 TinyLlama 是一個開源的小型語言模型(Small Language Models, SLM),擁有約 11 億個參數,旨在在 3 萬億(trillion)個標記(tokens)上進行預訓練。 該模型採用了與 Llama 2 相同的架構和分詞器,這使得 TinyLlama 能夠在許多基於 Llama 的開源項目中即插即用。 此外,TinyLlama 的體積小巧,適用於需要限制運算力和記憶體容量的多種應用。
TinyLlama 是一個開源的小型語言模型(Small Language Models, SLM),擁有約 11 億個參數,旨在在 3 萬億(trillion)個標記(tokens)上進行預訓練。 該模型採用了與 Llama 2 相同的架構和分詞器,這使得 TinyLlama 能夠在許多基於 Llama 的開源項目中即插即用。 此外,TinyLlama 的體積小巧,適用於需要限制運算力和記憶體容量的多種應用。
在訓練過程中,TinyLlama 利用了開源社群的多項先進技術,如 FlashAttention 和 Lit-GPT,以提高運算效率。該項目於 2023 年 9 月 1 日開始訓練, 目前,TinyLlama 的模型檢查點和代碼已在 GitHub 上公開,供研究人員和開發者使用。儘管其規模較小,TinyLlama 在一系列任務中展示了卓越的性能,顯著超越了現有的同等規模的開源語言模型。
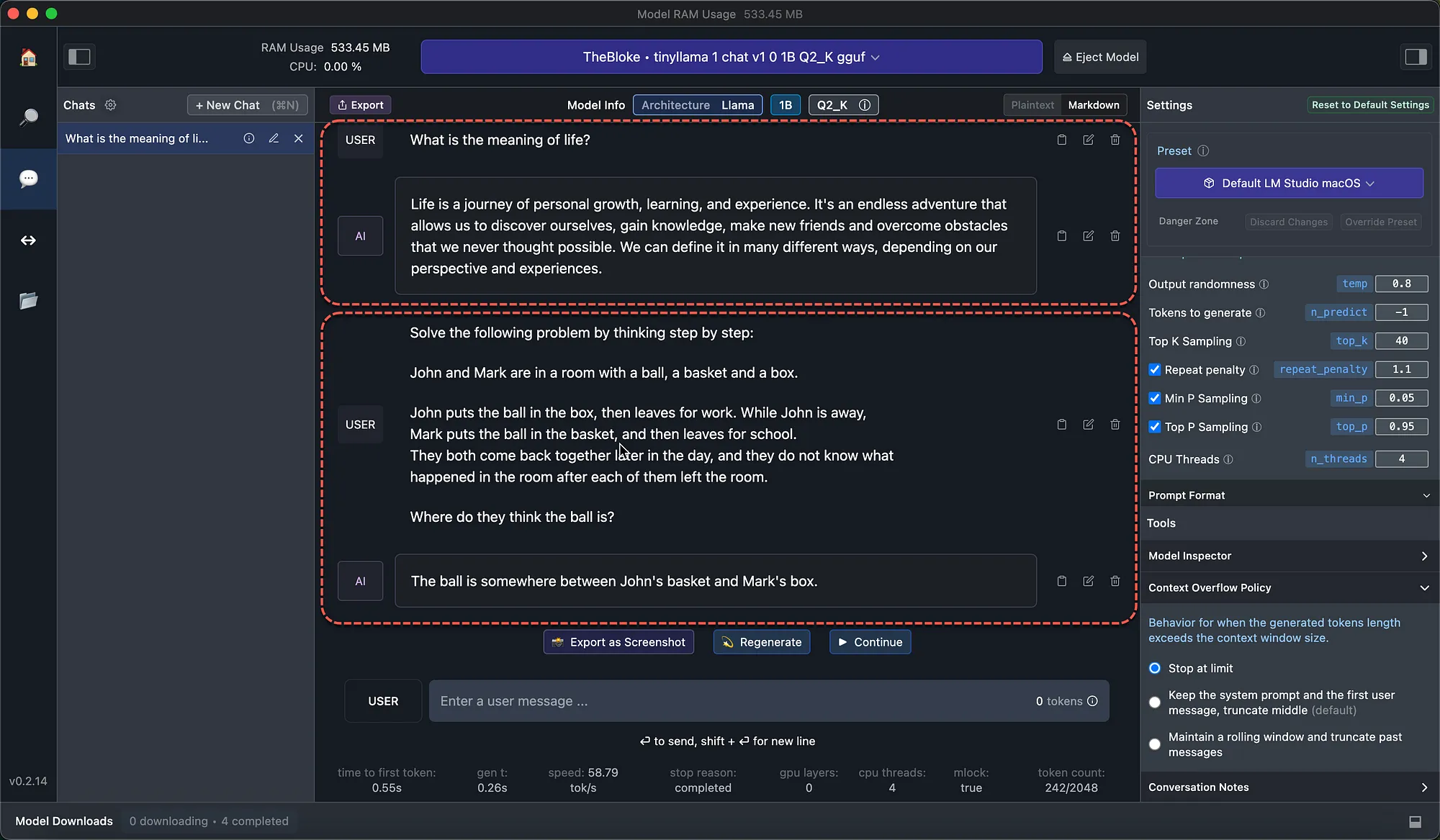
(Source)
為Edge AI而生
TinyLlama 2 是一個小型語言模型,其設計目標與 Edge AI 的核心需求非常契合。以下是 TinyLlama 2 在 Edge AI 應用中的優勢與關係:
1. 資源效率高,適合邊緣計算
- 低運算需求: TinyLlama 2 的參數量(約 11 億)相比大型語言模型(LLM)顯著減少,但仍保持良好的性能。這使其能在低功耗設備(如物聯網設備、移動設備)上高效運行。
- 記憶體容量小: 模型的壓縮技術和小型化設計使其能夠在容量有限的邊緣設備上運行,而不依賴於雲端伺服器。
2. 支持即時處理,提升用戶體驗
- 低延遲: TinyLlama 2 的高效推理能力可滿足邊緣計算中的即時處理需求,例如語音助手、翻譯應用和即時建議系統。
- 離線運行: 在缺乏穩定網路連接的場景,TinyLlama 2 能在本地設備上運行,提供可靠的服務。
3. 隱私與安全的保障
- 數據本地處理: TinyLlama 2 在邊緣設備上運行時,可以實現數據的本地處理,避免將敏感數據上傳到雲端,從而提高用戶隱私。
- 減少數據傳輸風險: 邊緣運算環境下,數據傳輸的減少也意味著降低了遭受網路攻擊的風險。
4. 邊緣運算基礎架構的適配
- 與 Edge GPU/TPU 的兼容性: TinyLlama 2 的設計可以充分利用邊緣設備上的硬體加速(如Intel AI PC、NVIDIA Jetson Nano、Coral Edge TPU),實現更高效的運算。
- 與 Llama 2 架構兼容: TinyLlama 2 使用與 Llama 2 相同的架構和分詞器,方便開發者在開發 Edge AI 解決方案時快速適配現有技術。
適合的 Edge AI 應用場景
TinyLlama 2 作為一個小型語言模型,特別適合資源受限的嵌入式系統和邊緣運算環境。以下是幾個主要應用場景:
1. 語音助理與自然語言處理
- 應用場景: 智慧音箱、車載語音助理、語音控制設備。
- 特點: TinyLlama 2 能有效處理自然語言指令,支持多語言應用,並能在本地實現指令解析,減少延遲。
2. 智慧家居與物聯網 (IoT)
- 應用場景: 智慧燈具、恒溫器、門鎖等 IoT 設備。
- 特點: TinyLlama 2 可以支持本地語言處理和命令生成,實現用戶與設備的智能交互,增強隱私保護。
3. 即時監控與預警系統
- 應用場景: 工業現場異常檢測、設備健康監測。
- 特點: 模型可在本地處理文本描述和指令生成,為異常狀態提供即時報告或建議。
4. 車載系統與導航
- 應用場景: 車載語音導航、駕駛建議系統。
- 特點: 提供語音指令識別與生成的功能,並在車載系統內運行,確保快速反應和數據安全。
5. 移動設備與穿戴式設備
- 應用場景: 手機助手、智能手錶、健身追蹤設備。
- 特點: 模型小巧,適合內存有限的設備,支持文字生成、智能建議等功能。
6. 教育與互動學習
- 應用場景: 教育機器人、語言學習應用。
- 特點: 支持語言生成和回答學生問題,應用於教育場景,增強互動性。
基本硬體環境與資源要求
TinyLlama 2 是一款小型語言模型,但其運行仍需要一定的硬體資源支持。以下是基本的硬體需求和資源配置建議,供參考:
1. 記憶體(RAM)需求
TinyLlama 2 的模型參數約 11 億,推理時至少需要 6GB 到 8GB 的 RAM。 如果採用模型壓縮或低精度量化技術(如 8-bit 或 4-bit 量化),記憶體需求可降低至 2GB 到 4GB。
2. 運算能力
- CPU:
- 推薦至少配備一個具備多核能力的處理器(如 Intel Core i5 或以上,ARM Cortex-A 系列高性能核心)。
- 對於輕量化應用,還可以在具有 SIMD 支持的嵌入式 CPU 上進行運行,但會降低處理速度。
- GPU:
- 推理推薦至少使用支持 CUDA 或 AMD ROCm 的 GPU,例如 NVIDIA GTX 1650 或更高規格。
- 在更低成本的情況下,NVIDIA Jetson Nano、Xavier NX 等邊緣計算平台也可支持 TinyLlama 2 的運行。
- 加速硬體:
- 使用專用的 AI 加速硬體(如 Google Coral TPU、Edge TPU 或專用的 NPU)來提升運算效率並減少延遲。
3. 儲存需求
TinyLlama 2 的模型檔案通常佔用 數百 MB 到幾 GB 的儲存空間,依壓縮程度而定。建議至少有 10GB 可用空間 來存放模型和相關的運行環境。
4. 系統平台支持
- 操作系統:
- 支持 Linux、Windows 和 macOS。
- 嵌入式應用場景可使用專門為 AI 優化的系統,如 NVIDIA JetPack、Coral Mendel OS。
- 開發框架:
- TinyLlama 2 通常在 PyTorch 或 TensorFlow 框架上進行開發與運行,需安裝對應的深度學習框架。
- 也可以導出為 ONNX 格式,使用輕量化推理引擎(如 TensorRT 或 ONNX Runtime)以減少資源消耗。
5. 電源需求
TinyLlama 2進行推理任務時,在低功耗運算環境,如 NVIDIA Jetson Nano,功耗在 5-10W 範圍內即可支持。嵌入式應用時,需視硬體平台決定電源需求,例如 Coral TPU 模組的功耗約為 2W。
硬體組合參考方案
- 桌面環境:
- CPU: Intel Core i5 或 AMD Ryzen 5
- GPU: NVIDIA GTX 1660(6GB VRAM)或以上
- RAM: 8GB(推薦 16GB)
- OS: Ubuntu 20.04 / Windows 10
- 邊緣設備:
- 平台: NVIDIA Jetson Nano / Xavier NX 或 Google Coral Dev Board
- RAM: 4GB(推薦 8GB)
- 加速: Edge TPU / NPU
與TinyLlama 2類似的SLM
與 TinyLlama 2 類似的小型語言模型(Small Language Models, SLM)主要是以輕量化設計、資源友好和專注於特定應用場景為目標。以下是一些與 TinyLlama 2 性能和設計理念相似的 SLM比較表:

1. DistilGPT 系列
DistilGPT 是 GPT 模型的輕量化版本,通過知識蒸餾技術訓練,保留了原始 GPT 的核心能力,但大幅減少了模型的參數數量和運行資源需求。適用於對話系統、文字生成、自然語言理解等場景。
2. GPT-Neo Mini
GPT-Neo 是 EleutherAI 開發的開源 GPT 模型,而 GPT-Neo Mini 是其輕量化版本,針對資源受限的環境進行優化。適用於文本生成、補全和翻譯等。
3. Alpaca
Alpaca 是一個基於 LLaMA 進行微調的小型模型,專為具備交互式功能的場景設計,資源需求顯著低於原始 LLaMA。適合教育、客服聊天機器人等場景。
4. BloomZ 小型化版本
Bloom 是 BigScience 開源的一個多語言語言模型,而其小型化版本專為低資源運算場景設計。適用於多語言應用場景,如翻譯、文本摘要和語言生成。
除了上述幾款SLM外,還有不少模型可選用,例如MiniLM、DistilBERT、LLaMA Mini、Flan-T5 Small、OpenAssistant SLM等。
小結
TinyLlama 2 的設計方向與這些 SLM 的目標類似,均是為了提供高效、輕量的語言模型解決方案,特別適合於邊緣設備和嵌入式場景。用戶可以根據具體需求選擇這些模型中的一種或進一步比較它們在資源佔用和性能上的表現。
(責任編輯:歐敏銓)
》延伸閱讀:
【Edge AI專欄】 邊緣端小語言模型崛起,開發板跟上了嗎?
TinyLlama Is An Open-Source Small Language Model

- 【產業觀察】Intel在VLA機器人市場的佈局與契機 - 2026/03/27
- AI如何讓機器人更有「人」味:跨越雙手協同鴻溝! - 2026/03/17
- 2026 Edge AI MCU技術趨勢與廠商方案現況比較 - 2026/03/12
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


