2024 MAI 開發者大會以「Make AI a Reality」為精神,希望架起AI技術與應用的橋樑,廣邀開發社群先進擔任講者,2天共20場演講,為AI開發者及AI Maker們領路。探討主題涵蓋先進及實用 AI 工具、框架、平台技術;Edge AI開發環境、推論優化與佈建;熱門關鍵技術:Local LLM、RAG、NPU、GenAI…;創新與落地Edge AI應用。
在台大資工系陳縕儂副教授主講的「打造台版LLM的理由與挑戰」演講中,主要討論了建立台灣版大型語言模型(LLM)的必要性及挑戰,並分享了她和她的學生在這方面的努力和成果。

台大資工系陳縕儂副教授
建立台版LLM的必要性
陳縕儂指出,建立台版LLM的主要理由包括:
1.優化繁體中文:
現有的LLM多數是基於英文或簡體中文訓練的,對於台灣繁體中文的支持和理解存在不足。因此,建立以繁體中文為主的台版LLM能更好地服務本土用戶。
2.避免一言堂:
不同國家和地區有其獨特的文化和價值觀。台灣版LLM可以更好地反映本土文化,避免全球化模型中可能存在的偏見和不適。
3.加強在地文化:
單一模型獨大的情況下,語言多元性和文化多樣性可能會被扼殺。建立多個不同語言和文化背景的模型有助於保持多樣性,也有助於加強在地文化的差異性。

(Source: 講者簡報)
技術與訓練挑戰
在訓練和開發台版LLM的過程中,陳縕儂提到了一些關鍵挑戰,例如台灣本土的資料量相對較少,因此在訓練模型時面臨資料不足的問題。對此她呼籲更多本地企業和機構參與資料共享,以豐富訓練資料集。
此外,初期的資料過濾和質量控制非常重要,她強調使用不當的資料集可能會導致模型性能下降,或帶入有偏差的觀點(Data Bias),因此需要嚴格篩選和驗證訓練資料。另一個挑戰則來自模型的微調,在模型的微調過程中,必須不斷進行測試和優化,確保模型能夠準確理解和生成符合本地需求的內容。
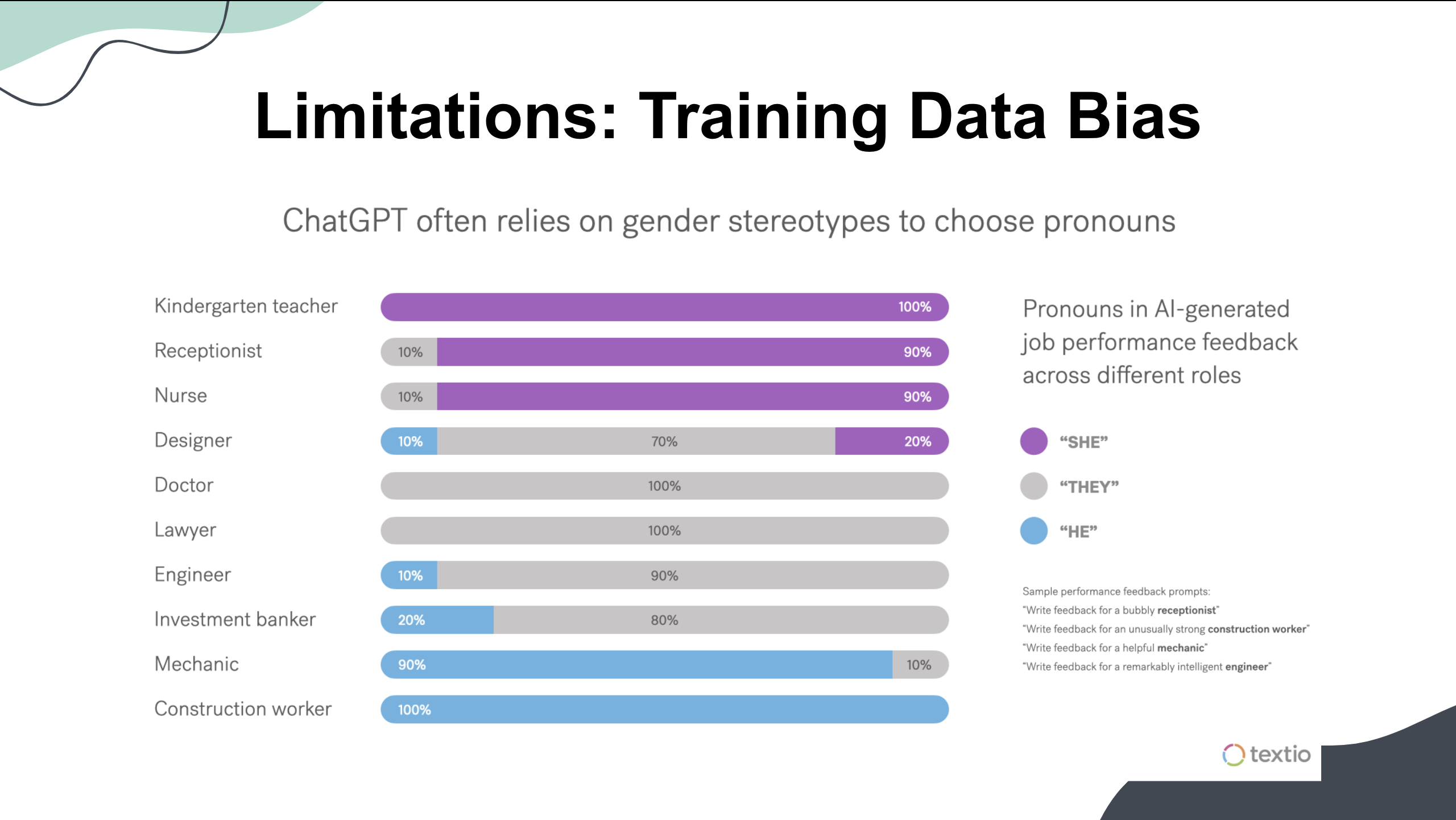
(Source: 講者簡報)
應用與實例
陳縕儂進一步展示了一些實際應用中的例子,說明台版LLM的潛力和應用場景:
- 文書編輯:在文書編輯和翻譯方面,台版LLM能夠提供更符合本地語言習慣的建議,提升工作效率。
- 知識問答:通過訓練模型理解本地文化和知識,可以在問答系統中提供更準確和相關的回答。
- 教育訓練:模型可以用於教育和培訓,提供個性化學習輔導,幫助學生更好地理解和掌握知識。

未來發展方向
針對未來台版LLM的發展方向,陳縕儂期待看到模型不斷更新和優化,藉由收集更多本地資料和反饋,不斷提升性能和準確性。此外,建立一個成功的LLM需要多方合作,包括計算資源的投入、專業知識的融合以及實際應用場景的測試和驗證,因此需要跨領域的合作。在模型應用過程中,則必須注意資料隱私和安全,確保用戶數據不被濫用或泄露。
總結來說,打造台版LLM是一個需要多方努力的長期過程。通過結合本地資料和需求,並與各領域專家合作,台版LLM能夠在多種應用場景中發揮重要作用,為台灣的技術發展和文化傳播貢獻力量。陳縕儂呼籲更多人參與這一過程,共同推動本地化AI技術的進步。

- 更強大的開源運算:Arduino VENTUNO Q技術詳解 - 2026/04/17
- NVIDIA推出首款用於加速實用量子電腦發展的開放式AI模型 - 2026/04/17
- AI新十大建設:國研院國家智慧機器人研究中心揭牌 - 2026/04/16
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


