作者:陸向陽
今年春節期間DeepSeek讓大語言模型再掀熱潮,過去認為大語言模型的每次升級都需要高昂費用、龐大運算力、漫長訓練時間才能實現,DeepSeek卻給出截然不同的答案,以低費用、少量運算力、短暫時間就訓練出與今日主流大語言模型相仿的表現,讓各界吃驚。
不過有關DeepSeek的各種說法,有時候有些混淆,筆者藉此文想聊一下,或許可以幫一些人釐清,或讓平時對AI有興趣的人有更深刻的瞭解。
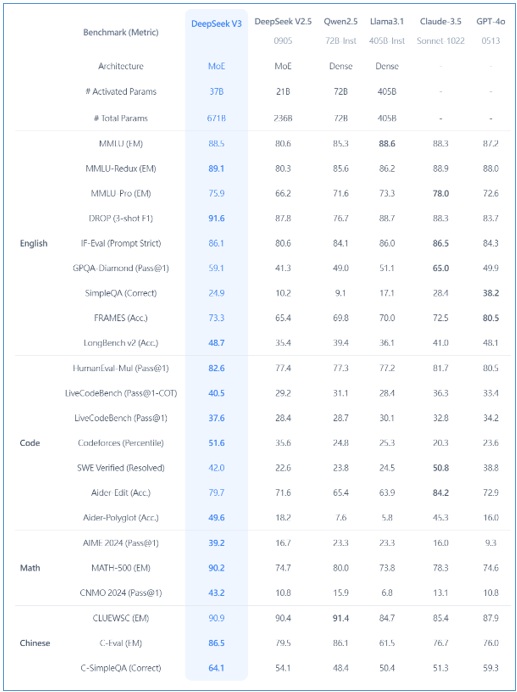
圖1:DeepSeek-V3與其他知名模型的測試比較,如數學、程式碼、中英文等,粗體字為DeepSeek-V3勝出的項目(圖片來源:DeepSeek官網)
DeepSeek-R1訓練費用不到560萬美元?
DeepSeek自己釋出的53頁技術報告是寫DeepSeek-V3的訓練費用是557萬美元,這是租用運算力來訓練的費用,每顆H800晶片每小時運算需要2美元,因為不是買斷晶片或設備所以便宜,且沒有算開發過程的試錯成本、人員薪資、資料集(或稱數據集)的清理心力等,不過此前其他模型的訓練成本宣稱,其實也是一樣只講究訓練運算力這段,其他部份不好估算,所以齊頭比較依然是DeepSeek大幅便宜。
其次,許多人以為DeepSeek-R1也就是這個訓練費用,其實從V3訓練出R1還是需要額外的訓練調整費用,這塊沒有揭露,如同OpenAI訓練出GPT-4o後再訓練出OpenAI o1也是有額外增加費用的。
不過也有人質疑不可能只用2,048顆H800就訓練出模型,新創公司Scale AI執行長認為用上5萬顆H100(H100比H800強悍,H800是專供中國大陸市場的特有型號,是H100的降規款晶片)。
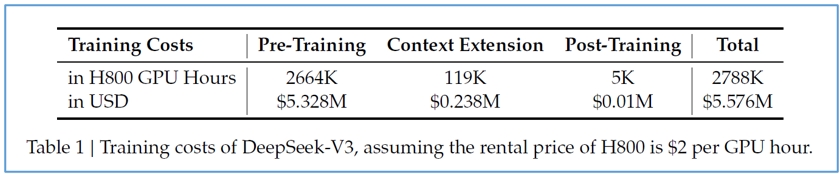
圖2:DeepSeek釋出的技術報告說明DeepSeek-V3模型的訓練成本(圖片來源:DeepSeek官網)
美國也對新加坡資料中心進行調查,認為可能動用新加坡資料中心的運算力協助其訓練,因為新加坡為亞太區的資料中心重鎮,NVIDIA的營收越來越高比重來自新加坡,已達22%,以至於拜登卸任前五天試圖頒布的AI禁令中,把新加坡列為中度封鎖的國區,避免完全封鎖的國區(22國,如阿富汗、伊朗、中國大陸等)租賃新加坡的運算力,然而川普上任後取消該禁令,推測與NVIDIA嚴重抗議有關,該禁令嚴重傷害NVIDIA的後續銷售。
DeepSeek用蒸餾技術實現?
模型的訓練或模型的輕量化可運用蒸餾技術,DeepSeek曾傳聞是以OpenAI線上服務的模型進行蒸餾而成,傳聞說有大量的API呼叫,不過OpenAI沒有提出證據,之後也放棄控告。(過去OpenAI的使用條款就有言明不許對其進行蒸餾)
再者,全然透過蒸餾實現的模型,是不可能超越學習仿效的模型的,但DeepSeek在各種標竿(benchmark)測試上時有勝出(不是全面勝出,有勝出的部份也多為略勝),故不可能全然倚賴蒸餾,推測還有運用其他手法使其表現勝出。而既然不是大幅勝出,估計也沒有變革性的技術在其中,DeepSeek的重點依然是在訓練成本低廉,模型表現只能說是不相伯仲。
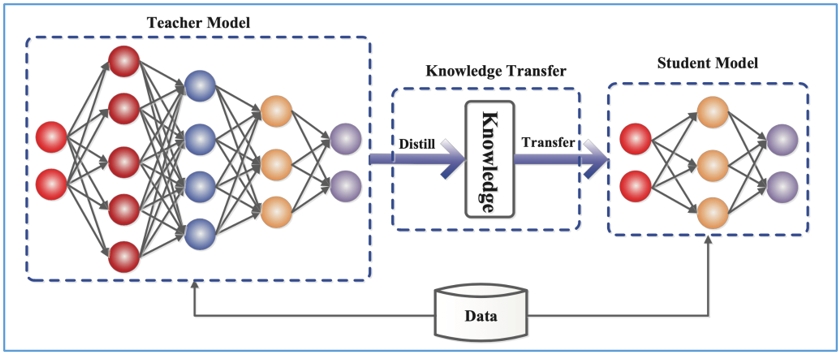
圖3:人工智慧蒸餾(也稱知識蒸餾)示意圖,透過較大的老師模型(左)表現讓較小的學生模型(右)學習,以較小的模型得到與老師相似的智慧表現,但模型得以輕量化(圖片來源:Jianping Gou, Baosheng Yu, Stephen John Maybank, Dacheng Tao )
DeepSeek開放?
DeepSeek只有開放模型權重(weight),但沒有開放所有訓練程式碼,其他如資料集、訓練日誌、查核點、評估用程式碼、評估框架等也沒有開放,雖然純開放模型權重已經可以再行修改或衍生發展,然依然無法瞭解整體開發精髓。不過目前多數宣稱開源的模型也多是如此,少數模型是真的作到完全的開放,例如OLMo,或OpenELM等。
事實上Linux基金會在去年三月有發布一份模型開放框架(The Model Openness Framework),期望讓機器學習模型的開放性有完整的分級、分類制,避免有洗白式開放(openwashing)。

圖4:模型開放程度涉及17種軟體元件,DeepSeek主要開放模型權重與參數(圖片來源:Linux基金會 )
有小參數量的DeepSeek模型
其實完整的DeepSeek模型為671b個參數,有些人已經開始在Ollama下載1.5b至70b參數不等的模型,但這些已經不能算是完整的DeepSeek-R1模型,而是以DeepSeek-R1完整模型為蒸餾的老師模型,然後用Llama(Meta訓練出的開放模型)或Qwen2(第二代通義千問,阿里巴巴訓練出的模型)為學生模型,而後蒸餾出的小型版、輕量版模型。
Ollama上沒有明確標出這是再蒸餾的模型,所以容易被人誤會,有些地方則會在名稱上標註Distil字眼,或至少也帶有Llama或Qwen字眼,就比較不會被人誤會。
另外,倘若DeepSeek真是蒸餾他人模型而得的產物,DeepSeek可以再給其他模型進行蒸餾嗎?答案是可以的,這稱之為多層次蒸餾,技術上可行,效果則再評估。
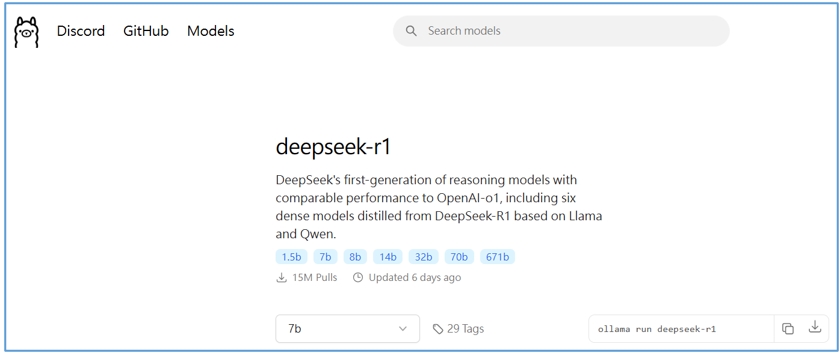
圖5:Ollama官網提供7種參數版本的DeepSeek-R1,僅有671b為正宗完整版,其餘都是蒸餾出來的版本(圖片來源:Ollama官網)
其他值得討論點
有關DeepSeek的討論相當多,例如其採用MoE(Mixture of Experts)架構,推論時只會動用部份參數而不是所有參數,如此功耗較低(相對於Dense架構),或者模型規模較容易擴展等,但也有訓練推論逐漸不均衡、佈建與調整不容易等缺點。
或者,有人用單純的幾個問句來論斷DeepSeek模型是贏是輸,這可能過於片段,畢竟各種標竿測試都是透過大量(上萬筆)的問句來考驗模型,比較公允客觀。當然!打從有標竿測試以來就一定會有人想對測試最佳化,只能持續改版標竿測試項來維持公允客觀。

- 小孩才選擇!Arduino VENTUNO Q全都要 - 2026/03/26
- 樹莓派也能「養龍蝦」! - 2026/03/24
- Windows PC上安裝PicoClaw最基礎實務 - 2026/03/03
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


