作者:陸向陽
自從LLM/GenAI興起後,有一項遺憾是LLM/GenAI必須倚賴雲端資料中心機房裡龐大的運算力,才能即時完成推論結果並回應,一旦網路斷線就無法使用,且免費版服務已表明刻意放慢回應速度。
其他困擾也包含可能洩漏公司機密或個人隱私,南韓三星已有實際案例;或者GenAI因為他人的誤導而使回覆的答案飄移、前後不一;或者為了避免系統被誤導而導入「關鍵字把關系統」,會刻意忽略色情、犯罪、暴力、歧視等話語及用詞,這在多數情況下適用,但若有社會學研究生偏偏需要研究歧視議題,那就無法用雲端GenAI。
本機端、在地端的LLM
基於上述,人們開始期望有自己本機端、在地端(local)的LLM,主要PC晶片商也看準這點,在去年開始倡議AI PC概念,透過在PC內加強CPU、GPU的電路設計,或追加整合NPU等,大幅強化PC在LLM方面的計算速度,同時搭配上LLM的輕量化瘦身工程等,也是可以在自己電腦上實現一套LLM/GenAI系統與服務,從而解除上述的限制與困擾。
關於此倡議的實際行動,如Intel在去年底推出Core Ultra系列並搭載NPU,而今年2月NVIDIA也推出一套軟體Chat with RTX,言下之意可以下載、安裝輕量版的LLM到PC上,然後運用NVIDIA的GeForce RTX系列GPU來加速LLM推論運算工作,讓用戶獲得自己專屬的LLM。
緊追在後的,與Intel、NVIDIA為長期競爭關係的AMD,也在3月份推出LLM Studio軟體,該軟體可以運用AMD CPU或GPU來加速執行本機端的LLM,一樣讓用戶實現自有專屬LLM的願望。
很明顯的,無論是NVIDIA Chat with RTX或是AMD LLM Studio,就是要刺激大眾購買新的、高階的CPU、GPU系統,正是基於此,所以AMD LLM Studio只支援新的AMD Ryzen AI的CPU或AMD Radeon RX 7000系列的GPU,其餘不行。
模型下載
此外,LLM Studio一起頭下載就要選擇對的版本,有運用CPU加速的LM Studio – Windows,或者是運用GPU加速的LM Studio – ROCm(至3月中旬時仍處於技術預覽版階段)。
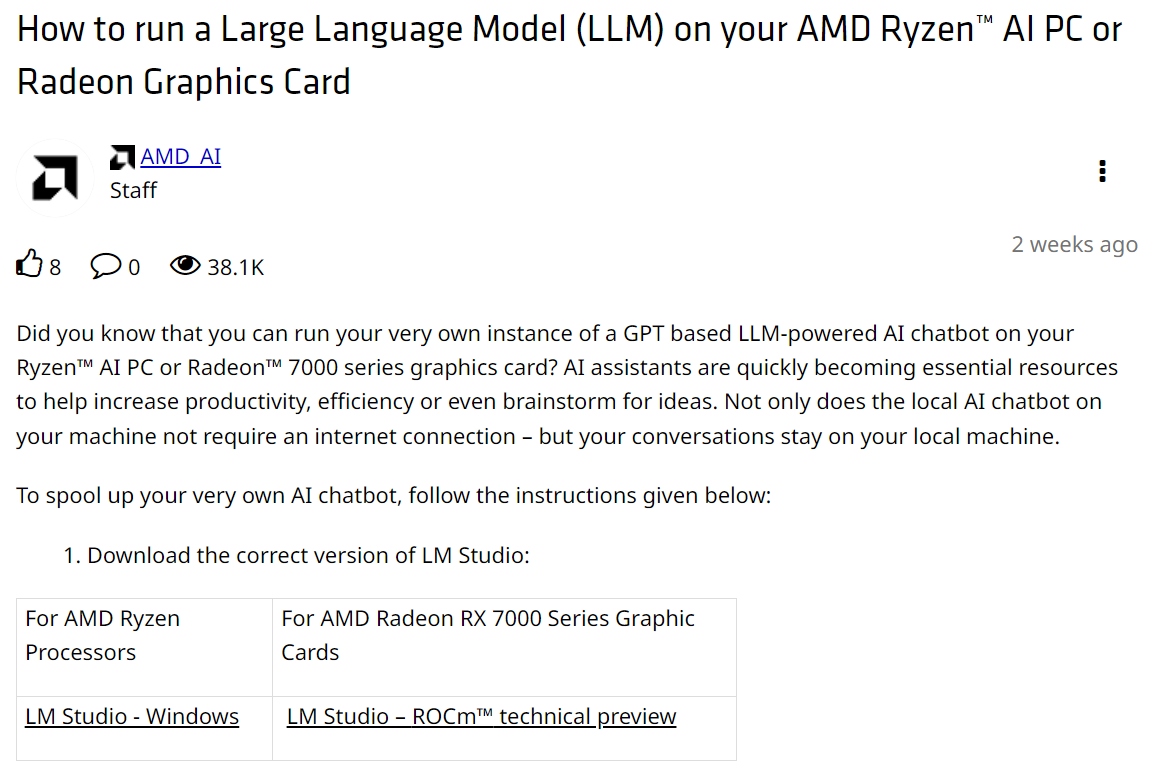
圖1 從AMD官網下載CPU版或GPU版LLM Studio(圖片來源:AMD)
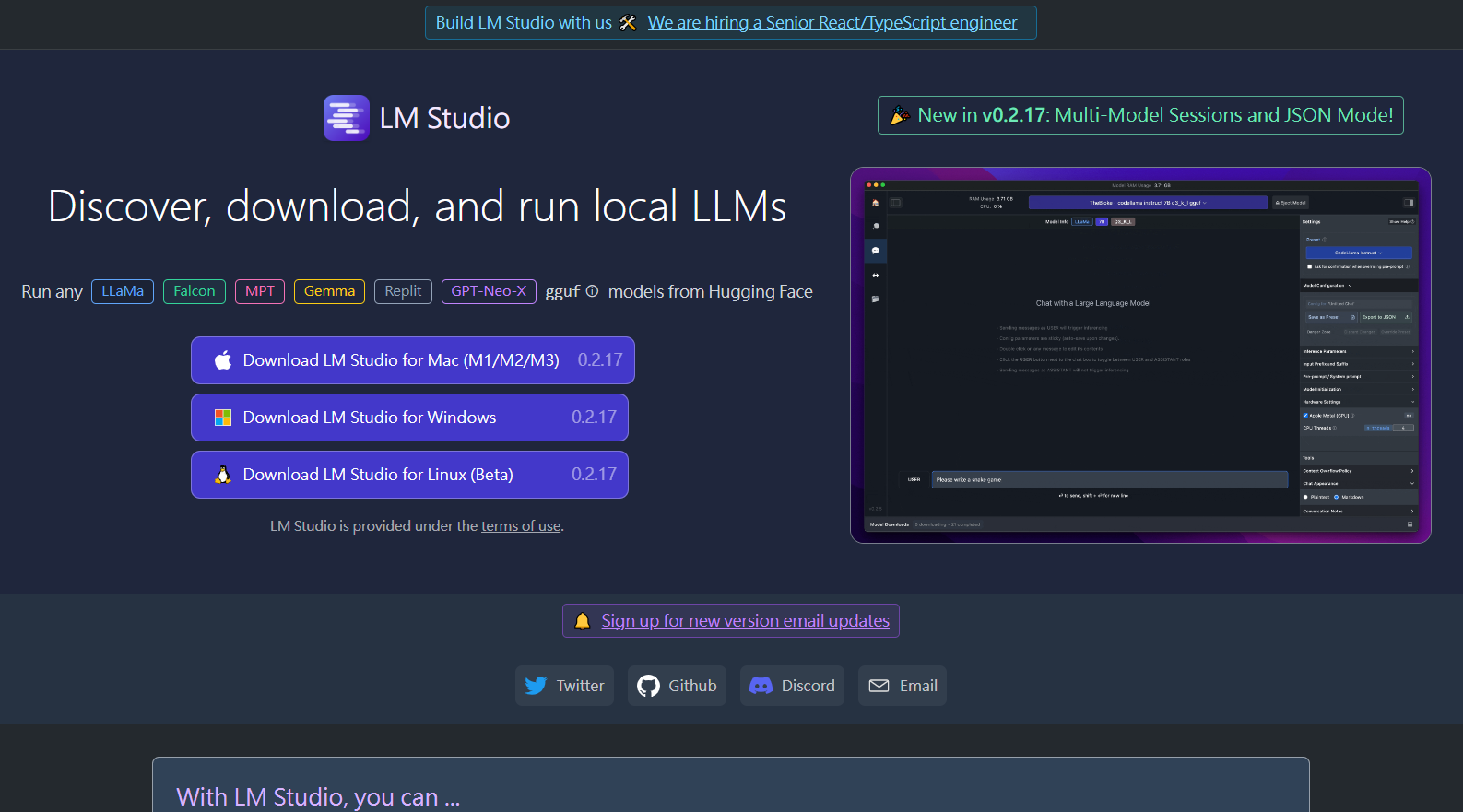
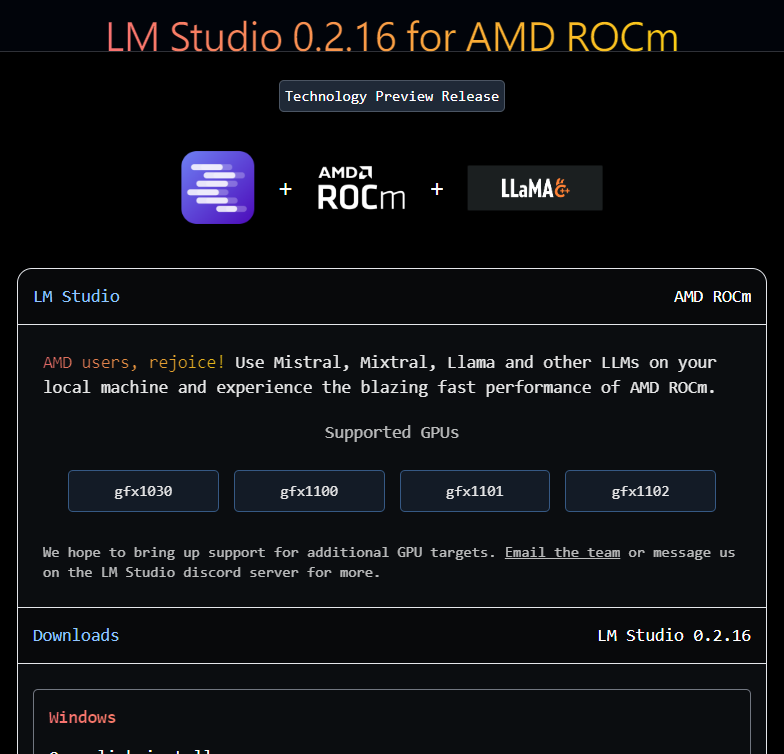
下載與安裝對應的版本後,接下來要下載LLM,目前是提供開放原碼的Llama 2 (也有人寫LLaMA)7B與Mistral 7B,從7B字樣就知道權重參數已經縮減到70億個,已經是減肥、輕量化的模型。
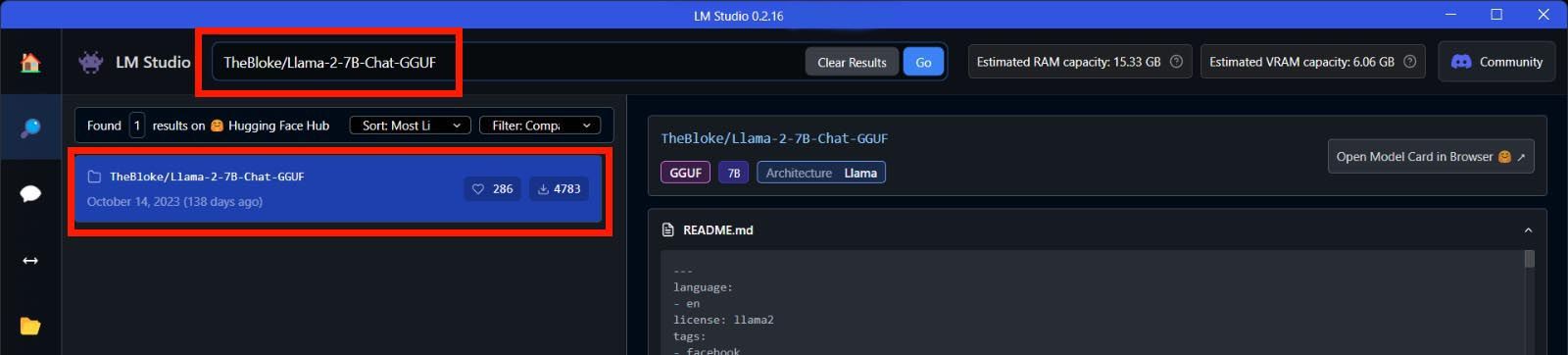
圖4 先進行搜尋,搜到Llama 2 7B模型(圖片來源:AMD)
模型選單與名稱上也有一些細節,例如Q4_K_M的Q4是指模型量化(Quantization)成4位元精度,而K_M或K_S則是對一半或全數的張量(tensor)進行指定配置。
然後要注意,不是所有模組都可以透過GPU來加速,所以還有附註文字「FULL GPU OFFLOAD POSSIBLE」與「PARTIAL GPU OFFLOAD POSSIBLE」,後者就是只有程度性透過GPU加速,前者則是盡可能都由GPU處理。
模型雖然已是輕量化,但依然動輒數GB容量,需要一些時間下載,已經準備足夠的電腦空間安裝,安裝後就可以用來對話聊天了。
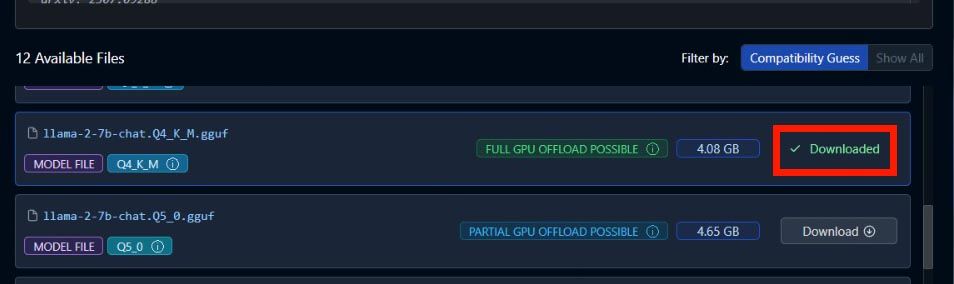
圖5 下載盡可能透過GPU加速的模型,容量4.08GB(圖片來源:AMD)
圖6 採行與ChatGPT相仿的問答聊天介面(圖片來源:AMD)
既然模型都在自己手上了,那自主掌握度就高了,把LLM Studio細部設定選項展開來,可以看到LLM Studio已經偵測到系統內的GPU是何種類型,然後也可以手動設定要運用多少GPU運算資源來加速LLM執行,可以全速投入,或者低投入,或者一半投入,或者選擇更細緻刻度的設定。
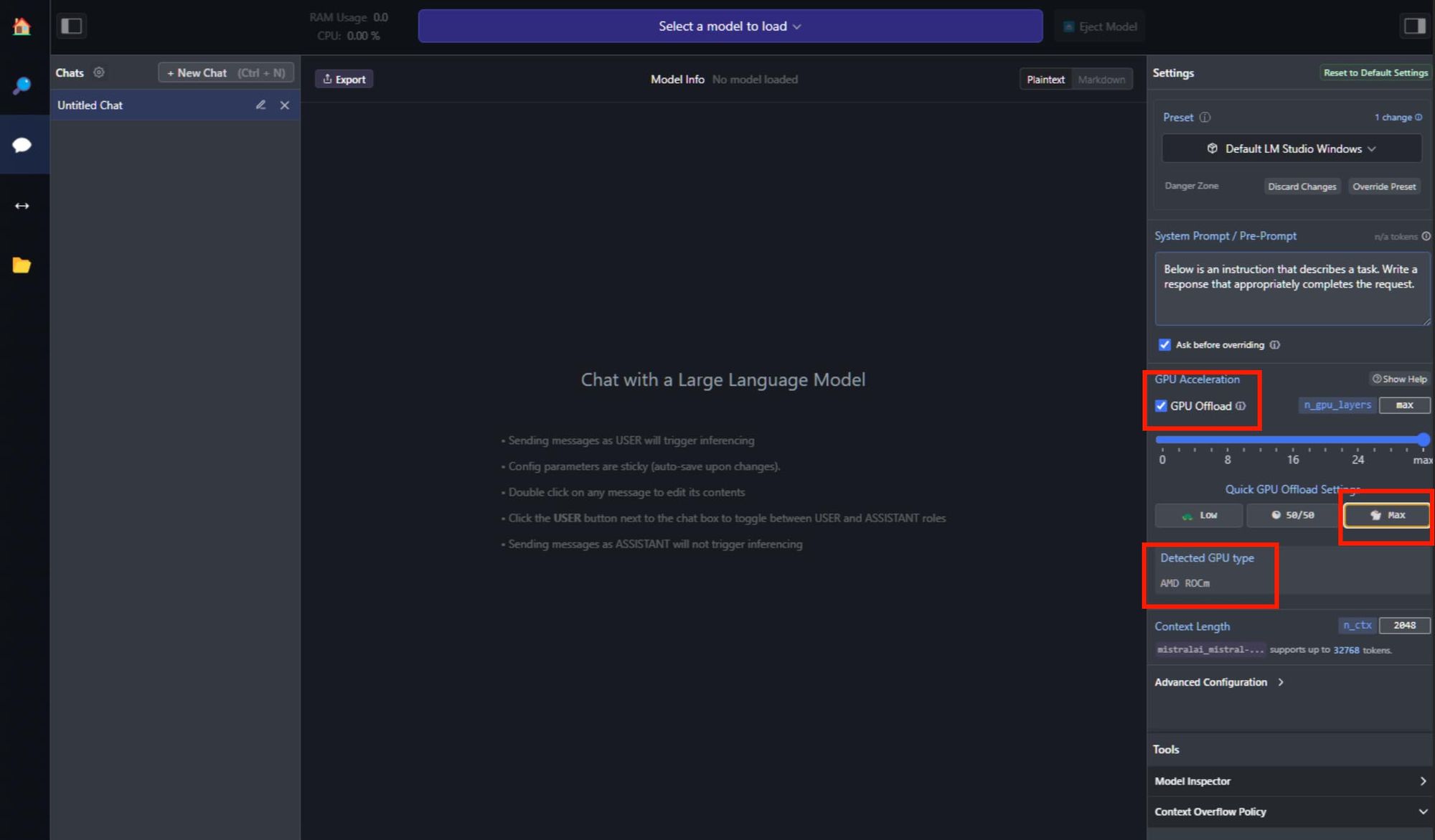
圖7 LLM Studio偵測到GPU,確實可支援加速,圖中選擇讓GPU全速投入LLM執行加速(圖片來源:AMD)
小結
最後要打一下預防針,畢竟LLM Studio目前僅為0.2版,離正式的1.0版尚遠,甚已標註「技術預覽」字樣,坦承完成度待加強,故先別苛責聊天回應效果,姑且嘗鮮體驗試試。
也由於LLM Studio明顯是刺激消費高階高規系統(筆者查了一下,7000系列顯示卡,入門的RX7600至少也要8,490元新台幣,頂款的RX7900則可以貴到3.6、3.8萬之譜),故只建議預算寬裕的創客先行體驗,多數人可以再等等,等待軟體版本更成熟,同時也等待高規硬體降價,或等待新版軟體可以放寬硬體支援等。
至於CPU、GPU對7B瘦身模型的加速程度如何?有興趣的創客可以試試看發完問話訊息後的回應時間,倘若超過15秒恐怕就失去實用性,或者也可以用Windows的「工作管理員」檢視一下,看看CPU、GPU有推論工作、沒推論工作時的尖峰運算差距?從中得到新體驗與樂趣。
(責任編輯:謝嘉洵。)

- 小孩才選擇!Arduino VENTUNO Q全都要 - 2026/03/26
- 樹莓派也能「養龍蝦」! - 2026/03/24
- Windows PC上安裝PicoClaw最基礎實務 - 2026/03/03
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!