作者:高煥堂
LoRA微調三步驟是:
- Step-1:觀察&測試原模型(如MT5)的input和output格式。
- Step-2:準備Training data,建立自己的Dataset類別,並拿原模型實際訓練。
- Step-3:將LoRA外掛到MT5-Small,並進行協同訓練及測試。
在本篇文章中,將以MT5-small預訓練大模型為例,並以Python源碼(Source Code)來說明之。
簡介LoRA
當今大家非常關心於LLM大模型的巨大參數量,帶來的很高的訓練成本,因而限制了諸多下游任務的應用。換句話說,由於大語言模型(LLM)的參數量巨大,許多大公司都需要訓練數月,因此許多專家們提出了各種資源消耗較小的訓練方法,而其中最常用的就是:LoRA。
由於LoRA的模型參數非常輕量,對於下游任務而言,每一個下游任務只需要獨立維護自身的LoRA參數即可。因之,可以節省*.ckpt和*.onnx的儲存空間。同時,在訓練時可以凍結原模型(如MT5)的既有參數,只需要更新較輕量的LoRA參數即可。可大幅提升模型的訓練效能。
使用LoRA時,我們並不需要對原有大模型進行訓練及調整參數,只需要訓練橙色區域中的A和B兩部分的參數即可。
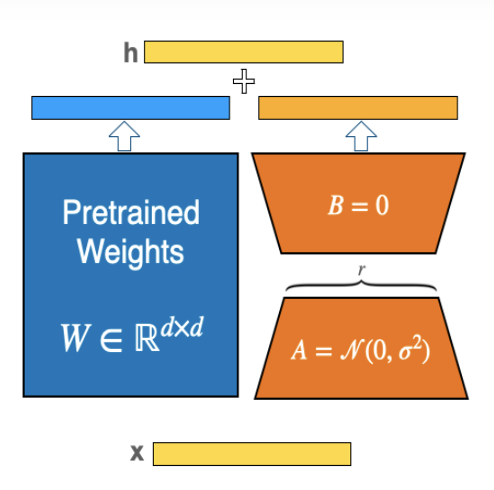
一般而言,LoRA 可以應用於神經網路中權重矩陣的任何子集,以減少可訓練參數的數量。然而,在 Transformer 模型中,為了簡單性和參數效率,LoRA 通常僅應用於注意力(Attention)區塊。
簡介MT5
每個Transformer模型都基於龐大的語料庫,進行很長時間的模型預訓練。這個預訓練階段,讓模型對任何上下文中的任何單詞都能掌握其涵義。T5的核心主張是:將所有 NLP 任務都轉化成 Text-to-Text (文本到文本)任務。如下圖:
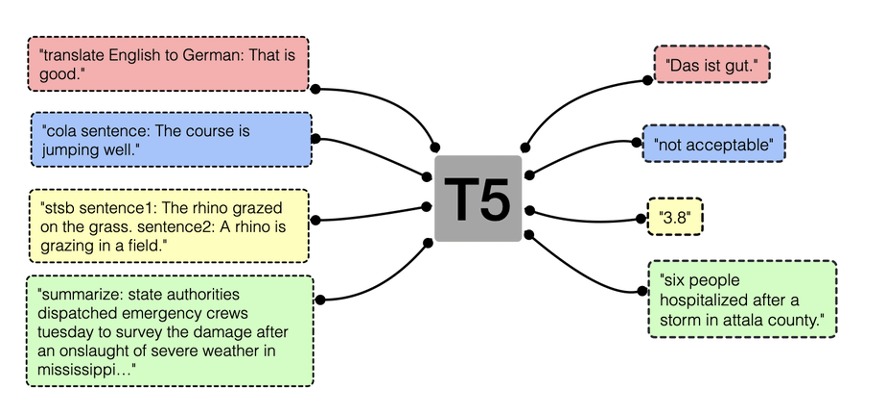
這T5是 “ Transfer Text-to-Text Transformer ” 名稱的縮寫,在 2019 年底提出。T5 使用基本的編碼器-解碼器 Transformer 架構。MT5是T5 的多語言延伸。MT5的5種不同大小的變體:小模型、基礎模型、大模型、XL和XXL模型。例如,在這本篇文章的範例裡,所使用的是小模型的MT5,稱為:“ mt5-small ”。
範例說明
Step-1:觀察&測試原模型(如mt5)的input和output格式
以一個範例程式,來演示這個步驟。程式碼:
# mt5_lora_001_test.py
#了解原模型(mt5)的input和output格式
import numpy as np
import torch
import torch.nn as nn
from transformers import MT5Tokenizer, MT5ForConditionalGeneration
model_name = "google/mt5-small"
#======== 載入預訓練tokenizer ========================
tokenizer = MT5Tokenizer.from_pretrained(model_name)
#======== 載入mt5_small pre-trained模型 ==============
mt5_model = MT5ForConditionalGeneration.from_pretrained(model_name)
#--------- 測試input ------------------------------
#有一位農夫只是天天挑水澆花,對花很有愛心,捨不得摘花去賣,
#因而他成為大富翁。
text = "There was a farmer who only liked to " \
+ "carry water to water the flowers every day. " \
+ "He loved flowers very much and was reluctant " \
+ "to pick flowers to sell, so he became a rich man."
#======= 對pre-trained model進行測試 =================
#解析詞彙
text_features = tokenizer( text, max_length=16,
padding='max_length',
truncation=True,
return_attention_mask=True,
add_special_tokens=True,
return_tensors='pt'
)
bids = text_features['input_ids']
batt = text_features['attention_mask']
outputs = mt5_model.generate(input_ids=bids, attention_mask=batt,
max_length=513, num_beams=4,
repetition_penalty=2.5,
length_penalty=1.0,
early_stopping=True
)
print('\n======== model outputs ========')
print(outputs)
gid = outputs[0]
print('\n======== decoder result ========')
res = tokenizer.decode(gid)
print(res)
#-----------------
#END
首先,執行到指令:

就會載入預訓練模型:”google/mt5-small”。接著,下列指令是準備一個輸入的文句(Text):

接著,下列指令解析輸入的文句:

就得到該文句的特徵,即text_features。接著,指令:

就將text_features輸入給mt5-small模型,而輸出outputs。最後,由decoder輸出結果:

這個範例程式的用意是:檢查是否能順利下載原模型(即”google/mt5-small”),並觀察輸入文句的格式。
Step-2:準備Training data,建立自己的Dataset類別,並拿原模型實際訓練
上一步驟已經順利下載原模型(即”google/mt5-small”),並能雲行起來。那麼,就可以準備Training data來訓練它。我們就以一個範例程式,來演示這個步驟:
# mt5_lora_002_train.py
# 準備Training data,建立自己的Dataset類別
# 並拿原模型實際訓練
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from transformers import MT5Tokenizer
from transformers import MT5Config, MT5ForConditionalGeneration
model_name = "google/mt5-small"
#======== 載入預訓練tokenizer ========================
tokenizer = MT5Tokenizer.from_pretrained(model_name)
mt5_model = MT5ForConditionalGeneration.from_pretrained(model_name)
#======== 準備source文本 ============================
#在機器翻譯任務中,需要將來源文本轉換為模型可以處理的格式。
#使用MT5Tokenizer可以將文本轉換為token-ids,
#然後將它們輸入到模型中。
#--------- 第1筆 ---------------------------------
#有一位農夫只是天天挑水澆花,對花很有愛心,捨不得摘花去賣,
#因而他成為大富翁。
text_1 = "There was a farmer who only liked to " \
+ "carry water to water the flowers every day. " \
+ "He loved flowers very much and was reluctant " \
+ "to pick flowers to sell, so he became a rich man."
#--------- 第2筆 ---------------------------------
#有一位森林管理者只是叫啄木鳥好好關注它愛吃的蟲兒,因而森林裡
#的樹木都沒蟲害,因而很健康。
text_2 = "There was a forest manager who just asked the " \
+ "woodpecker bird to pay attention to the insects it " \
+ "loved to eat, so the trees in the forest were " \
+ "insect-free and very healthy."
#--------- 第3筆 ---------------------------------
#一個人想去南極找企鵝,它眼睛關注著北極星,雙手努力划船,
#逐漸就見到南極許多企鵝了。
text_3 = "A man wanted to go to Antarctica to find " \
+ "penguins. He focused his eyes on the North " \
+ "Star and rowed hard with both hands, and gradually " \
+ "he saw many penguins in Antarctica."
text_list = [text_1, text_2, text_3]
#======== 準備target文本 ============================
#愛心致富,符合鳥性,把握方向
summary_list = ["Love makes you rich, such as loving flowers.",
"In line with bird nature, humans get healthy trees.",
"Gaze at the North Star and reach the Antarctic to see penguins."]
#======== 建立DS&DL ================================
class myDataset(Dataset):
def __init__( self ):
self.text_max_len = 16
self.summary_max_len = 8
def __len__(self):
return 3
def __getitem__(self, idx):
text = text_list[idx]
text_features = tokenizer(
text,
max_length=self.text_max_len,
padding='max_length',
truncation=True,
return_attention_mask=True,
add_special_tokens=True,
return_tensors='pt'
)
summ = summary_list[idx]
summary_features = tokenizer(
summ,
max_length=self.summary_max_len,
padding='max_length',
truncation=True,
return_attention_mask=True,
add_special_tokens=True,
return_tensors='pt'
)
#return text_features, summary_features
labels = summary_features['input_ids']
labels[labels == tokenizer.pad_token_id] = -100
return dict(
input_ids=text_features['input_ids'].flatten(),
attention_mask=text_features['attention_mask'].flatten(),
labels=labels.flatten(),
decoder_attention_mask=summary_features['attention_mask'].flatten()
)
ds = myDataset()
dl = DataLoader(ds, shuffle=True, batch_size=3)
#======== 展開訓練 ====================================
optimizer = torch.optim.Adam(mt5_model.parameters(), lr=0.0004)
mt5_model.train()
epochs = 10
print('\n開始訓練...')
for ep in range(epochs):
#print(ep)
for batch in dl:
inputs = {k: v for k, v in batch.items()}
outputs = mt5_model(**inputs)
logits = outputs.logits
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
pass
if(ep%2==0):
print(f'ep: {ep + 1} -- loss: {loss}')
#------------------------------------------
print('\nok')
#END
首先,準備3個source文本,以及3個target文本。來作為Training dataset。然後展開訓練,輸出如下:
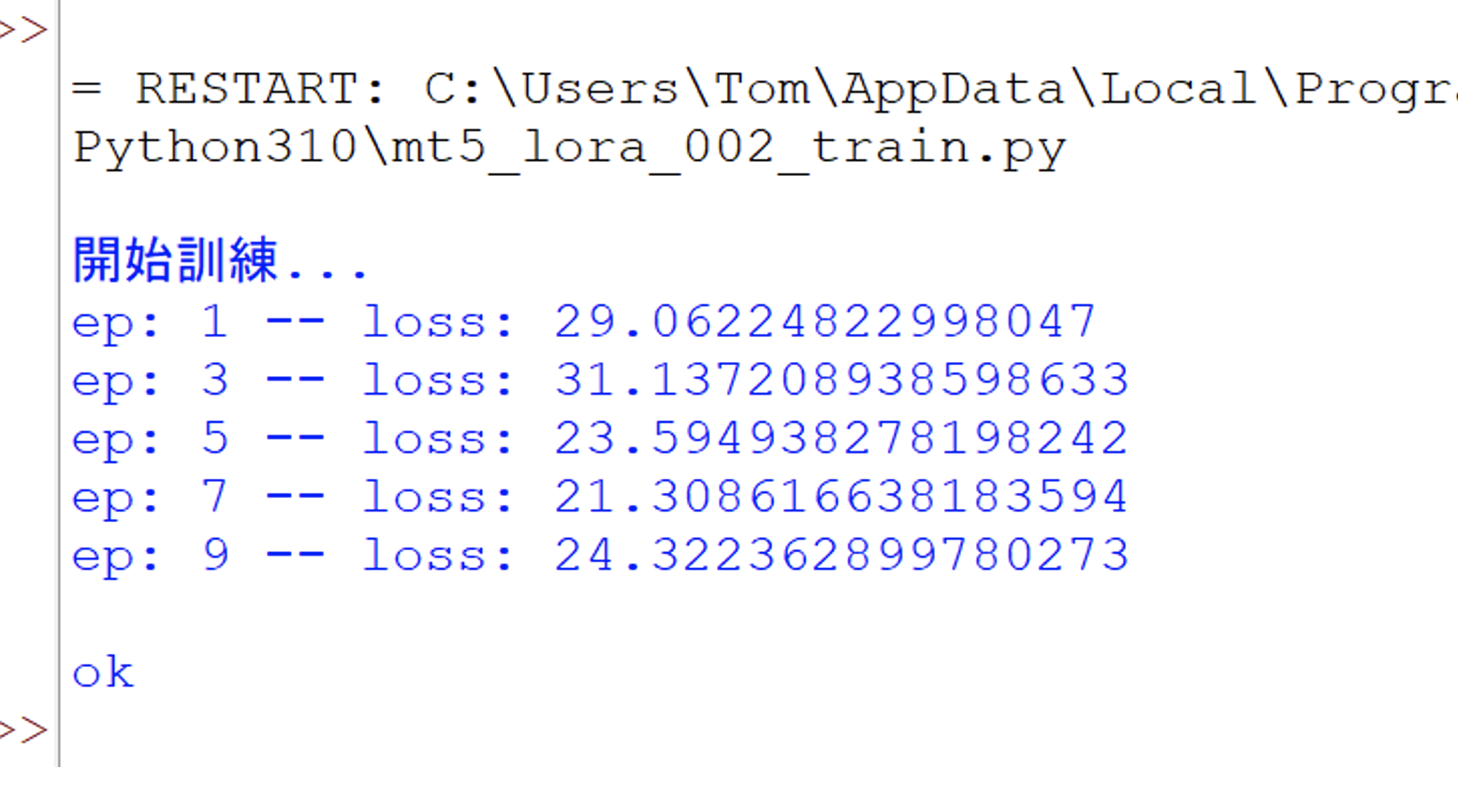
這個範例程式的用意是:檢驗Training data格式的正確性,是否能順利輸入給原模型(即”google/mt5-small”),並觀察optimizer設定,以及loss的計算。並觀察loss的下降情形。
Step-3:將LoRA外掛到MT5-Small,並進行協同訓練及測試
以一個範例程式,來演示這個步驟:
# mt5_lora_003_lora.py
# 掛上LoRA,並進行訓練及測試
import numpy as np
import torch
import torch.nn as nn
from functools import partial
from torch.utils.data import Dataset, DataLoader
from transformers import MT5Tokenizer
from transformers import MT5Config, MT5ForConditionalGeneration
import min_lora_model as Min_LoRA
import min_lora_utils as Min_LoRA_Util
model_name = "google/mt5-small"
#======== 載入預訓練tokenizer ========================
tokenizer = MT5Tokenizer.from_pretrained(model_name)
mt5_model = MT5ForConditionalGeneration.from_pretrained(model_name)
#-------- 添加LoRA ------------
my_lora_config = {
nn.Linear: {
"weight": partial(Min_LoRA.LoRAParametrization.from_linear, rank=16),
}, }
#---- 把LoRA參數添加到原模型 ------
# Step 1: Add LoRA to the unet model
Min_LoRA.add_lora(mt5_model, lora_config=my_lora_config)
#---------------------------------------------------------------
parameters = [
{"params": list(Min_LoRA_Util.get_lora_params(mt5_model))}, ]
#只更新、優化LoRA的Weights
optimizer = torch.optim.Adam(parameters, lr=0.0004)
#======== 準備source文本 ============================
#在機器翻譯任務中,需要將來源文本轉換為模型可以處理的格式。
#使用MT5Tokenizer可以將文本轉換為token-ids,
#然後將它們輸入到模型中。
#--------- 第1筆 ---------------------------------
#有一位農夫只是天天挑水澆花,對花很有愛心,捨不得摘花去賣,
#因而他成為大富翁。
text_1 = "There was a farmer who only liked to " \
+ "carry water to water the flowers every day. " \
+ "He loved flowers very much and was reluctant " \
+ "to pick flowers to sell, so he became a rich man."
#--------- 第2筆 ---------------------------------
#有一位森林管理者只是叫啄木鳥好好關注它愛吃的蟲兒,因而森林裡
#的樹木都沒蟲害,因而很健康。
text_2 = "There was a forest manager who just asked the " \
+ "woodpecker bird to pay attention to the insects it " \
+ "loved to eat, so the trees in the forest were " \
+ "insect-free and very healthy."
#--------- 第3筆 ---------------------------------
#一個人想去南極找企鵝,它眼睛關注著北極星,雙手努力划船,
#逐漸就見到南極許多企鵝了。
text_3 = "A man wanted to go to Antarctica to find " \
+ "penguins. He focused his eyes on the North " \
+ "Star and rowed hard with both hands, and gradually " \
+ "he saw many penguins in Antarctica."
text_list = [text_1, text_2, text_3]
#======== 準備target文本 ============================
#愛心致富,符合鳥性,把握方向
summary_list = ["Love makes you rich, such as loving flowers.",
"In line with bird nature, humans get healthy trees.",
"Gaze at the North Star and reach the Antarctic to see penguins."]
#======== 建立DS&DL ================================
class myDataset(Dataset):
def __init__( self ):
self.text_max_len = 16
self.summary_max_len = 8
def __len__(self):
return 3
def __getitem__(self, idx):
text = text_list[idx]
text_features = tokenizer(
text,
max_length=self.text_max_len,
padding='max_length',
truncation=True,
return_attention_mask=True,
add_special_tokens=True,
return_tensors='pt'
)
summ = summary_list[idx]
summary_features = tokenizer(
summ,
max_length=self.summary_max_len,
padding='max_length',
truncation=True,
return_attention_mask=True,
add_special_tokens=True,
return_tensors='pt'
)
labels = summary_features['input_ids']
labels[labels == tokenizer.pad_token_id] = -100
return dict(
input_ids=text_features['input_ids'].flatten(),
attention_mask=text_features['attention_mask'].flatten(),
labels=labels.flatten(),
decoder_attention_mask=summary_features['attention_mask'].flatten()
)
ds = myDataset()
dl = DataLoader(ds, shuffle=True, batch_size=3)
#======== 展開MT5 + LoRA 協同訓練 =====================
print('\n展開MT5 + LoRA 協同訓練...')
mt5_model.train()
epochs = 50
for ep in range(epochs):
for batch in dl:
inputs = {k: v for k, v in batch.items()}
outputs = mt5_model(**inputs)
logits = outputs.logits
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
pass
if(ep%5==0):
print(f'ep: {ep + 1} -- loss: {loss}')
#------------------------------------------
base_path = 'c:/ox/'
FILE = base_path + 'MT5_LORA_003_30.ckpt'
torch.save(mt5_model.state_dict(), FILE)
print("\n--- Saved to " + FILE)
#-------------- 進行檢測 -------------------
text = text_list[0]
text_features = tokenizer(
text,
max_length=16,
padding='max_length',
truncation=True,
return_attention_mask=True,
add_special_tokens=True,
return_tensors='pt'
)
outputs = mt5_model.generate(
input_ids=text_features['input_ids'],
attention_mask=text_features['attention_mask'],
max_length=513,
num_beams=4,
repetition_penalty=2.5,
length_penalty=1.0,
early_stopping=True
)
print('\n======== model outputs ========')
print(outputs)
gid = outputs[0]
print('\n======== decoder result ========')
res = tokenizer.decode(gid)
print(res)
#--------------------------------------------
#END
首先,執行到指令:

就把LoRA參數外掛到MT5模型上,繼續執行到指令:

設定:optimizer只會更新LoRA的參數,亦即,凍結原模型的參數。然後,展開協同訓練,輸出:

觀察loss的下降情形。最後,輸入測試文本,輸出測試結果:

這樣就完成了:LoRA外掛到MT5。然後,就可以使用實際大量的Training dataset,繼續邁向美好的微調之路。
(責任編輯:謝嘉洵。)

近5年來,從事於AI普及化教育工作,目前擔任銘傳大學AI課程、長庚智慧醫療研究所AI課程授課老師。也擔任永春國小、東園國小、立志中學、君毅中學、永春高中等學校的AI師資培育工作。
- LoRA微調三步驟:以大語言模型MT5為例 - 2024/05/02
- 為什麼Gemma採取Decoder-Only Transformer架構呢? - 2024/04/08
- 如何從0訓練企業自用Gemma模型 - 2024/04/03
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


