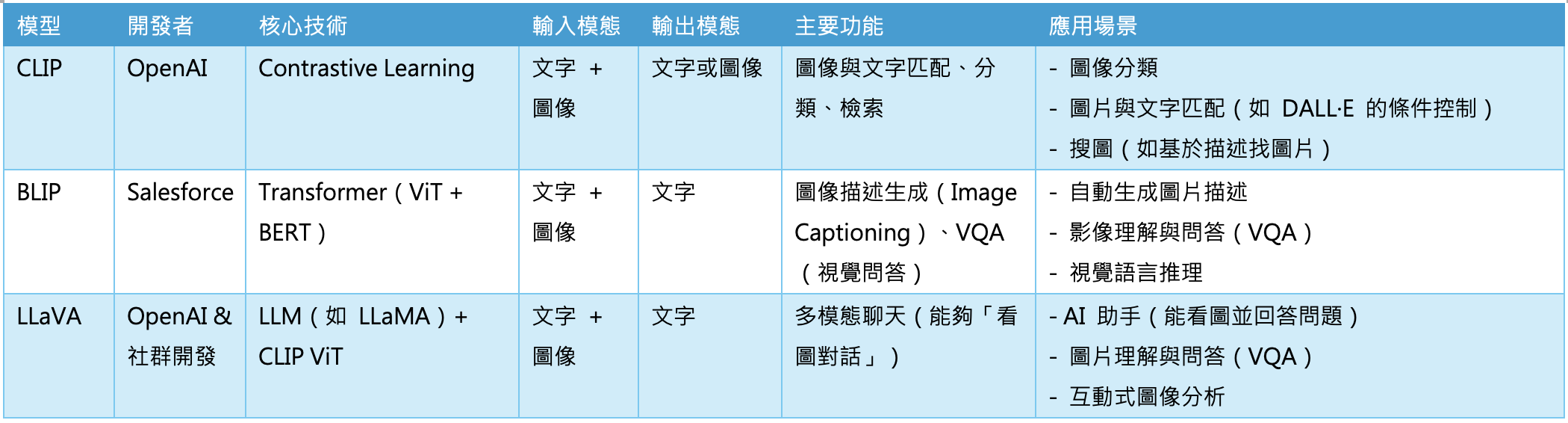
CLIP、BLIP、LLaVA比較表(製表:MakerPRO+ChatGPT)
影片(Video)與圖像(Image)的處理方式不同,因為影片包含時間維度,所以需要考慮,時間上的特徵(Temporal Features)、連續幀之間的關聯性、動作辨識(Action Recognition),不過,有些Video-LM模型也能同時處理圖片及影片,以下為幾個Video-LM模型:
-
- Video-BERT:處理影片與文字,學習它們之間的關係。
- VIOLET:用 Transformer 來建構影片-語言模型。
- Flamingo(DeepMind):可以處理靜態圖像,也能擴展到影片。
- GPT-4V、Gemini(Google):能夠同時處理圖像、影片、文字、語音,屬於更廣義的多模態 AI。
OpenAI的Sora平台也是Video-LM的強大應用,它主要功能是由文字描述來生成影片,這表示它至少需要處理:
- 自然語言理解(NLP):解析用戶輸入的文字提示(Prompt)。
- 視覺建模(Vision):根據提示生成連續的視覺內容。
- 時間序列建模(Temporal Modeling):理解並生成動態場景,確保影片內容流暢一致。
這樣的結構也符合 Multimodal AI 的核心概念,因為它必須同時處理語言和連續視覺(影片),甚至可能涉及物理模擬(例如讓物件運動符合現實世界的物理法則)。
小結
從單模態的LLM出發,目前的AI正如火如荼朝向多模態模型發展,特別是處理語言 + 平面視覺或連續視覺的VLM及Video-LM模型,讓AI看圖說故事或說故事生影片的情境成真,未來,更多的模態將互相關聯,五花八門的應用值得期待。

- 【產業剖析】人形機器人火熱背後的現實難題 - 2026/06/15
- 【COMPUTEX 2026】以「具身智慧界Android」為定位的韓國Circulus - 2026/06/05
- 演算法戰爭:AI自主武器的「去人性化」危機! - 2026/06/02
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!
