作者:尤濬哲
2024年12月17日,NVIDIA執行長皮衣男黃仁勳在毫無預告下,在YT發布一個影片,只見他趣味地從廚房的烤爐端出一個「蛋糕」, 說道這是一台全新的AI主機“Jetson Orin Nano Super Developer Kit”,效能提升1.7倍,具有Cuda、cuDNN神經網路且透過全新的架構可以處理機器人以及大型語言模型。
這台號稱全新的Jetson Orin Nano “Super” 具有以下規格:
- 6 Core ARM Cortex78AR
- 1024 CUDA
- 32 Tensor
- 8GB 128-bit LPDDR5
這時候像我網路柯南就聞到一點奇怪的氣味,因為這個規格跟我目前手上的Jetson Orin Nano “without Super” 不是完全一樣的嗎?
這個問題立即就有人在NVIDIA的官方論壇中詢問,“Is that mean there is no hardware difference? It’s just a BSP/software performance improvement?”
官方的回覆是,“Yes, the existing Jetson Nano Orin Developer Kit can be upgraded to Jetson Orin Nano Super Developer Kit with this software update.”
而前幾天,官方的FAQ已經加入這個問題的標準解答

資料來源:NVIDIA官方網站
也就是說,這台所謂的全新的Jetson Orin Nano “Super”,與舊版的Orin完全無硬體上的差異,而所謂的效能提升1.7倍就是透過軟體升級來達成的,如果你手上有一台舊版Orin,只要安裝新的軟體,就可以穿上「紅內褲」變成Super的超人模式,不需要再為了這號稱的1.7倍效能購買新裝置,而原本Nano這個產品線的所有機器都會以Super型態出廠,不會再有純Nano規格的產品。
這樣說來,黃仁勳自稱這台為All brand New,事實上並非是全新的架構,只是舊瓶裝新酒,那麼你肯定會控告這個廣告華而不實對吧,錯錯錯,這次NVIDIA的Jetson Orin Nano “Super”效能提昇了,但定價卻從$499 (約台幣16,400)降到$249 (約台幣8,200),對消費者來說這才是真正的實惠。
Orin Nano Super的優勢
那麼一個舊硬體框架是如何透過軟體提升到1.7倍效能?另外一個問題則是,8G小機器加上了最佳化軟體就能飛天鑽地嗎?
在這篇文章我們先回答第一個問題,Super Mode到底是從哪裡壓榨出來的?
答案可能是:加壓超頻。
我們觀察兩個不同Jetpack套件,前版本5.1與Super版本6.1,可以發現,早期的電源模式最高15W,而在Super版比15W還多了MAXN選項,根據官方數據MAXN代表大約25W,那麼我們選擇MAXN模式後,會有什麼改變呢?
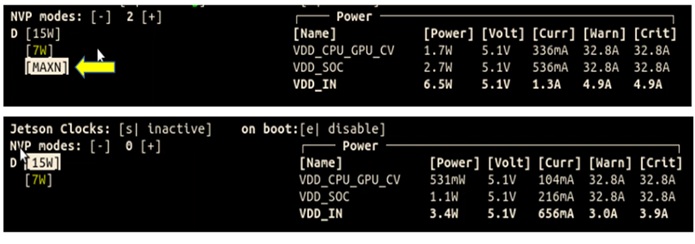
下圖則是將電源模式調整為MAXN模式後,比較其運作數據可以發現CPU運作頻率可高達1.7GHz(原本1.5 GHz),記憶體從2.1 GHz提升到3.2 GHz。
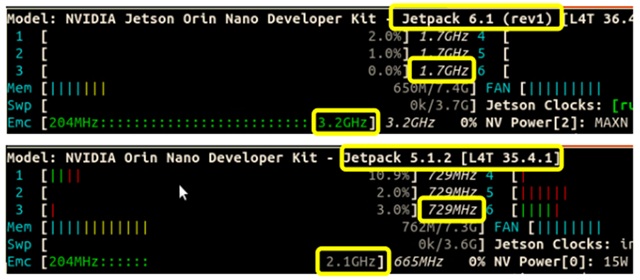
依照官方數據,與AI運算相關的主要裝置GPU,其頻率更從原本的635 MHz提升到1020 MHz,這也就是主要的Super模式的由來。經由這幾個方向的壓榨,我們可以看到裝置在AI效能有顯著的提升,包括整數及浮點數的神經網路運算大約都能提升70%以上效能。
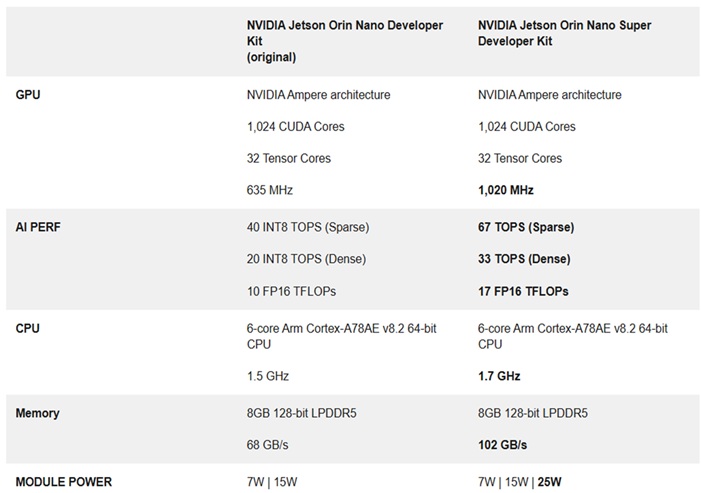
效能比較表(來源:NVIDIA)
如果你手上擁有的不是Nano這個規格的,是不是就沒辦法穿上紅內褲變成Super模式呢?嘿嘿,見鬼了,Orin NX也有Super模式,效能一樣提升近50%,但(人生最恨的就是這個但)NX沒有降價,目前依舊為原價,另外Orin中最高等級的AGX似乎還沒有紅內褲的消息,有賴後續更新。
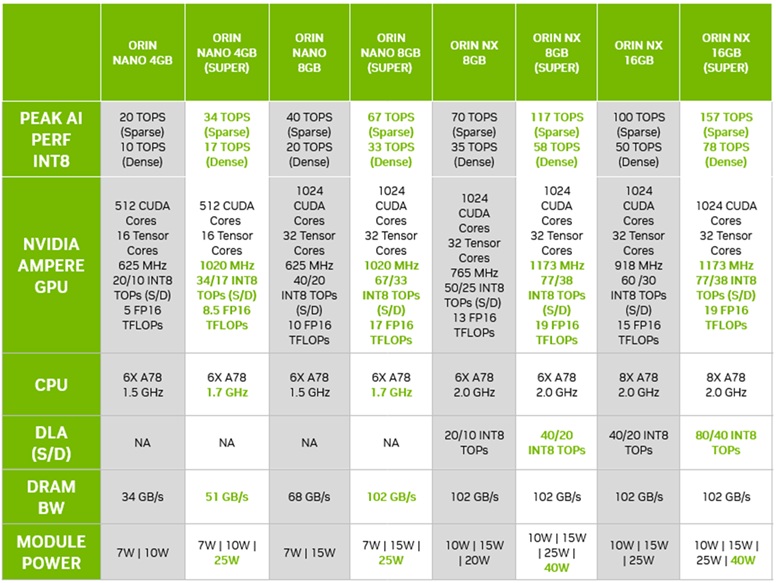
圖片來源:NVIDIA
Nano實體開箱
接著筆者要拿出殺手鐧了:世界知名的工業電腦製造商研華科技(Advantech)提供一台Jetson Orin Nano(EPC-R7300IF-ALA1NN)給筆者測試,這台Nano出場就已經改成Super模式了,不僅如此,現在因應各領域的AI流行趨勢,目前正在全面特價中,現在就來開箱。

開箱後可以看到與一般開發板不同的地方,研華科技專業的工業電腦工藝讓這台裝置穿上厚厚的盔甲,抵抗工業生產環境的各種職業災害。
拆掉上方的散熱片,非常厚實,光是這個散熱片就重達780g,可以說是用料實在,也可以發現整機不需要散熱風扇,避免了風扇故障帶來的風險。

前方面板則增加了SIM卡插槽及USB OTG,後續可以讓裝置直接升級到5G LTE網路基地台上網,對於部份沒有Wi-Fi的廠區,可以說是非常好的方案。

後方面板則有雙網路卡、HDMI、雙USB3.0、及一個工業電源插頭。

內部設計也可以見到研華科技的用心,都已經預留WiFi模組、5G LTE模組、SSD模組接口,讓你擴充方便,適合所有的應用場域。

系統狀態表開機後可以看到,本系統出廠都已經改成Super模式,下圖為系統狀態表,也可以看到MAXN選項已經出現。

實測 Jetson Orin “Super” 效能提升
前面談到Jetson Orin系列產品可以透過Super模式(MAXN)來大幅提升效能,我們就來測試看看效能到底提升了多少?本次實測將以目前最流行的LLM大型語言模型 -Llama-3.2,而效能比較的部分則分成Super模式、25W、15W進行全面的測試,由於筆者手上已經沒有傳統版Jetson Orin,因此就以15W模式做為傳統板的基準進行分析。
本次使用Llama來測試邊緣設備的效能,主要是因為Llama 3.2提供了輕量級的1B和3B版本,專為低功耗設備與移動應用最佳化,適合在邊緣運算環境中進行推論測試。這些模型支援長達 128K 的上下文,使其能夠處理較長的指令與數據,同時保持高效的推論速度。
此外,Llama的架構經過最佳化,可以在各種嵌入式系統或其他低功耗硬體上運作,讓我們能夠評估設備在實際應用中的運算能力、記憶體占用與能耗表現。因此,透過 Llama 來測試邊緣設備,不僅能檢驗其 AI 運算能力,也能驗證Jetson Orin在資源受限環境下的穩定性與效能極限。
一、安裝測試環境
首先我們安裝Ollama。Ollama 是一個開源軟體平台,允許使用者在本地電腦上運作LLM,無需依賴雲端服務。提供強大功能的同時保持易用性,支持運作、管理和自訂各種開源語言模型,包括 Llama 2、Mistral 和 CodeLlama。
我們將使用 Ollama 來運作 LLaMA 3.2 大型語言模型集合,作為基礎聊天機器人。安裝指令如下:

從上面的安裝過程可以發現,Ollama安裝時會先檢測環境,並下載對應的版本,例如在安裝過程中發現是JetPack 6就下載其對應的元件。
安裝完畢後,就可以再指定要執行的模型,本次我們要執行的是llama3.2,執行指令如下:
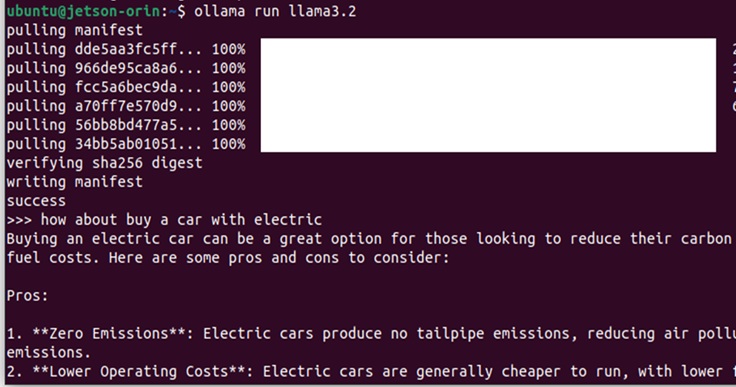
安裝過程及執行過程
待執行完畢後,看到>>>的提示符號就可以開始對話了,我詢問了一個問題是有關購買電動車的問題,後續就可以等候AI來盡情發揮了。
當環境安裝完畢,就進入大家期待的環節,到底皮衣男黃仁勳口中的1.7倍效能的紅包是真的還是假的呢?讓我們實際動手測試看看。
二、開始測試
如前所述,我們將測試三個版本的功耗來模擬Super模式及傳統模式,再來比較差異,雖然是非正規測試,我們還是保持公平性,1. 首先更換模式必須重新開機避免AI答題Cache的問題,2. 所有模式都會詢問五個問題,問題有簡單有複雜,並求其平均值,避免單一問題造成偏移問題。
本次測試的問題列表:
- hello world
- Who are you
- How about electric car
- What is CSS
- How about nuclear power plant
如需要Ollama提供其執行效能時,僅須在執行後方加入 –verbose即可,因此指令為:
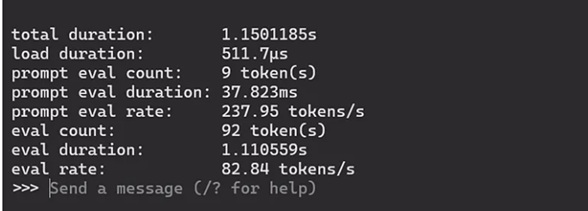
此後每個回答結束後,都會補上這次的執行效能。我們從中挑選四個重要的指標進行評估:
- Total duration 總時長:用以代表AI思考及回覆的總時間
- load duration載入時間:模型載入的時間
- prompt eval rate提示評估速度:理解問題時的速度,以Token/s來計算
- eval rate推理速度:生成答案時的速度,以Token/s來計算
以下為測試的結果列表(五題平均值)
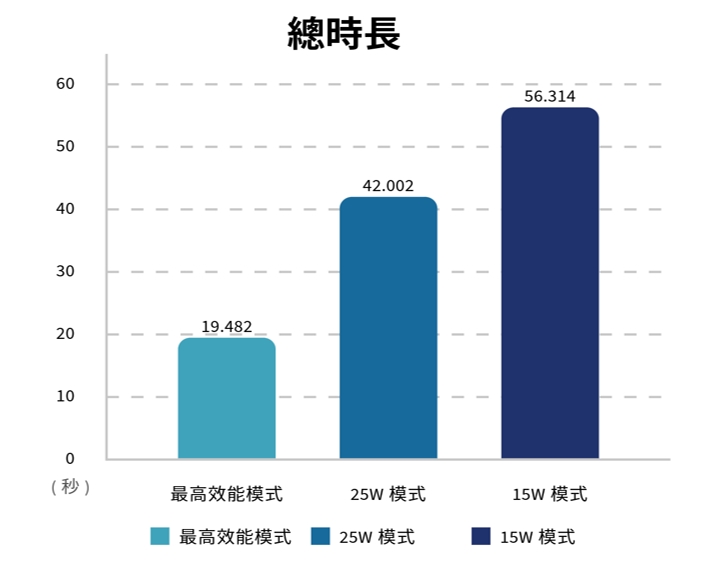
指標1:總時長
15W時,五個問題平均需要56秒,而25W僅需要42秒,最高效能則需要不到20秒鐘,換算效能提昇比例分別為25W:25.41%、MAXN:65.41%。本項目大致符合1.7倍的紅包利多。
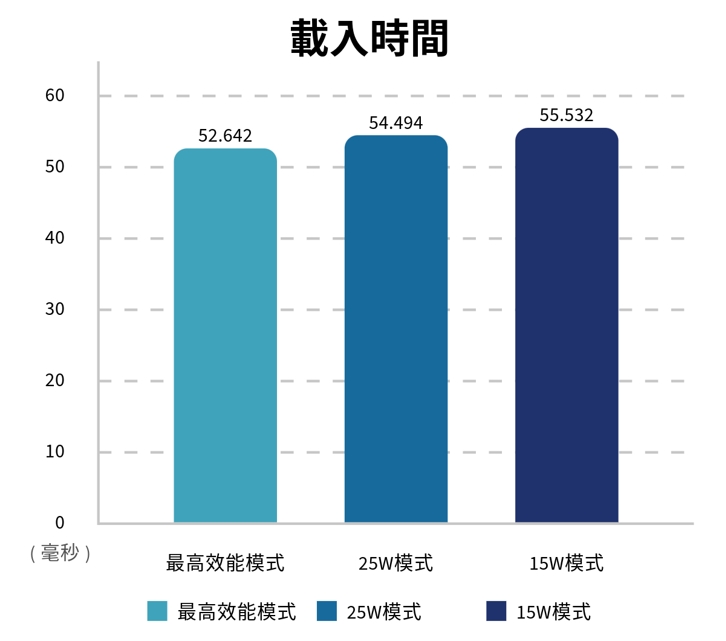
指標2:載入時間
本部份時間差異非常小,但依然可以看到MAXN與25W的效能都高過15W的傳統模式。
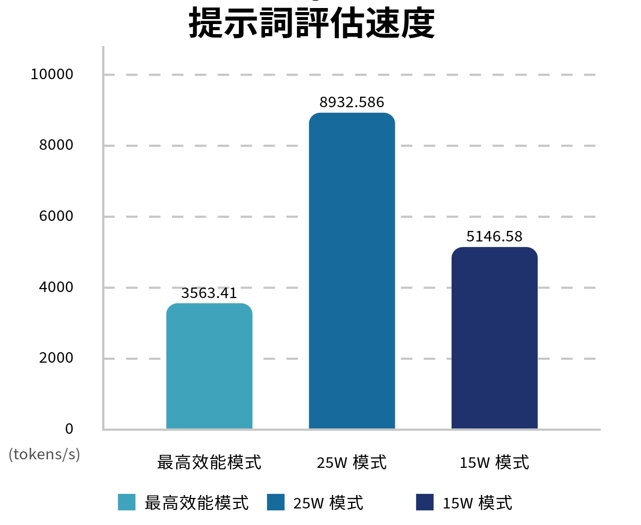
指標3:提示評估速度
本部份可以看到一個奇怪現象,雖然25W的效能高過15W的傳統模式,但MAXN卻大幅落後,這可能是因為樣本數太少,或者其他問題導致,另外提示評估問題一般都不複雜,Token也不會使用太多,重要性不如指標4推理速度。
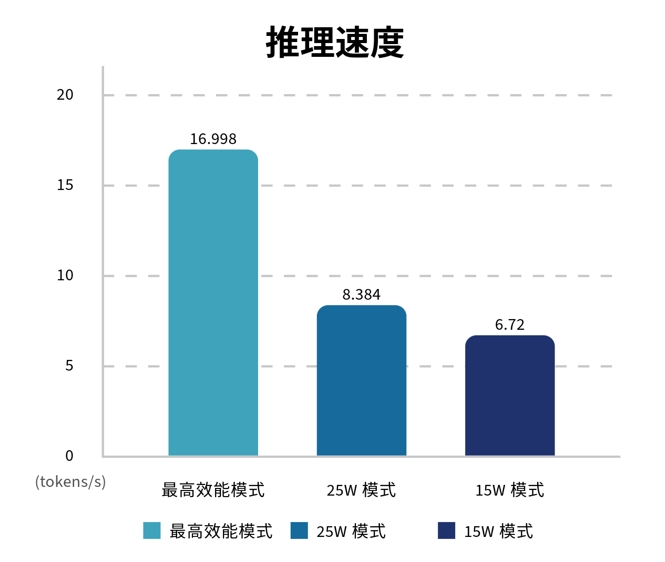
指標4:推理速度
推理速度可以說是LLM系統最重要的評估指標,因為「最傷腦筋思考」就屬這部份了,而在本部份MAXN可以說大幅領先,25W則高過15W不多,換算效能提升比例的話,分別是25W:24.7%,MAXN:152.98%,這也算接近1.7倍效能提升。
效能測試小結
Jetson Orin 的Super模式(MAXN)確實帶來了顯著的效能提升,本文透過實測Llama 3.2語言模型,在15W、25W及MAXN三種模式下進行比較,分析AI推論的效能差異。
測試環境使用Ollama 作為 LLM 運行平台,Llama 3.2 具有輕量級設計,適合邊緣運算環境。測試方法為五個固定問題,並記錄四項關鍵指標:總時長、載入時間、提示評估速度及推理速度。結果顯示,在MAXN模式下,總時長相較於15W模式縮短65.41%,推理速度提升152.98%,基本符合NVIDIA CEO 黃仁勳所稱的1.7 倍效能提升。
雖然載入時間變化不大,且提示評估速度在 MAXN 模式下反而下降,可能是樣本數或其他因素影響,但整體而言,Super 模式對LLM的推論效能提升顯著,適合需要高效AI推論的邊緣運算應用。
Jetson Orin在VLM的測試與應用
本篇文章的最後一部份我們來測試VLM的運用。
VLM(Vision Language Models,視覺語言模型)是結合影像和語言理解的AI模型,它的目標是讓模型像人類一樣,不僅能「看」到影像,還能理解影像的內容,並將其轉化為語言描述。與傳統的物件辨識模型(如YOLO、Faster R-CNN等)不同,這些模型專注於檢測圖像中的特定物體,進行物體定位和分類,而VLM則進行的是一種整體的圖像理解。
例如,VLM不像傳統物件偵測模型依賴圖像中的物體外觀來進行比對和分類,而是直接將整張圖像視為一個整體,並嘗試理解圖像中的場景、結構和各種關聯。它通過語言模型與視覺模型的結合,能夠從圖像中提取出更高層次的抽象信息,並生成對應的描述或推理。
舉個例子,人類在看一張照片時,會先對整體的場景進行理解,然後再分析圖像中的物體間的相互關係,例如:
- 場景識別:這是理解圖像的大致環境,可能是街道、公園、餐廳等。
- 結構分析:理解圖像中不同元素的關係。例如,兩個人在交談、一隻狗在草地上跑等。
- 語境推理:模型不僅知道圖像中的物體是什麼,還能推測它們可能的動作或語境。
VLM的應用範圍非常廣泛,包括但不限於:
- 圖像描述生成:根據圖像生成自然語言的描述。
- 視覺問答:根據圖片和問題回答具體問題。
- 圖像-文本匹配:將圖像與文本進行匹配或檢索。
這些模型透過大量的資料訓練,讓模型學會將視覺和語言訊息結合起來,達到類似人類的視覺理解能力。
VLM可以突破傳統影像物件辨識的限制,例如筆者在2024年曾與客戶談過一個專案,就是要辨別賣場中「小偷鬼鬼祟祟的行為」,在以往傳統的物件辨識領域這是很難辦到的,物件辨識只能知道物件的相對位置,我們可以能做到的是追蹤某個人在特定區域的出現,手上拿著什麼物品,但是鬼鬼祟祟這種行為到底要如何界定?必須要有一個準則才行,因此對方團隊列出了多個可能的準則,討論到最後我們決定放棄本專案,因為物件辨識來做這種行為判斷實在太難了。不過現在的VLM應用給我們一個可能的方向,以下筆者介紹幾個簡單的應用。
本次筆者使用的視覺模型為NanoVLM的VILA 1.5,關於模型的安裝設定可以參考jetson-ai-lab網站說明,而所使用的VILA 1.5(Vision-and-Language Pretrained Model)是一種先進的視覺語言預訓練模型,通過在大規模的圖像-文本對應資料集上進行預訓練,VILA 1.5能夠更好地理解和生成視覺內容的語言描述。VILA 1.5的核心創新在於強化了圖像與文本之間的關聯學習,使其能夠更精確地理解圖像中的細節及語境,並根據這些信息生成更自然且有邏輯性的語言回應。
筆者稍微修改的程式,讓它可以讀取OpenCV的Webcam影像,並將結果直接顯示在影像上,由於之前都是做影像辨識的專案,因此第一個測試就透過車輛辨識來了解道路交通的擁擠程度。
測試一:道路交通擁擠程度
目標:讓VLM辨識道路上車輛是否塞車。
提示語:辨識道路交通狀況,回覆一個形容詞,例如”busy”、”fine”、”empty”。
測試結果:辨識狀況相當好,我們使用Webcam拍攝電腦螢幕中的道路影像,模型會依據我們的提示語給予回覆。
圖A 是某條道路的即時影像,影像畫面中道路車流量極少,因此系統判斷為empty狀態:

圖B 是某快速道路的即時影像,影像畫面中道路車流擁擠,因此系統判斷為busy狀態:

本次希望模型使用關鍵語的方式回覆是因為這樣可以把路況的「標籤」直接存入資料庫,而不需要再透過人工了解語言內容。
結論:本次測試讓筆者對於以往僅依賴物件辨識的方法有了深刻體驗。傳統物件辨識需先計算車輛數量,再依據設定準則(如數量大於 10 判斷為擁擠、小於 5 判斷為順暢)來評估交通狀況。然而,在 VLM下,無需事先計算車輛數量,而是直接透過影像場景理解進行判斷,這確實是一種全新的方法。與傳統影像物件辨識相比,最大的差異在於車輛數量準則仍需人工設定,且不同監視器的視角與位置變化需要針對各自環境手動調整判定標準,而 VLM 則將這些工作交由 AI 進行理解與處理,大幅減少了人工設定的需求。
案例二:員工工作狀況
目標:使用VLM辨識員工是否於工作狀態,杜絕薪水小偷。
提示語:辨識人體行為狀態,回覆狀態結果,例如”The worker in the image is reading. ”、”The worker is holding a cell phone.”、”The worker is typing on a keybord.”。
測試結果:辨識表現相當好,我們使用Webcam拍攝人體各種行為動作,模型會依據我們的提示語給予回覆。
圖A 是由Webcam拍攝的人體行為,若在鏡頭下使用手機,系統判斷行為後可即時給予The worker is holding a cell phone.的提示:

圖B 結果顯示,若在鏡頭下使用鍵盤打字工作,系統判斷行為後可即時給予The worker is typing on a keybord.的提示:

圖C 結果顯示,若在鏡頭下看書閱讀,系統判斷行為後可即時給予The worker in the image is reading.的提示:

圖D 顯示若在鏡頭下趴著睡覺,系統判斷行為後可即時給予The worker in the image is sleeping.的提示:

結論:本次測試讓筆者對於以往的人體辨識方式有了全新的體驗。過去的做法通常需要先設定人體關節點,再依據動作進行分析,而這次使用 VLM,則是直接透過影像理解來判斷員工是否處於工作狀態,無需額外標記特定人體特徵。這種方式大幅簡化了流程,並展現出 VLM 在影像語意理解上的強大能力,讓我們對未來應用充滿期待。
案例三:工地安全
目標:使用VLM辨識工地作業畫面,並給予相關的工地安全說明或缺失。
提示語:辨識作業環境影像,回覆狀態結果,例如”The construction area is not well. ”、”The construction area is not clear.”
由於本案要判斷的場景內容比較多,沒辦法完整放到影像上,因此就直接把VLM描述的內容也截圖給讀者。
圖片A:辨識結果給予The construction area is not well.提示語
結果說明:
- 工地沒有適當的光線,可能會有看不到的危機
- 該區域似乎是建築工地,有金屬鷹架
- 該區域有2個工人
- 工人都有戴安全帽

圖片B:辨識結果給予The construction area is not clear.提示語
結果說明:
- 施工區域維護不善,有明顯雜物
- 工人沒有穿戴任何防護裝備,例如上衣
- 工人正在使用金屬桿作為臨時梯子

結論:本次測試顯示,VLM 在工地安全監測上的應用具有潛力,能夠直接透過影像場景理解,辨識施工區域的環境狀況與工人安全行為。測試結果準確識別了工地雜亂、缺乏維護,以及工人未穿戴防護裝備、使用不當工具作為臨時梯子的情況。
與傳統基於物件標記的方法相比,VLM 能夠提供更直覺且快速的安全性評估,減少了對特定標籤的依賴,展現了影像理解技術在安全監測領域的實用性與發展潛力。
總結
本次測試驗證了 VLM在 Jetson Nano Super上的運作潛力,並展現其在影像語意理解方面的強大能力。無論是人體辨識、交通流量分析,還是工地安全監測,VLM都能直接透過影像場景理解進行判斷,而無需依賴傳統的數據標記或特徵提取方式。Jetson Nano Super作為低功耗 AI 邊緣運算裝置,在這些應用場景下表現穩定,能夠有效處理即時影像分析需求,提升系統的靈活性與效率。由此可見,VLM 在Jetson Nano Super上的應用,未來可廣泛用於智慧監控、行為分析與安全管理,值得進一步優化與開發。

學歷:中山大學資訊管理研究所 博士
- 舊瓶裝新酒還是新瓶裝舊酒?Jetson Orin Super效能實測 - 2025/03/12
- 低成本空氣品質感測器 – 夏普 GP2Y10開箱實驗 - 2023/03/16
- 【ESP32專欄】ESP32 MQTT與深度睡眠 - 2022/06/20
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


