作者:陸向陽
NVIDIA本來就有推行TensorRT軟體,該軟體可以把訓練好的AI模型進行調整,讓模型在推論時更有效率。之後NVIDIA也推出TensorRT-LLM,顧名思義是針對大型語言模型(LLM)而推,TensorRT-LLM可以讓訓練好的大語言模型在推論時獲得更好的效率。
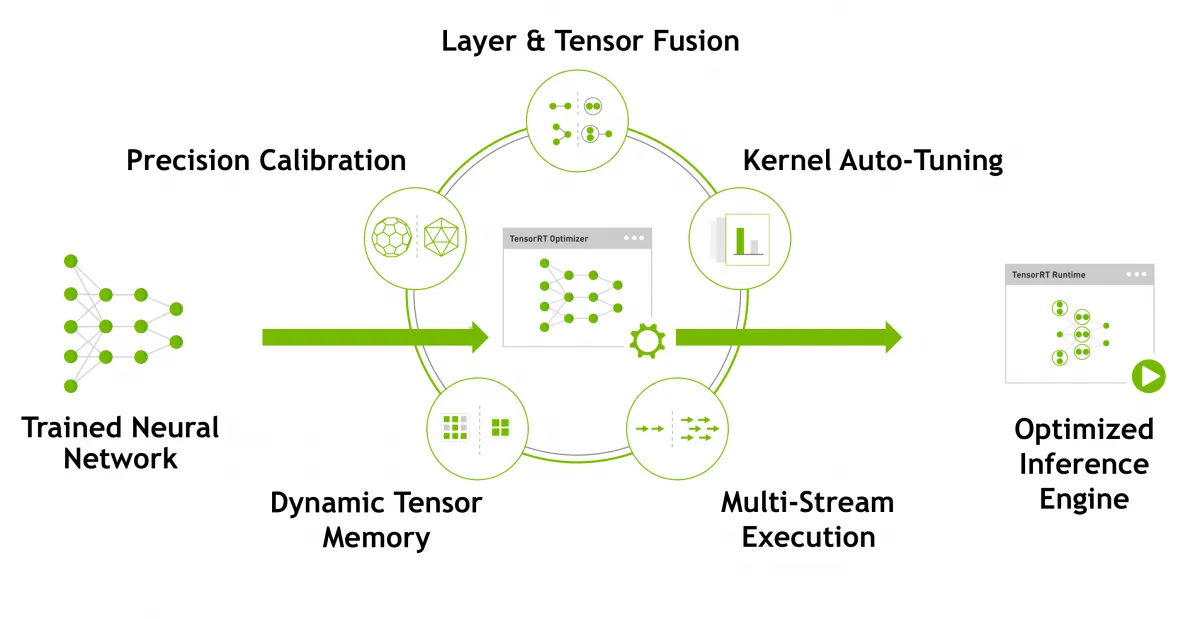
圖1 TensorRT對已訓練完的AI模型進行推論最佳化的手法(圖片來源:NVIDIA)
推測性解碼提升三倍效率
最近(2024年12月)NVIDIA新發佈,在TensorRT-LLM中加入了推測性解碼(Speculative Decoding,或稱Speculative Sampling推測性取樣)技術,從而讓TensorRT-LLM的推論效率提升三倍。
推測性解碼的原理是增加些許的運算量,來推測性地產生幾個詞元(Token),然後運用模型內就具備的驗證步驟來確保輸出的品質,從而提升整體推論效率。
所謂的增速三倍,是以開放原始程式碼的大語言模型Llama 3.1為基準進行測試,參數量4,010億個,運用TensorRT-LLM的預測性解碼技術後產生三個版本,三個版本的推論速度均是原有模型的三倍以上,其中最佳的一個版本更是達到3.6倍。
圖2 運用預測性解碼後大語言模型Llama推論的效率提升三倍以上(圖片來源:NVIDIA)
若更進一步解釋箇中原理,其實預測性解碼會額外生出一個小型、草稿版的模型(Small Draft Model),原有模型稱為目標模型(Target Model),所謂的增加些許運算就是先進行小草稿模型的推論,推論出的結果再給目標模型,供目標模型進一步運作,以此獲得加速。
圖3 預設性解碼運用小型草稿模型給目標模型指示,從而達到整體加速效果(圖片來源:NVIDIA)
至此可能有個疑問:額外生出的小草稿模型,其參數量越大越有加速效果嗎?目前看來未必,以NVIDIA公佈的測試結果來看,額外生成30億個參數的小草稿模型有最高的加速效果,即3.6倍。
相對的,10億個參數反而只有3.3倍左右,至於80億個參數更是僅比3倍略多,由此可知小草稿參數過猶不及都不能達到最理想的加速效果。
其他技術細節也包含,小草稿模型推論上必須夠快速且維持高接受度(acceptance rate),推測性取樣就能在每次迭代中運用統計產生多個Token,以此來指示目標模型運作,從而縮短讓端到端之間的需求延遲。
小結
最後,NVIDIA提升TensorRT-LLM軟體能力的動機也很明顯,就是讓NVIDIA的GPU在AI加速表現上保持領先,以此讓對手更難追趕,NVIDIA之所以能在AI加速晶片領域上居於領先地位,CUDA軟體生態為其中關鍵,因此NVIDIA不僅在晶片電路設計上持續努力,也會持續構築對其晶片有利的軟體,預測性解碼即是如此。特別是具備預測性解碼的TensorRT-LLM目前只支援一顆NVIDIA GPU或是一台電腦中的多顆NVIDIA GPU,也形同間接呼應此一動機。
(責任編輯:謝嘉洵。)

- 「公升級」Agentic AI方案比較:Apple、NVIDIA、AMD - 2026/06/29
- 受保護的內容: 輕鬆實現創意:M5Stack AI Chatbot、Cardputer Adv開箱體驗 - 2026/06/26
- 創客開發板AI加速晶片觀察 - 2026/06/26
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!