作者:陸向陽
眾所皆知,現在運用生成式人工智慧(Generative AI, GenAI)模型,給予它提示文字,而後就可以生出與文字描述相符的圖,此稱之為文字生成圖片(Text-to-Image, T2I),這類型的知名線上服務如DALL‧E、Midjourney、Stable Diffusion(簡稱SD)等。
不過使用過的人多少也發現,有時候會產生圖文不符的情況,或者有人物手指生成不自然、文字生成怪異等情形,很明顯模型的認知能力仍有不足處。那麼,該如何判定模型生出的圖好或不好?精確不精確呢?個人觀感評斷是一個,但過於主觀,是否能更客觀、量化的衡量方式呢?
這也類似過往至今的文字翻譯技術,英翻中、中翻英等線上翻譯翻的好或不好?人為判定是其一,但其實也有客觀的判定標準,即雙語評估替補(Bilingual Evaluation Understudy, BLEU)。
同理,Google購併的DeepMind人工智慧技術團隊也嘗試建立文生圖的客觀量化評估方法,目前已有構想與初步研究成果,此方法稱之為蜥蜴、壁虎(Gecko),DeepMind團隊已經在arXiv上發表Gecko相關的論文。
Gecko框架
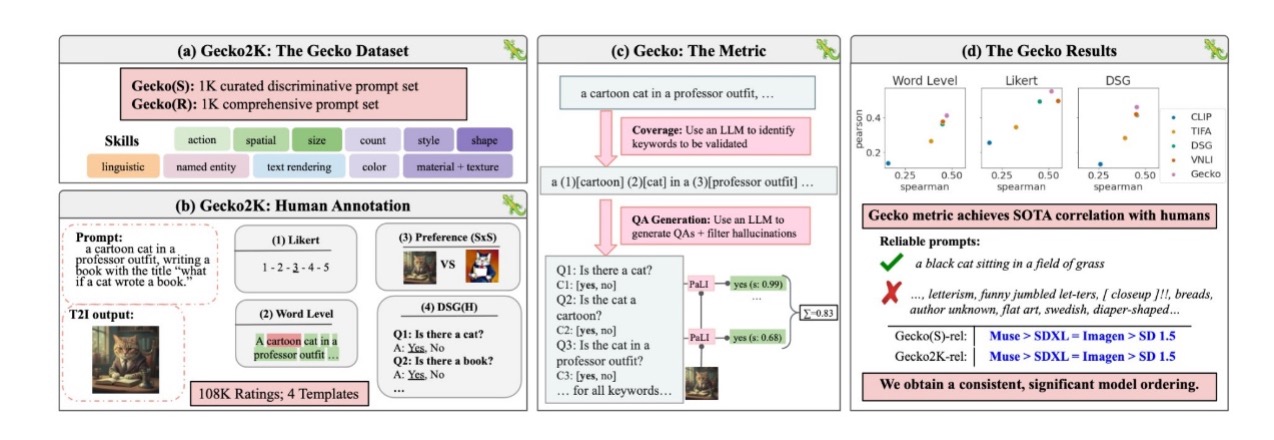
圖1 Google/DeepMind提出的Gecko框架(圖片來源:Google)
嚴格而論Gecko是一套評估框架,框架內有諸多要素,首先是Gecko2K,主要是研究者預先準備了1,000條策劃好的歧視提示文字,稱為Gecko(S),其實也用大型語言模型(Large Language Model, LLM)生成的文字;另外也準備1,000條包山包海的多樣性提示文字,稱為Gecko(R)。
運用這些預先研擬好的提示文字庫,來試煉模型的認知技能(skill),例如是否能識別空間(spatial)、是否能識別尺寸(size)、識別顏色、風格等等。
DeepMind團隊在論文中強調Gecko與其他的衡量方法相比有較大的技能覆蓋性,不僅分成多種類型的生圖技能,還分成主技能(目前12種)、子技能(sub-skill,目前36種)等,期望更完整、全面地判定生圖模型的好壞。
然後Gecko收集了10萬8千份人為評斷表,以四種範本方式評斷生出的圖是好是壞,例如使用李克特量表(Likert scale),即是今日問卷中常見的「喜歡1分、不喜歡5分,普通3分」的刻度評分表。
或者是偏好性SxS對比(Side by Side,或稱AB測試),還有對生成的圖進行文字層次(word-level)的標記,例如圖中出現哪些東西、沒有出現哪些東西?或者是DSG(H)(也稱VQA問答匹配),例如詢問圖片中有貓咪嗎?圖片中有書本嗎?
再來就進入正式的衡量階段,運用一個大型語言模型(Large Language Model, LLM)來識別關鍵字是否有效,然後也用大型語言模型來產生問答(QA),並搭配幻覺過濾等。
設計出評判方式後,論文中也找了四個文生圖模型來測試,分別是SD1.5(Stable Diffusion 1.5版)、SDXL(Stable Diffusion XL)、Muse(Google自己訓練成的模型)、Imagen(也是Google的)等。
測試結果顯示,無論是在Gecko(S)或Gecko2k上都以Muse模型表現較佳,好於SDXL,但SDXL能力與Imagen相近,但兩者的表現都優於SD 1.5。
此外,Gecko並非是目前唯一的文生圖模型表現優劣衡量法,其他還有CLIP、TIFA、DSG、VNLI等等,但Google/DeepMind強調Gecko的衡量比較全面,同時也較佳的解釋性,畢竟今日各國政府與社會大眾越來越討厭黑箱、無法解釋、不負責的人工智慧作法。
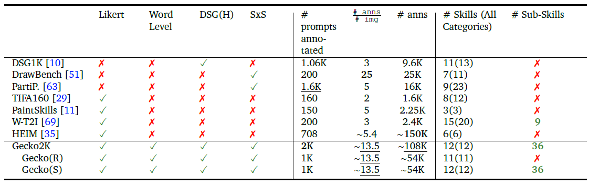
圖2 Gecko外的其他圖生文評估方式較不全面,例如DrawBench只使用SxS方式衡量,或TIFA160只用刻度表衡量,測試份量也以Gecko較多(圖片來源:Google)
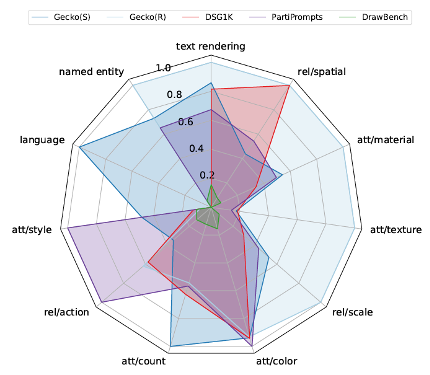
圖3 以雷達圖(國外其實稱為Spider Chart蜘蛛圖)來比較不同衡量方式的全面性,從覆蓋面積可瞭解Gecko(S)、Gecko(R)好於DSG1K、PartiPrompts、DrawBench等衡量方式(圖片來源:Google)
論文除了強調Gecko衡量法比較全面、可解釋外,也強調評判的一致性,意思是進行多次評判後所得到的多組分數,其分數偏差範圍是比較小的,言下之意是一個更可靠的衡量方式。
結語
Gecko的提出,其實是希望擺脫人工三兩句(樣本過少且主觀)就論斷模型好壞,也希望擺脫太過概略粗糙且難以解釋的表現給分系統,同時也讓正在訓練文生圖模型的開發者有更具體的精進方向與目標,已經表現很好的技能則可以維持,讓有限的開發精力更有效的運用。
當然,Gecko衡量方式若能獲得開發端的普遍認同與運用,也會期望直接向廣大群眾推廣,說不定後續各家的線上文生圖服務會標榜自己的新版模型在Gecko(S)某些技能項上獲得幾分,因此勝過同業等,成為其行銷上的素材、賣點號召。

- 小孩才選擇!Arduino VENTUNO Q全都要 - 2026/03/26
- 樹莓派也能「養龍蝦」! - 2026/03/24
- Windows PC上安裝PicoClaw最基礎實務 - 2026/03/03
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!