作者:陸向陽
2022年11月OpenAI開放大眾使用ChatGPT,口語化的文字回應使大眾驚豔,加上Midjourney的「文生圖」技術,使2023年吹起生成式人工智慧(GenAI)風潮,而其根基技術為大型語言模型(LLM)。
與傳統分析型AI(給一個輸入,輸出為一個判定結果)相比,生成式AI的參數量相當龐大,分析型一般在1,000萬個以下,生成式動輒10億以上,參數的多寡與運算力需求成正比。
由於運算量龐大,若用運算力小的系統來執行LLM/GenAI要很久才能回應,即問一句話可能要10分鐘後才有答案,不切實際。所以LLM/GenAI通常運用雲端資料中心的龐大運算力來算,才能即時提供回應。
不過在雲端運算也有多項缺點,因此各界開始嘗試將模型縮小,在可接受的準確性犧牲下將模型減肥、輕量化,稱為小語言模型(Small Language Model, SLM)。
要說明的是,所謂SLM並沒有明確的界定,是相對LLM而言,筆者自身觀察多半會低於70億個參數,書寫上常見7B,為何普遍為7B,一是說有代表性論文使其約定成俗,另一是說7B若每個參數為整數八位元格式(INT8),則儲存參數的記憶體空間約為7GB,考慮到多數單機系統約8GB記憶體,仍保有1GB用於其他用途,故7GB以下比較務實。
附註:另有文章認為低於1,500萬個參數方能稱SLM。
大廠、新創競逐SLM
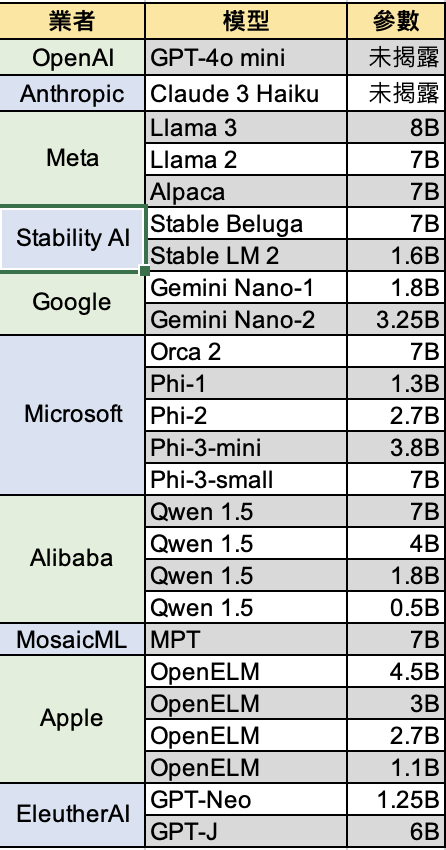
參數7B以下主要語言模型列表(製表:陸向陽)
既然是各界,表示大廠與新創均有投入,大廠如Google、Meta、Microsoft、Salesforce、Apple,新創如OpenAI、Claude(多數認為其為OpenAI勁敵,AWS、Google有投資)、Stability AI、MosaicML等,在此僅列出若干代表,難以盡數。
首先Google為了回應OpenAI,推出了Gemini模型,此模型又分成Ultra、Pro、Nano,其中Nano又分為Nano-1、Nano-2,參數量分別為18億(1.8B)、32.5億(3.25B)。
不過Gemini為專屬模型,程式碼不公開,Meta則有公開的Llama 2,其參數包含70B、30B、7B,其中7B可視為SLM,此外Llama 3也有70B與8B版,8B版也接近SLM。史丹佛大學則以Llama 7B為基礎發展出自己的Alpaca 7B,同屬SLM。
Microsoft方面則有開源Phi系列模型,Phi-1為1.3B,Phi-2(過程中還有Phi-1.5)為2.7B,之後Ph-3也同樣走類似Gemini的分級,分出Phi-3 medium、small、mini,參數分別為14B、7B、3.8B。Microsoft另有Orca系列模型,2023年年中推出Orca,同年11月推出Orca 2,並有13B、7B兩種參數。

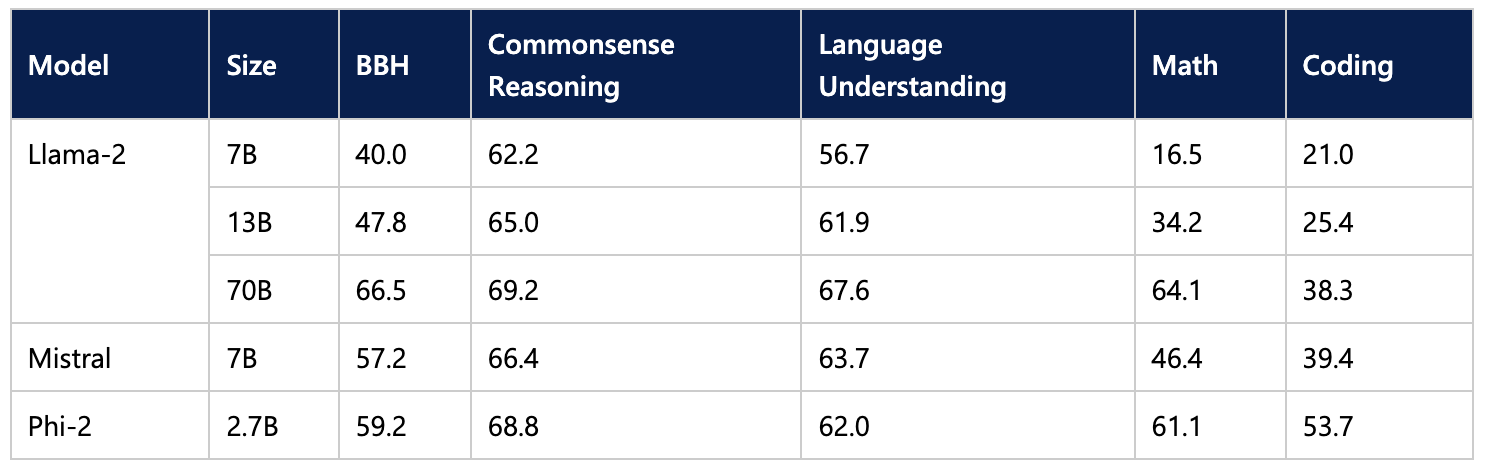
Microsoft將27億個參數的Phi-2模型與其他更大參數的開源大語言模型進行能力測試比較(圖片來源:Microsoft Blog)
至於Apple,Apple向來引領人機界面互動親和技術,這次反成大落後,即便如此仍在2024年提出OpenELM,並有4.5B/3B/2.7B/1.1B的版本,OpenELM將負責前期過濾判斷角色,簡單回覆可自行處理回應,複雜回覆則依然會回傳到雲端,請求OpenAI ChatGPT協助回答。
新創的回應
大廠紛紛推出LLM、SLM,新創也必須回應,首當其衝的OpenAI也在2024年7月推出GPT-4o mini,不過尚未揭露參數數目,只確定是更輕量的定位;另外因Stable Diffusion生圖服務而走紅的公司Stability AI也推出Stable Beluga 7B、Stable LM 2 1.6B;OpenAI的勁敵Anthropic也在2024年3月推出Claude 3 Opus、Sonnet、Haiku,其中Haiku(日語:俳句)也是SLM定位,同樣不公佈參數數目。
其他如Alibaba的Owen 1.5系列可以低到1.8B、0.5B,EleutherAI的GPT-Neo可以低到1.25億。還有Salesforce(不算小廠)提出XGen 7B,MosaicML(已被Databricks購併)提出MPT-7B,法國新創Mistral的Mistral-7B。
另外,LLM多半基於Transformer模型,而同樣基於Transformer模型的Google BERT模型開始有提出瘦身版的作法,瘦身程序被形容成蒸餾(Distillation),固有DistilBERT的發展,並有Medium、Tiny、Mini等,對應的參數只有4,100萬、1,450萬、440萬。
結語
SLM大幅減少參數(運算需求量),並盡可能維持原有LLM才有的智慧性,因此SLM也開始進行與LLM相同的測試驗證,例如數學能力、語言瞭解能力、程式碼產生能力等。
但在縮減參數的同時其實也遭遇到技術挑戰,例如表征退化、泛化能力不足等。不過各界也在克服這類問題,例如運用資料(數據)擴增技術、正規化技術等。
最後,即便參數量能順利大減,且運算力也因為ASIC、GPGPU、FPGA、CPU追加新指令集等方式而大幅提升,想要即時完成模型推論也還是有技術挑戰,例如記憶體頻寬不足,聯發科技即曾表現,7B參數放入記憶體中佔了7GB,需要的傳輸頻寬為70GB/s,然多數系統只有50GB/s。總之,AI軟硬體都有待持續精進,且讓我們拭目以待。
延伸閱讀

- 小孩才選擇!Arduino VENTUNO Q全都要 - 2026/03/26
- 樹莓派也能「養龍蝦」! - 2026/03/24
- Windows PC上安裝PicoClaw最基礎實務 - 2026/03/03
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


