隨著電腦視覺技術的快速發展,物件辨識已成為影像處理與人工智慧(AI)應用的重要領域。其中,ViT(Vision Transformer)與YOLO(You Only Look Once)是兩種具有代表性的物件辨識技術,各自採用了不同的架構與運算原理,並在不同場景中展現獨特的優勢。
ViT(Vision Transformer)
ViT 是一種基於 Transformer 架構的影像辨識技術,最早由 Google 在 2020 年提出。傳統的卷積神經網路(CNN)透過局部感受野來擷取影像特徵,而 ViT 則利用 Transformer 的 自注意力機制(Self-Attention) 來分析影像的整體結構與關聯性。其技術架構與運作方式:
(Source)
1.影像切割(Patch Embedding)
ViT 會先將輸入影像分割成固定大小的區塊(Patch),例如 16×16 像素的小方塊。每個 Patch 被視為一個獨立的「詞彙」,類似於 NLP(自然語言處理)中的單詞。
2.特徵編碼(Linear Projection)
每個 Patch 會經過線性轉換(Linear Projection),將像素數據轉換為固定長度的向量,並加入位置編碼(Positional Encoding),以保留影像的空間資訊。
3.Transformer 編碼器(Self-Attention)
ViT 透過 多頭自注意力機制(Multi-Head Self-Attention, MHSA) 來計算每個 Patch 之間的關聯性。這種機制允許 ViT 在辨識物件時考慮整個影像的全局資訊,而不只是局部區域。
4.分類(MLP Head)
影像特徵經過數層 Transformer 編碼後,最終輸入至全連接層(MLP)進行分類或物件偵測。
ViT 的特點與應用:
- 高準確度:由於自注意力機制能夠捕捉全局特徵,ViT 在複雜場景(如醫學影像、衛星影像分析)表現優異。
- 計算需求高:Transformer 架構的計算量較大,需大量數據與高效能 GPU 進行訓練,因此較難部署於即時應用或低端設備。
YOLO(You Only Look Once)
YOLO 是一種高效能的 單階段物件偵測模型,最早由 Joseph Redmon 於 2016 年提出。與傳統 CNN 物件偵測方法(如 Faster R-CNN)不同,YOLO 採用單次前向傳播(Single Forward Pass)即能完成物件偵測,因此具有高速與即時性的優勢。其技術架構與運作方式:
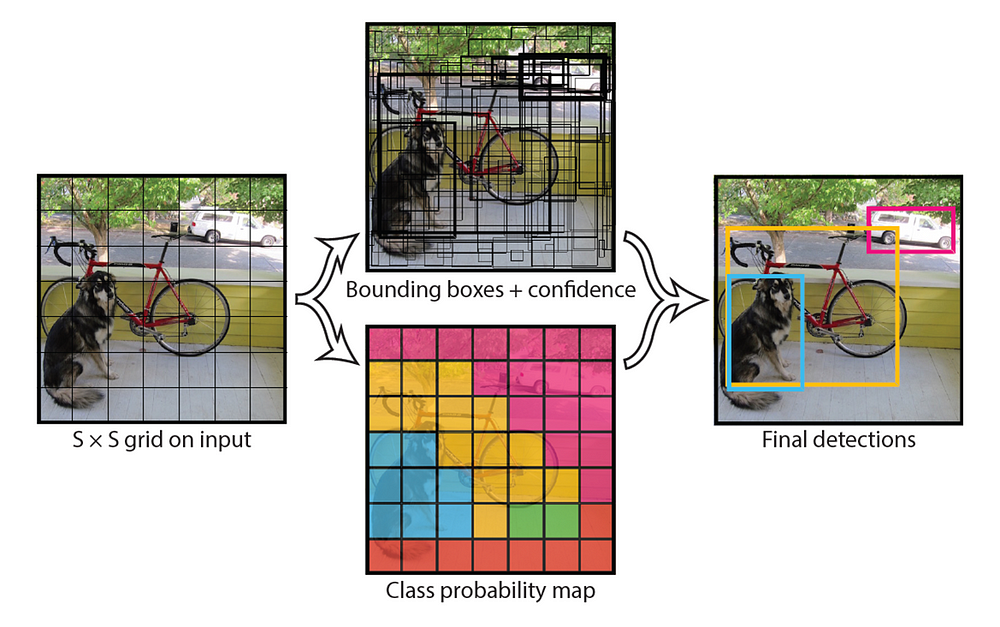
(Source)
1.輸入影像處理
YOLO 會將輸入影像劃分為固定大小的網格(Grid),例如 7×7 或 13×13,每個網格負責預測是否有物件存在。
2.特徵提取(Backbone CNN)
YOLO 使用 CNN 作為骨幹網路(如 Darknet、YOLOv5 的 CSPDarknet),用來提取影像的深度特徵。
3.Bounding Box 預測
每個網格會產生多個候選邊界框(Bounding Box),並預測其物件分類與置信度(Confidence Score)。例如,YOLO 會預測物件的中心座標(x, y)、寬高(w, h)、物件類別與置信分數。
4.非極大值抑制(NMS, Non-Maximum Suppression)
為了避免重疊預測框,YOLO 會使用 NMS 篩選出最準確的物件邊界框,提升偵測效率。
YOLO 的特點與應用:
- 高速運算:YOLO 只需一次前向傳播即可完成物件偵測,適合即時應用,如監控、無人機識別、自動駕駛等。
- 對小物件不夠敏感:由於 YOLO 主要透過網格來預測物件,對於小型物件或擁擠場景的辨識能力較弱。
- 適合邊緣運算:YOLO 可部署在嵌入式裝置(如樹莓派、Jetson Nano),適合 IoT 物聯網應用。
ViT vs YOLO
1. 架構與原理
| 技術 | ViT (Vision Transformer) | YOLO (You Only Look Once) |
|---|---|---|
| 核心概念 | 以 Transformer 架構取代 CNN 進行影像辨識 | 單階段物件偵測模型,直接回歸邊界框與分類 |
| 主要運算方式 | 將影像切割成 Patch(區塊),用 Transformer 編碼特徵 | 透過 CNN 區域預測物件類別與位置 |
| 網路架構 | Transformer-based,無卷積層 | 深度 CNN-based,包含 backbone、neck 和 head |
2. 精準度與速度
| 指標 | ViT | YOLO |
|---|---|---|
| 辨識精準度 | 高(特別適合複雜場景) | 精準度略低於 ViT,特別在小物件或擁擠場景 |
| 推論速度 | 較慢(計算成本高) | 非常快,適用即時應用 |
| 對小物件辨識 | 表現較差(需要較大數據集訓練) | 表現較佳,適合小物件偵測 |
3. 訓練與運算成本
| 指標 | ViT | YOLO |
|---|---|---|
| 訓練數據需求 | 需要大量數據(如 ImageNet-21k) | 可在中等數據集上訓練(如 COCO) |
| 計算資源 | 高,需要 GPU/TPU 進行自注意力計算 | 低,適合邊緣設備 |
| 模型大小 | 大(需要大量記憶體) | 較小(可部署在 IoT 設備) |
4. 適用場景
| 需求 | ViT | YOLO |
|---|---|---|
| 複雜影像分類(如醫學影像) | ✅ 適合 | ❌ 不適合 |
| 即時物件偵測(如監控、車牌辨識) | ❌ 不適合 | ✅ 最佳選擇 |
| 邊緣設備(IoT、手機) | ❌ 運算量太大 | ✅ 高效能,適合嵌入式應用 |
| 場景理解(如自動駕駛、影像摘要) | ✅ 優勢明顯 | ❌ 不擅長 |
何時選擇 ViT 或 YOLO?
- 如果你的應用需要高精準度,且運算資源充足(如醫學影像分析、衛星影像辨識),那麼 ViT 是更好的選擇,因為它能捕捉影像的全局關係,提高辨識準確度。
- 如果你的應用需要即時性與高效能(如智慧監控、無人機導航、自動駕駛),那麼 YOLO 更適合,因為它可以在低資源環境下快速執行物件偵測。
簡單的說,如果你的應用需要高準確度且不考慮速度,可選 ViT;如果你需要即時且輕量級的偵測系統,則選 YOLO。不過,隨著 AI 技術的發展,ViT 和 YOLO 並不是競爭關係,而是各自適用於不同場景的最佳解法。未來可能會有更多融合 Transformer 和 CNN 優勢的模型,進一步提升物件偵測技術的精準度與運算效率。
(責任編輯:歐敏銓)

- 【Podcast】AI 機器人安全革命:從功能安全到軟體定義安全 - 2026/04/10
- RISC-V技術成熟度與全球AI落地應用現況剖析 - 2026/04/10
- 宇樹、智元出貨囊括八成 預估2026年中國人形機器人產量年增94% - 2026/04/09
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!

