作者:黃佳琪、高煥堂 / 神櫻團隊成員
使用Gemma源碼解說
從典型的Transformer模型說起
最初在 2017 年的論文「Attention is All You Need」中介紹,Transformer 具有解碼器(Decoder)和編碼器(Encoder)部分。如下圖:
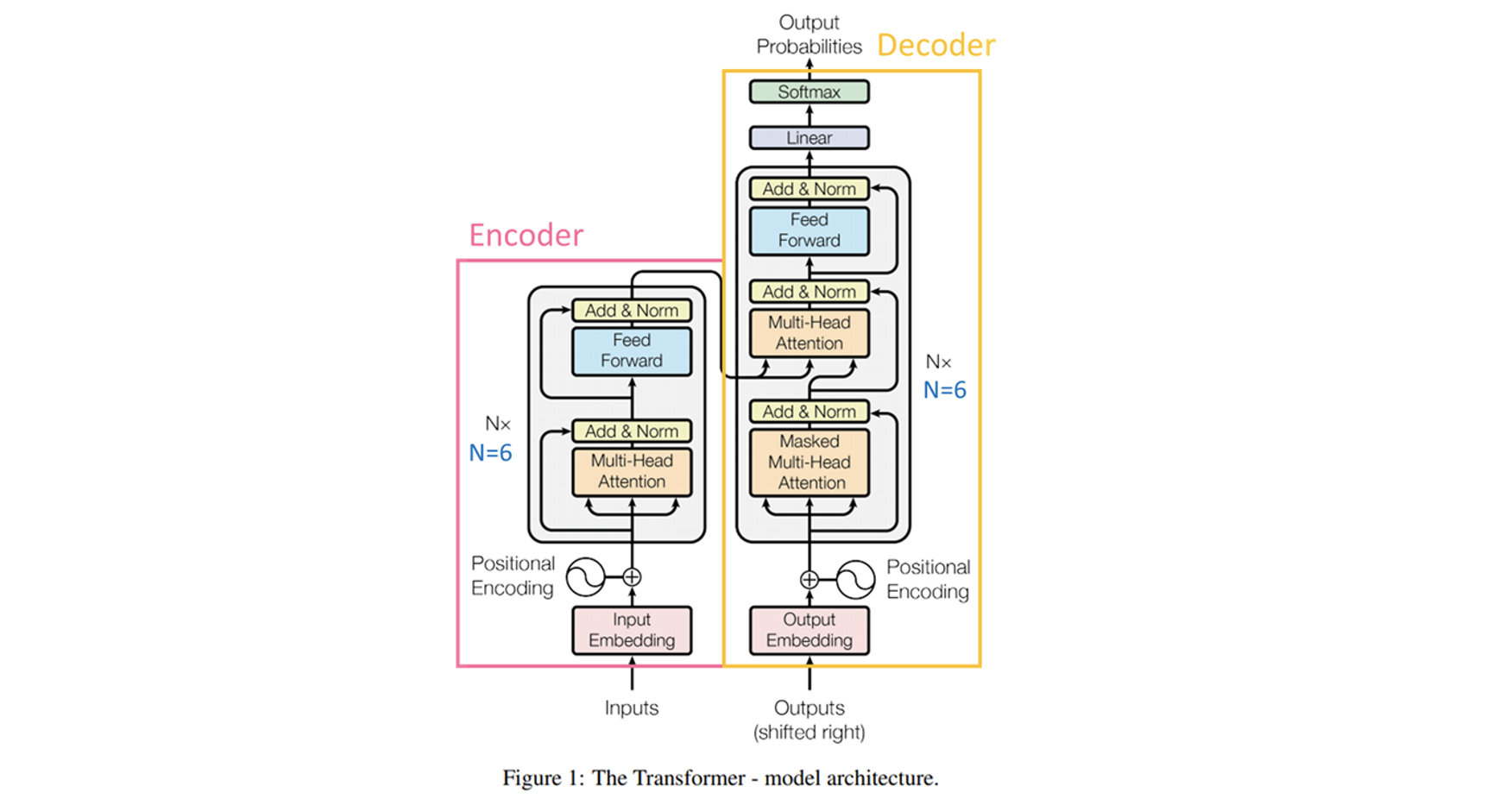
這種典型Encoder-Decoder架構的使用情境,通常是將一種類型的序列(Sequence)對應到另一種類型的序列,例如將法語翻譯成英語,或在聊天機器人獲取對話上下文並產生回應的情況下。在這些情況下,輸入和輸出之間存在質的差異,因此對它們使用不同的權重是有意義的。
例如,GPT-2是在維基百科文章等連續文本上進行訓練的,如果我們想使用上圖的典型Encoder-Decoder架構,就必須進行任意截斷來確定Encoder將處理哪一部分,以及哪一部分由Decoder負責。因此,由於GPT-2在文字生成方面的出色性能,趨勢是轉向純解碼器(Decoder-Only Transformer)模型。僅解碼器模型的強大之處在於它們不僅能夠模仿類似人類的文本,而且還能夠創造性地做出回應。他們可以寫故事、回答問題,甚至進行自然流暢的對話。這種功能使它們在廣泛的應用中非常有用,從聊天機器人和數位助理到內容創建、抽象總結和講故事。
因此,GPT-2和Gemma並不需要 Transformer 架構的編碼器部分,因為模型使用只能查看先前標記的屏蔽自注意力。不需要編碼器,因為模型不需要學習輸入序列的表示。此外,Decoder-Only Transformer 架構在 GPT-3、ChatGPT、GPT-4、PaLM、LaMDa 和 Falcon 等流行的大型語言模型中受到關注。
當今流行的Decoder-Only架構
在上述典型的Transformer架構裡,解碼器(Decoder)從最初位於編碼器(Encoder)端的所有輸入Token開始。這意味著Decoder現在具有編碼器的文字輸入,解碼器現在必須預測下一個標記。本質上,解碼器從一開始就執行編碼部分。Decoder-Only Transformer架構是由多個具有相同結構的區塊(Block)按順序堆疊組成。在每個區塊中,都有兩個主要組件:
- Masked, multi-headed self-attention。
- A feed-forward transformation。
此外,我們通常會用殘差連接(Residual connection)和歸一化(Normalization)層來圍繞這些元件。如下圖所示,就是一個區塊:
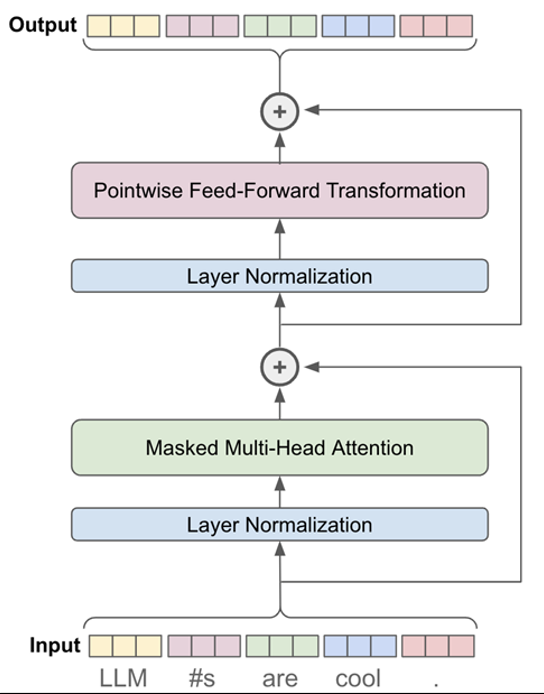
(圖片來源)
就如上圖所示,一個完整的Decoder-Only Trnsformer區塊,通常必須使用到這4種組件:
- Masked, multi-headed self-attention
- Layer normalization
- Feed-forward transformation
- Residual Connections
這個模型背後的真正驅動力是 Masked Self-Attention 機制。這種機制允許模型在預測每個標記時專注於輸入序列的不同部分,從而促進上下文相關文字的生成。
歸一化(Normalization)層透過計算輸入最終維度的平均值和標準差,消除了批量歸一化對批量維度的依賴。這意味著我們計算嵌入維度上的歸一化統計資料。
而Feed-Forward Layer 是一種前饋層,由兩個適用於最後一個維度的密集層組成,這意味著序列中的每個位置項都使用相同的密集層,因此稱為位置方式。
殘差連接(Residual connections)是一個通用概念,可以應用於任何不改變輸入維度的神經網路層。透過增加殘差連接,我們可以緩解梯度消失和爆炸的問題,並提高訓練過程的整體易用性和穩定性。
基於上述的解碼器區塊(Decoder Block),就可以依據需求的不同,而有多個彼此堆疊的解碼器區塊。如下圖所示:
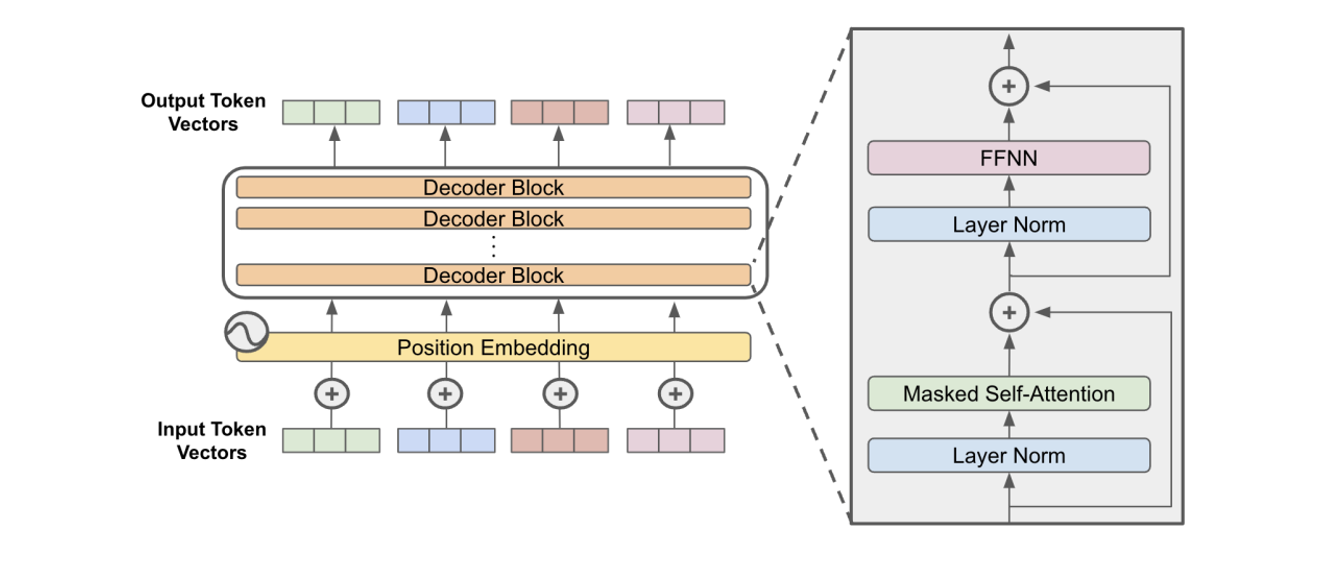
由上所述可以知道了,Gemma不需要原始Transformer架構的編碼器(Encoder)部分,因為它只是解碼器(Decoder),並且沒有編碼器注意塊,因此解碼器相當於編碼器,除了多頭注意塊中的MASKING ,解碼器只允許從句子中前面的單字收集資訊。它的工作原理就像傳統的語言模型一樣,因為它以詞向量作為輸入,並產生下一個詞的機率作為輸出的估計,但它是自回歸的,因為句子中的每個標記都有前一個詞的上下文。因此,Gemma一次只運行一個令牌;不需要編碼器,因為模型不需要學習輸入序列的表示。
Gemma 和 ChatGPT 使用僅解碼器變壓器。由於 Gemma 和 ChatGPT 僅適用於解碼器,因此它們適用於文字到文字的 LLM,但不適用於圖像和影片。而Google Gemini 同時使用解碼器和編碼器架構。該架構實現了Gemini 的多模式功能,使其能夠在用戶提示及其回應中支援語音和圖像以及文字。
觀摩Gemma的源碼結構
請觀摩這個範例程式碼,是引自Gemma的開源程式碼,僅稍微調整其參數而已(如減改Attention heads的數量等)。這個範例程式可以在Python IDLE環境裡執行。其程式碼如下:
# gem_decoder_001.py
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
from einops import rearrange
from typing import Any, List, Optional, Sequence, Tuple, Union
class GemmaConfig:
# The number of tokens in the vocabulary.
vocab_size: int = 10
# The maximum sequence length that this model might ever be used with.
max_position_embeddings: int = 8192
# The number of blocks in the model.
num_hidden_layers: int = 2
# The number of attention heads used in the attention layers of the model.
num_attention_heads: int = 3
# The number of key-value heads for implementing attention.
num_key_value_heads: int = 1
# The hidden size of the model.
hidden_size: int = 10
# The dimension of the MLP representations.
intermediate_size: int = 16
# The number of head dimensions.
head_dim: int = 8
# The epsilon used by the rms normalization layers.
rms_norm_eps: float = 1e-6
# The dtype of the weights.
dtype: str = 'bfloat16'
# Whether a quantized version of the model is used.
quant: bool = False
# The path to the model tokenizer.
tokenizer: Optional[str] = 'tokenizer/tokenizer.model'
#-----------------------------------------
def apply_rotary_emb(x: torch.Tensor, freqs_cis: torch.Tensor) -> torch.Tensor:
"""Applies the rotary embedding to the query and key tensors."""
x_ = torch.view_as_complex(
torch.stack(torch.chunk(x.transpose(1, 2).float(), 2, dim=-1),
dim=-1))
x_out = torch.view_as_real(x_ * freqs_cis).type_as(x)
x_out = torch.cat(torch.chunk(x_out, 2, dim=-1), dim=-2)
x_out = x_out.reshape(x_out.shape[0], x_out.shape[1], x_out.shape[2],
-1).transpose(1, 2)
return x_out
#--------------------------------------
class RMSNorm(torch.nn.Module):
def __init__(
self,
dim: int,
eps: float = 1e-6,
add_unit_offset: bool = True,
):
super().__init__()
self.eps = eps
self.add_unit_offset = add_unit_offset
self.weight = nn.Parameter(torch.zeros(dim))
def _norm(self, x):
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
x = self._norm(x.float()).type_as(x)
if self.add_unit_offset:
output = x * (1 + self.weight)
else:
output = x * self.weight
return output
class Linear(nn.Module):
def __init__(self, in_features: int, out_features: int, quant: bool):
super().__init__()
if quant:
self.weight = nn.Parameter(
torch.rand((out_features, in_features), dtype=torch.int8),
requires_grad=True,
)
self.weight_scaler = nn.Parameter(torch.Tensor(out_features))
else:
self.weight = nn.Parameter(
torch.rand((out_features, in_features)),
requires_grad=True,
)
self.quant = quant
def forward(self, x):
weight = self.weight
if self.quant:
weight = weight * self.weight_scaler.unsqueeze(-1)
output = F.linear(x, weight)
return output
#-----------------------------------------
class GemmaMLP(nn.Module):
def __init__(
self,
hidden_size: int,
intermediate_size: int,
quant: bool,
):
super().__init__()
self.gate_proj = Linear(hidden_size, intermediate_size, quant)
self.up_proj = Linear(hidden_size, intermediate_size, quant)
self.down_proj = Linear(intermediate_size, hidden_size, quant)
def forward(self, x):
gate = self.gate_proj(x)
gate = F.gelu(gate, approximate="tanh")
up = self.up_proj(x)
fuse = gate * up
outputs = self.down_proj(fuse)
return outputs
#---------------------------------------
# 定義模型
class GemmaAttention(nn.Module):
def __init__(
self,
hidden_size: int,
num_heads: int,
num_kv_heads: int,
head_dim: int,
quant: bool,
):
super().__init__()
self.num_heads = num_heads
self.num_kv_heads = num_kv_heads
assert self.num_heads % self.num_kv_heads == 0
self.num_queries_per_kv = self.num_heads // self.num_kv_heads
self.hidden_size = hidden_size
self.head_dim = head_dim
self.q_size = self.num_heads * self.head_dim
self.kv_size = self.num_kv_heads * self.head_dim
self.scaling = self.head_dim**-0.5
#--------------------------------
self.qkv_proj = Linear(self.hidden_size,
(self.num_heads + 2*self.num_kv_heads)*self.head_dim, quant=False )
self.o_proj = Linear(
self.num_heads * self.head_dim,
self.hidden_size,
quant=False )
def forward(
self,
hidden_states: torch.Tensor,
freqs_cis: torch.Tensor,
kv_write_indices: torch.Tensor,
kv_cache: Tuple[torch.Tensor, torch.Tensor],
mask: torch.Tensor,
) -> torch.Tensor:
hidden_states_shape = hidden_states.shape
assert len(hidden_states_shape) == 3
batch_size, input_len, _ = hidden_states_shape
#----------------------------
qkv = self.qkv_proj(hidden_states)
xq, xk, xv = qkv.split([self.q_size, self.kv_size, self.kv_size],
dim=-1)
xq = xq.view(batch_size, -1, self.num_heads, self.head_dim)
xk = xk.view(batch_size, -1, self.num_kv_heads, self.head_dim)
xv = xv.view(batch_size, -1, self.num_kv_heads, self.head_dim)
# Positional embedding.
xq = apply_rotary_emb(xq, freqs_cis=freqs_cis)
xk = apply_rotary_emb(xk, freqs_cis=freqs_cis)
# Write new kv cache.
# [batch_size, input_len, n_local_kv_heads, head_dim]
k_cache, v_cache = kv_cache
k_cache.index_copy_(1, kv_write_indices, xk)
v_cache.index_copy_(1, kv_write_indices, xv)
key = k_cache
value = v_cache
if self.num_kv_heads != self.num_heads:
# [batch_size, max_seq_len, n_local_heads, head_dim]
key = torch.repeat_interleave(key, self.num_queries_per_kv, dim=2)
value = torch.repeat_interleave(value,
self.num_queries_per_kv,
dim=2)
# [batch_size, n_local_heads, input_len, head_dim]
q = xq.transpose(1, 2)
# [batch_size, n_local_heads, max_seq_len, head_dim]
k = xk.transpose(1, 2)
v = xv.transpose(1, 2)
# [batch_size, n_local_heads, input_len, max_seq_len]
scores = torch.matmul(q, k.transpose(2, 3)) * self.scaling
scores = scores + mask
scores = F.softmax(scores.float(), dim=-1).type_as(q)
# [batch_size, n_local_heads, input_len, head_dim]
output = torch.matmul(scores, v)
# [batch_size, input_len, hidden_dim]
output = (output.transpose(1, 2).contiguous().view(
batch_size, input_len, -1))
output = self.o_proj(output)
return output
#-------------------------------------
class GemmaDecoderLayer(nn.Module):
def __init__(
self,
config
):
super().__init__()
self.self_attn = GemmaAttention(
hidden_size=config.hidden_size,
num_heads=config.num_attention_heads,
num_kv_heads=config.num_key_value_heads,
head_dim=config.head_dim,
quant=config.quant,
)
self.mlp = GemmaMLP(
hidden_size=config.hidden_size,
intermediate_size=config.intermediate_size,
quant=config.quant,
)
self.input_layernorm = RMSNorm(config.hidden_size,
eps=config.rms_norm_eps)
self.post_attention_layernorm = RMSNorm(config.hidden_size,
eps=config.rms_norm_eps)
def forward(
self,
hidden_states: torch.Tensor,
freqs_cis: torch.Tensor,
kv_write_indices: torch.Tensor,
kv_cache: Tuple[torch.Tensor, torch.Tensor],
mask: torch.Tensor,
):
# Self Attention
residual = hidden_states
hidden_states = self.input_layernorm(hidden_states)
hidden_states = self.self_attn(
hidden_states=hidden_states,
freqs_cis=freqs_cis,
kv_write_indices=kv_write_indices,
kv_cache=kv_cache,
mask=mask,
)
hidden_states = residual + hidden_states
# MLP
residual = hidden_states
hidden_states = self.post_attention_layernorm(hidden_states)
hidden_states = self.mlp(hidden_states)
hidden_states = residual + hidden_states
return hidden_states
#---------------------------------------
class GemmaModel(nn.Module):
def __init__(self, config):
super().__init__()
self.vocab_size = 10
self.num_hidden_layers = 2
self.rms_norm_eps = 1e-6
self.layers = nn.ModuleList()
for _ in range(config.num_hidden_layers):
self.layers.append(GemmaDecoderLayer(config))
self.norm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
def forward(
self,
hidden_states,
freqs_cis,
kv_write_indices,
kv_caches,
mask,
) -> torch.Tensor:
for i in range(len(self.layers)):
layer = self.layers[i]
hidden_states = layer(
hidden_states=hidden_states,
freqs_cis=freqs_cis,
kv_write_indices=kv_write_indices,
kv_cache=kv_caches[i],
mask=mask,
)
hidden_states = self.norm(hidden_states)
return hidden_states
#--------- 建立模型 --------------------
model = GemmaModel(GemmaConfig)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.004)
# 設定Target
T = torch.FloatTensor( [[0,0,0,0,0, 1,0,0,0,0],
[0,0,0,0,0, 0,1,0,0,0],
[0,0,0,0,0, 0,0,1,0,0],
[0,0,0,0,0, 0,0,0,1,0]] )
# Input資料
X = torch.FloatTensor( [[1,0,0,0,0, 0,0,0,0,0],
[0,1,0,0,0, 0,0,0,0,0],
[0,0,1,0,0, 0,0,0,0,0],
[0,0,0,1,0, 0,0,0,0,0]] )
X = X.unsqueeze(0)
T = T.unsqueeze(0)
batch_size = 1
seq_len = 4
num_kv_heads = 1
head_dim = 8
kc_cache = torch.randn(batch_size, seq_len, num_kv_heads, head_dim)
vc_cache = torch.randn(batch_size, seq_len, num_kv_heads, head_dim)
kv_cache = (kc_cache, vc_cache)
kv_caches = (kv_cache, kv_cache)
mask = torch.tensor([1, 1, 1, 1], dtype=torch.float32)
freqs_cis = torch.tensor([[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]
], dtype=torch.float32)
kv_write_indices = torch.LongTensor([0, 1, 2, 3])
#----------- 訓練1000回合 -----------------
print('展開訓練...')
for epoch in range(1000):
# 正向傳播
Z = model(X, freqs_cis, kv_write_indices, kv_caches, mask)
# 計算損失
loss = criterion(Z, T)
# 反向傳播和優化
optimizer.zero_grad()
loss.backward() # retain_graph=True )
optimizer.step()
# 每1個迴圈印出損失
if(epoch%100 == 0):
print('ep=', epoch, 'loss=', loss.item())
#------------------------------
Z = model(X, freqs_cis, kv_write_indices, kv_caches, mask)
print('\n----- Z -----')
print(np.round(Z.detach().numpy()))
#------------------
#END
此程式執行時,就展開訓練1000回合,並且輸出如下:

在這範例程式裡,各類別的組成一個區塊(Block),如下圖:
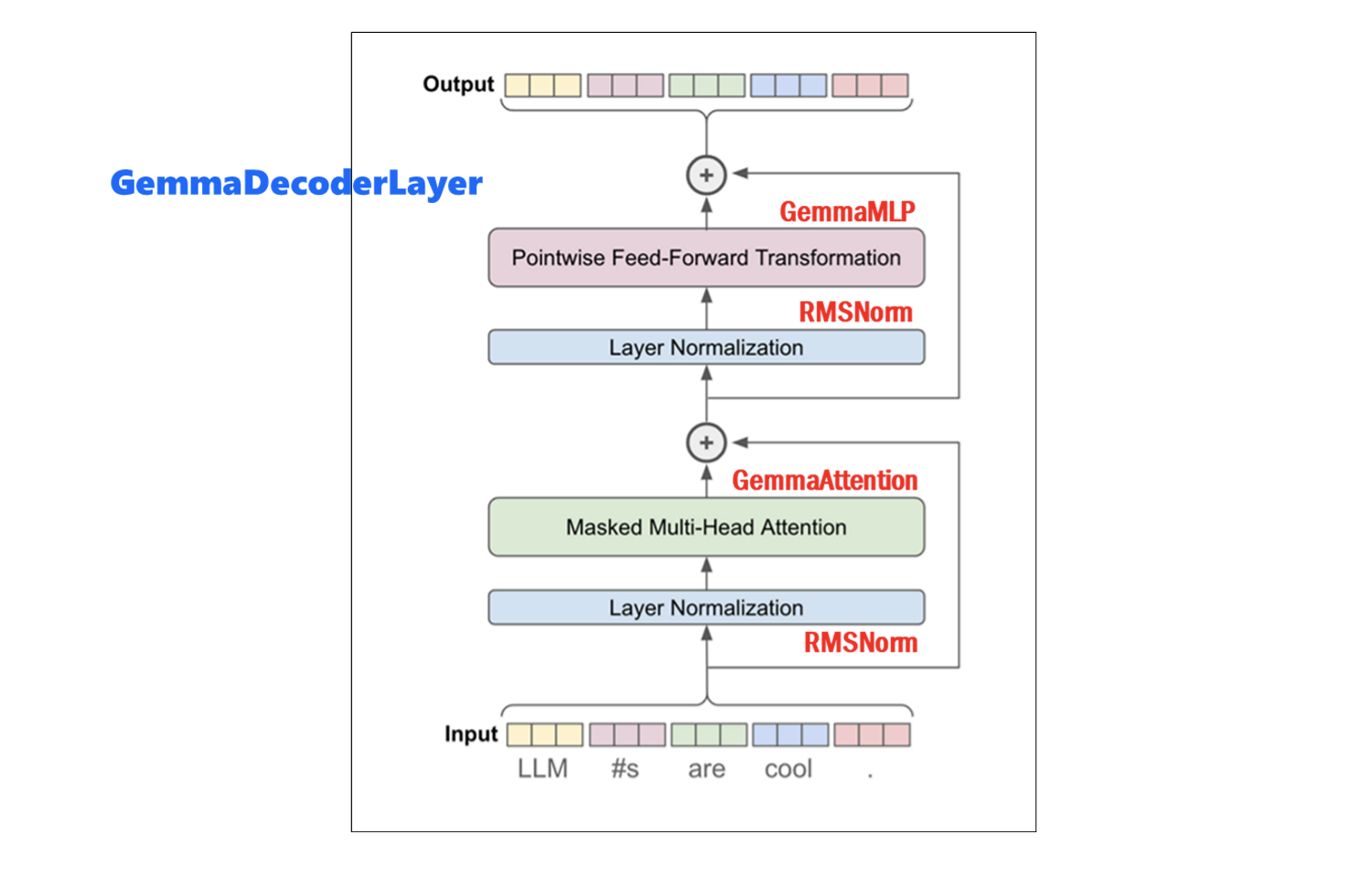
這個模型背後的真正驅動力是 GemmaAttention機制。這種機制允許模型在預測每個標記時專注於輸入序列的不同部分,從而促進上下文相關文字的生成。 RMSNorm層透過計算輸入最終維度的平均值和標準差,消除了批量歸一化對批量維度的依賴。而GemmaMLP是一種前饋層,由兩個適用於最後一個維度的密集層組成。還有殘差連接(Residual connections)可以緩解梯度消失和爆炸的問題,並提高訓練過程的整體易用性和穩定性。
基於上述的解碼器區塊(GemmaDecoderLayer),就可以依據需求的不同,而有多個彼此堆疊的解碼器區塊,組成了GemmaModel模型。如下圖所示:
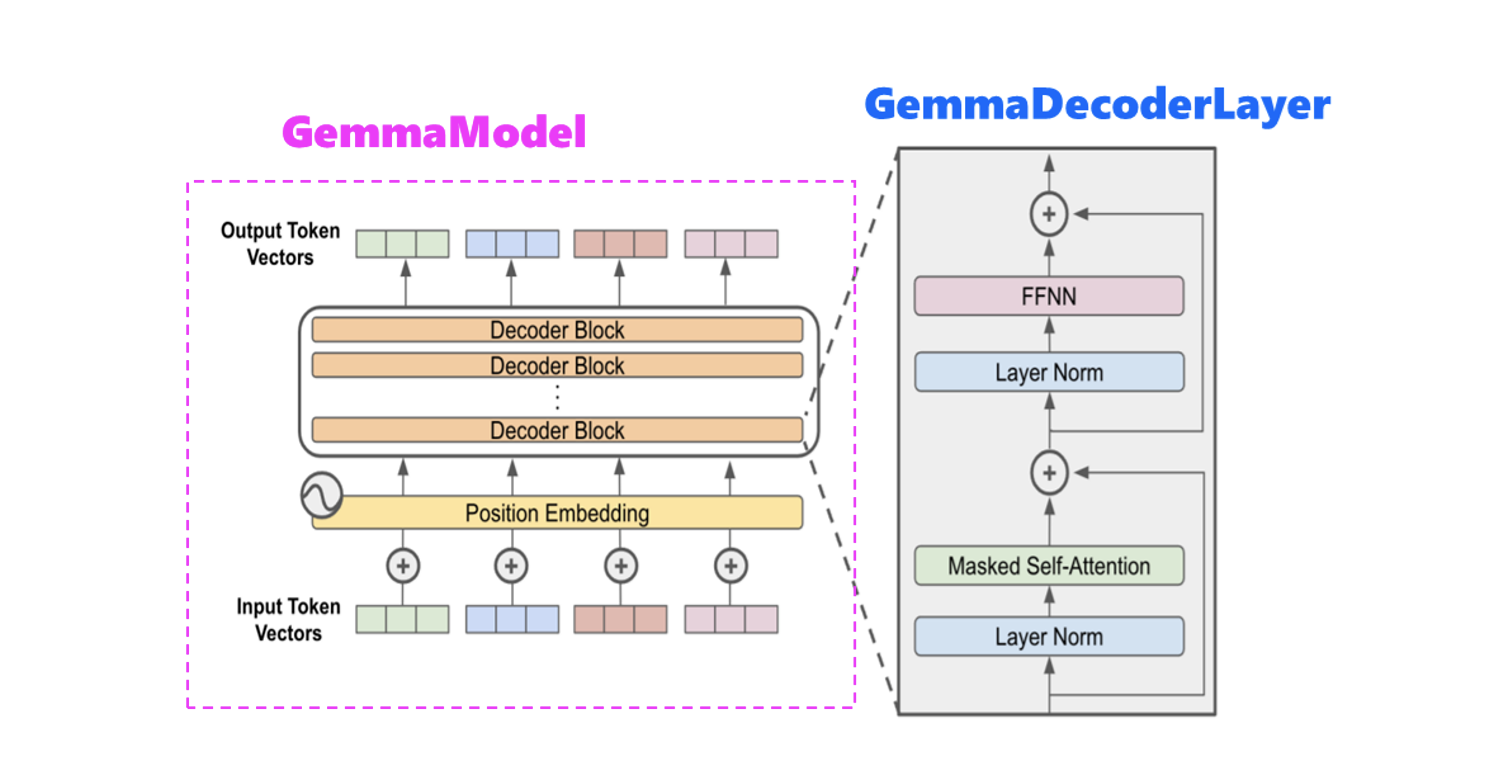
結語
對於 Gemma模型,輸出是提示後的下一個標記/單字的機率分配。它輸出完整輸入的一個預測。然而,儘管取得了這些快速的進步,LLM 的一個組成部分仍然保持不變——僅解碼器的變壓器(Decoder-Only Transformer)架構。
(責任編輯:謝嘉洵。)

近5年來,從事於AI普及化教育工作,目前擔任銘傳大學AI課程、長庚智慧醫療研究所AI課程授課老師。也擔任永春國小、東園國小、立志中學、君毅中學、永春高中等學校的AI師資培育工作。
- LoRA微調三步驟:以大語言模型MT5為例 - 2024/05/02
- 為什麼Gemma採取Decoder-Only Transformer架構呢? - 2024/04/08
- 如何從0訓練企業自用Gemma模型 - 2024/04/03
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


