多模態技術(Multimodal Technology)指的是整合多種數據模態,如文本、圖像、音訊和視訊,以提升AI系統的理解和生成能力。隨著深度學習和大規模預訓練模型的進步,多模態技術在近年來取得了顯著發展,並在各個領域展現出廣泛的應用前景。本文將針對多模態技術中與訊訊生成與分析相關的技術現況、實現與挑戰進行探討。
多模態視訊重要模型簡介
以下介紹由Google及Meta主導開發及發布的4款多模態視訊模型:
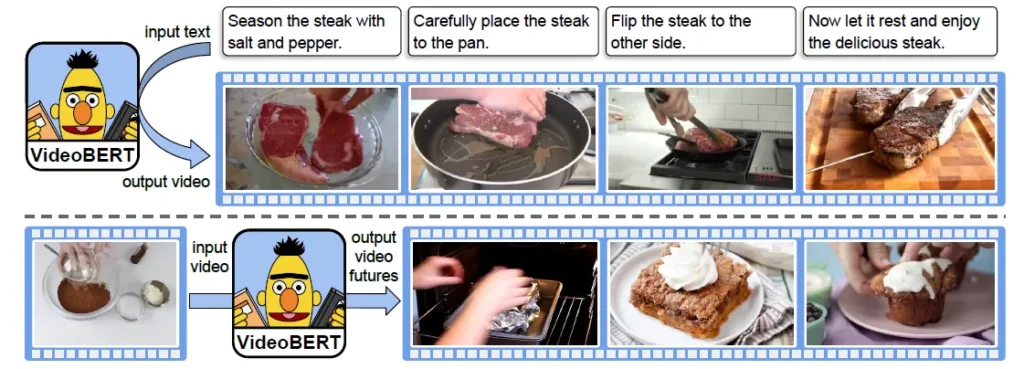
1. VideoBERT
VidoBERT是 Google Research在2019年發布的模型,它是一種基於Transformer的多模態模型,通過將視訊分解為視覺和文本模態,學習兩者之間的語義關聯,適合的應用場景為短視訊內容分析、視訊推薦、場景理解等。
VidoBERT主要功能包括:
- 視覺-文本對齊:提取視訊中對應的場景和語音信息,進行語義對齊。
- 動作識別與視訊理解:適用於視訊中的行為分類和事件檢測。
(Source)
2. MViT
MViT(Multiscale Vision Transformers)的發布者是 Facebook AI Research,它是一種基於Vision Transformer(ViT)進行改良的架構(目前版本為MViTv2),採用針對視訊設計的多尺度視覺變換器,能夠處理視訊的時間和空間信息,提升對動態場景的理解能力。
MViT以簡單的方式擴展ViT的架構,整個網路不再固定分辨率,而是建構從高分辨率到低分辨率的多個階段的特徵層次結構。適合的應用場景為運動分析、監控系統中的動作檢測等。
它的主要功能包括:
- 時間-空間特徵學習:捕捉視訊中動態場景的複雜時間變化。
- 動作識別:在視頻中準確定位並分類不同的動作
3. TimeSFormer
TimeSFormer(Time-Space transformer)的發布者是 Meta AI Research,它是一種基於Transformer的視訊理解架構,它在多個行為辨識資料集上達到SOTA(State-of-the-Art )結果,同時訓練和推理速度優於3D CNN。在此論文提出了時空注意力的五種不同形式,最終採用的divided space-time attention降低了運算複雜度並保持了高效能。該模型可擴展到更長的視訊片段,並在不同資料集上進行了驗證,證明了其在視訊理解任務中的優勢。
它適合的應用場景有體育比賽分析、教育視訊內容生成等。主要功能包括:
- 高效視訊分類:對視訊的內容進行分類與標籤化處理。
- 行為識別與事件檢測:提取視訊中的複雜行為和事件信息。
4. Vid2Seq
Vid2Seq(Video-to-Sequence)的發布者是 Google AI,透過將視訊轉換為結構化的文本序列,它能實現對視訊內容的摘要和描述生成,適合的場景有視訊檢索與推薦、自動字幕生成、多模態問答系統等。

(Source)
主要功能:
- 視訊摘要生成:從視訊中提取主要內容,生成自然語言描述。
- 視覺問答:基於視訊內容回答用戶問題,適用於多模態的互動式應用。
實際案例開發流程
將上述多模態視訊模型應用於自己的應用中需要以下步驟,包括應用需求定義、模型選擇、技術環境設置、訓練與調試、以及應用部署。以下將以一個實用案例示範 – 智慧視訊摘要生成系統,展示如何將 Vid2Seq 模型應用於視訊摘要生成,並實現從設計到部署的完整流程。
這個智慧視訊摘要生成系統的應用場景設定是要自動為教育視訊生成文字摘要,幫助學生快速理解視訊內容。其實現流程如下:
1. 功能需求分析
- 輸入:教育視訊(如講座視頻,時長 5-10 分鐘)
- 輸出:一段自然語言的視訊摘要
- 額外需求:
- 多語言支持(例如中文與英文)
- 高效處理(每段視訊生成摘要的時間不超過 1 分鐘)
2. 技術選擇
- 模型:Vid2Seq,專為視訊轉自然語言文本設計
- 框架:使用 PyTorch 和 Hugging Face 提供的預訓練模型
- 開發工具:
- OpenCV:用於視訊分帧和處理
- FFmpeg:視訊格式轉換
- 部署環境:
- 本地測試:NVIDIA RTX 3090
- 雲端部署:AWS EC2 或 GCP
3. 數據準備
- 數據來源:使用開源數據集 MSR-VTT(專為視訊描述生成設計)
- 數據預處理:
- 使用 FFmpeg 將視訊切分為短片段(每 5 秒一段)
- 提取關鍵幀:從每段視頻中抽取 1-2 個關鍵帧
- 轉換為模型輸入格式(如特徵向量或像素矩陣)
4. 訓練與微調
- 微調方法:
- 使用 MSR-VTT 的標註數據微調 Vid2Seq,確保模型對教育類視訊的摘要生成更加精準。
- 超參數設置:
- 批量大小:16
- 學習率:5e-5
- 訓練輪次:10
- 工具:
- 使用 Hugging Face 的 Trainer 模組簡化微調流程
5. 系統設計與實現
》前端模組
- 使用 React 或 Vue.js 開發簡單的視訊上傳介面
- 支援視訊文件拖放上傳和語言選擇(中文或英文)
》後端模組
- 開發基於 FastAPI 的 RESTful API,實現以下動作:
- /upload: 上傳視訊
- /process: 調用模型生成摘要
- /result: 返回摘要結果
- 整合視訊處理流程:
- 接收視訊並分帧(OpenCV)
- 調用 Vid2Seq 模型生成描述
》推理流程
- 使用分帧工具處理視訊,提取影像特徵。
- 將影像特徵輸入 Vid2Seq 模型。
- 模型生成自然語言摘要。
- 返回摘要結果至前端。
6. 部署與優化
》部署
- 模型優化:
- 使用 ONNX 將 PyTorch 模型轉換為高效推理格式。
- 利用 TensorRT 提高推理速度。
- 雲端部署:
- 使用 AWS Lambda 進行推理 API 部署。
- 使用 S3 儲存用戶上傳的視訊。
》性能測試
- 測試模型的推理速度和準確率,確保視訊處理時間在 1 分鐘內。
》優化方向
- 使用視訊壓縮技術減少帶寬消耗。
- 優化分帧算法以減少冗餘幀的處理時間。
7. 預期效果與拓展
- 主要效果:
- 用戶上傳視訊後可立即獲取精簡摘要,提升觀看效率。
- 潛在拓展:
- 添加多模態問答功能,讓用戶能根據視訊提問(結合 VideoBERT)。
小結:發展挑戰
基於多模態視訊模型或框架技術,仍需克服不少挑戰,例如高質量的視訊數據集需要巨大的存儲和計算資源,且手動標註視訊(例如動作類別、場景信息)需要大量人力。此外,視訊處理涉及時間和空間的維度,尤其是高解析度視訊會大幅增加計算資源需求。
一支視訊往往包含多種模態,這些模態可能來自不同設備,對齊和整合有其困難,如何將視訊中的視覺模態(圖像)、語音模態(音頻)和語言模態(字幕或旁白)進行高效融合,實現上仍有不小的挑戰。
視訊的應用往往具有即時性(如監控分析、直播翻譯),這會要求系統能在極短時間內處理和分析視訊。另一個應用特性則是長時間的視訊處理系統需要處理海量數據,這對儲存和運算資源提出極高要求。除了技術挑戰外,視訊中的個人信息(如面部、語音)也涉及數據隱私問題,可能違反相關法規。
這些技術或法規上的挑戰,其實也意味著龐大的「商機」,誰能克服即建立了自己與對手的差異化門檻,有機會在市場上脫穎而出。
(責任編輯:歐敏銓)

- NVIDIA與全球機器人生態系推動具生產規模的實體AI - 2026/03/27
- 從VLA到落地部署:拆解新世代機器人開發關鍵路徑 - 2026/03/24
- 【Podcast】分散式代理時代:2026 Edge AI 技術全解析 - 2026/03/24
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!

