作者:高煥堂
在本文裡,將從商店櫃檯的產品推薦應用(俗稱:CLIP櫃台招財貓)來說明:我們可以拿CLIP(Contrastive Language Image Pre-training,對比語言圖像預訓練)的原始程式碼,搭配商家自有產品圖像(Image)和圖像敘述文句(Text),來訓練出企業自用的CLIP小模型,同時也領會其幕後潛藏空間(Latent space)的運作及其效果。
茲複習一下CLIP的特性,它的目標是透過大量圖片及文字描述,建立兩者間的對應關係。其做法是利用ResNet50等來萃取圖像的特徵,並映射到潛藏空間(Latent space)。也就是將圖像編碼成為潛藏空間向量。同時,也利用Transformer萃取與圖像相配對文句的特徵,並將文句編碼成為潛藏空間向量。最後經由模型訓練來逐漸提高兩個向量的相似度。換句話說,CLIP能將圖像和文句映射到同一個潛藏空間,因此可以迅速計算圖像與文句的相似度。
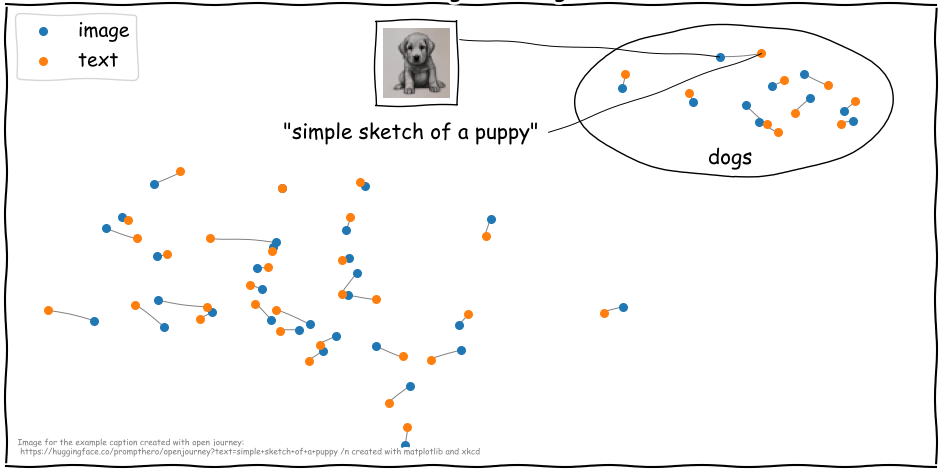
2D CLIP Embeddings of Image-Text Pairs(source)
換句話說,CLIP發揮了潛藏空間的魅力,藉之學習整個文句與其對應的圖像之間的關係。當我們在整個文句上訓練時,它可以學到更多的隱藏的東西,並在圖像和文句之間找到一些規律。因而,在當今主流的ChatGPT和Stable Diffusion大模型,其幕後都使用CLIP來提供「文找圖」和「圖找文」的雙向功能。
在一般企業裡,也常常需要上述的「文找圖」和「圖找文」雙向功能。
以<商店櫃檯AI產品推薦>為例
這是一項CLIP模型的應用案例。其應用於商家(如便利商店)櫃檯,進行瞬間即時商品推薦。典型的使用情境是:
1.客人在便利商店裡,挑選了一項產品,拿到櫃檯結帳,例如青島啤酒。
2.櫃檯(收銀台)正上方天花板設置一個Camera,立即拍下這張圖像:

3.櫃檯的收銀機(POS)系統把這張圖像,傳送給後臺的CLIP模型。
4.此時,CLIP模型立即找出「最接近(相似)」的產品圖像,如下:

5.CLIP模型回傳給POS系統,然後將這兩張相關圖像,顯示於櫃檯的雙向平板螢幕上,櫃檯人員和客人立即看到了,達到促銷的效益。

6.依不同客人結帳的產品,而立即找出最符合客人「偏好」的相關產品,達到即時推薦&行銷。再如,另一位客人購買產品是:

7.CLIP模型就立即找出「最接近(相似)」的相關「產品」的圖像:
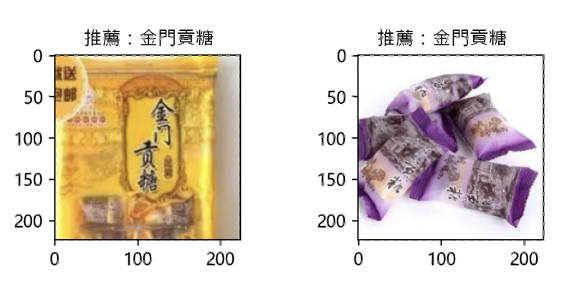
8.CLIP模型回傳給POS系統,然後將這兩張相關圖像,顯示於櫃檯的雙向平板螢幕上,櫃檯人員和客人立即看到了,達到促銷的效益。
上述的CLIP 模型是針對「產品」的。而一般POS POS機的人臉AI是針對「人」。我們可以擴大建立一個商品推薦AI模型,把兩者匯合起來,就實現了「比客人更懂客人」的極佳效果了。
實現方法
接下來,就來說明如何實現上述的「商店櫃檯AI產品推薦」模型開發。
Step-1、下載CLIP原始程式碼
下載網址是:https://github.com/moein-shariatnia/OpenAI-CLIP
Step-2、準備訓練圖像(Image)
在本範例裡,收集了該商店的產品圖像,共20張。放置在這文件夾裡(圖-1):
/ox_super_market_data/train/
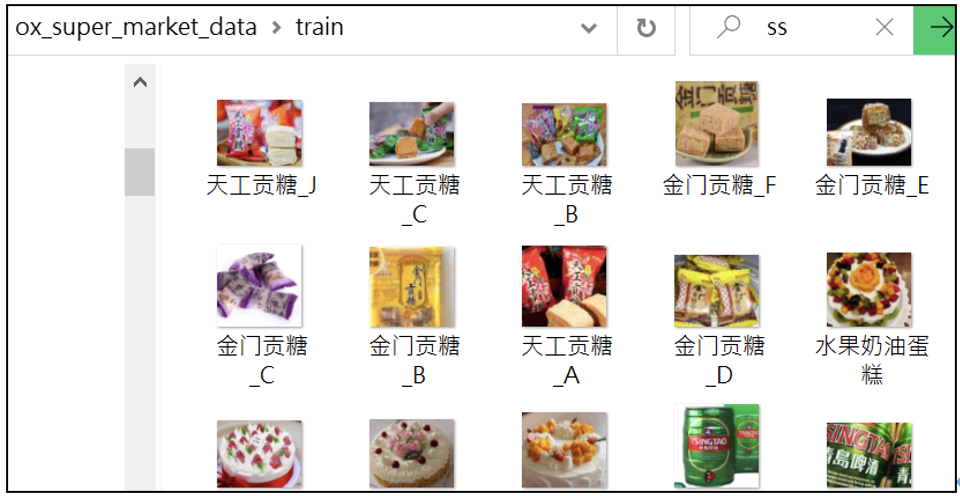
圖-1、訓練資料
Step-3、準備相對應的文本(Text)
在本範例裡,會自動讀取圖像的檔案名(File name)來做為圖像的相互對應的文本。例如,上圖-1裡的第0張圖,其檔名為:「天工貢糖_J」。於是,就擷取「天工貢糖」做為此圖像的相對應文本。如圖-2。
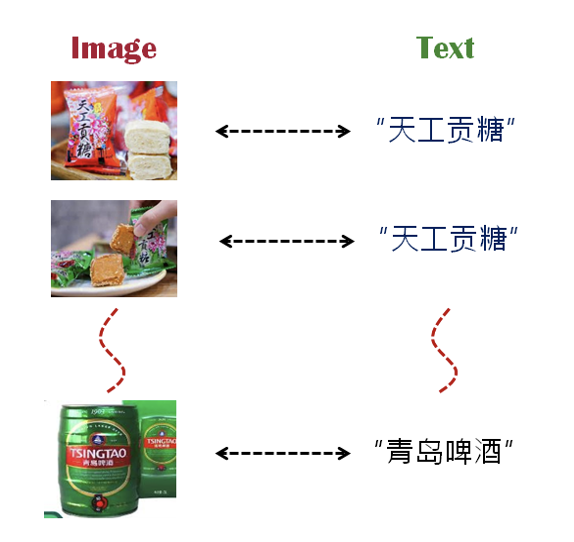
圖-2、圖與文的對應關係
Step-4、展開訓練(Training))
接著,就基於上述圖像資料、文本資料、以及它們之間的對應關係,來訓練CLIP模型。如果使用一般的GPU硬體設備來進行訓練,大約10分鐘即可訓練5000回合。然後匯出*.ckpt檔案。
Step-5、應用(一):圖找文
訓練好了CLIP模型,就拿一些圖像來檢測看看CLIP的「圖找文」功能。如下圖-3裡的圖像:
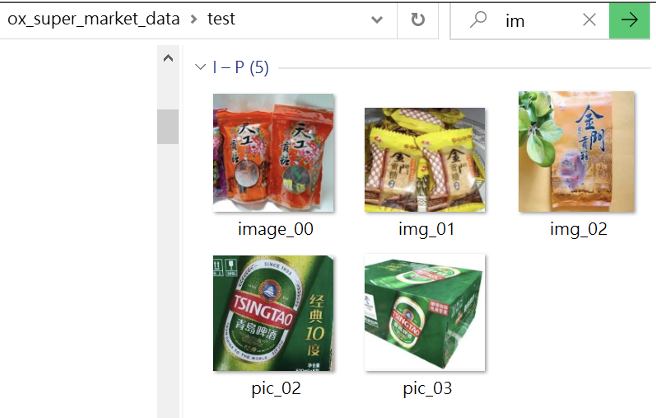
圖-3、測試圖像
在源碼裡也提供了CLIP的預測功能,就搭配我們自己訓練的模型(即*.ckpt檔案),來檢驗CLIP的預測能力。例如:輸入上圖-3裡的image_00.jpg圖像,CLIP立即找出其「最接近的」文本,如下:
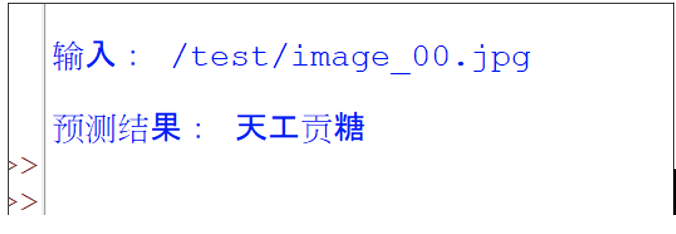
CLIP做了很棒的預測。
Step-6、應用(二):文找圖
接下來,就拿一段文本來檢測CLIP的「文找圖」功能。例如:輸入文句:「有沒有青島山水美啤酒呢?」CLIP找出其「最接近的」圖像,如下:

並且繪出該圖像:
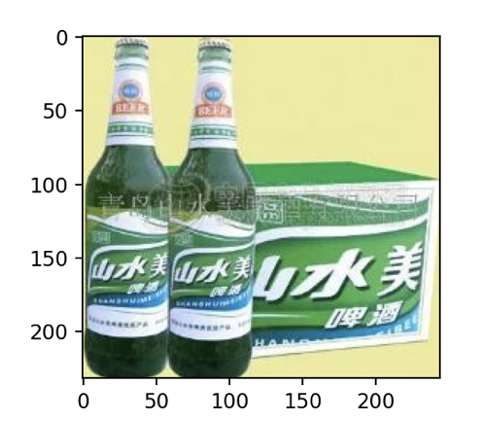
CLIP輸出了美好的結果。
Step-8、應用(三):圖找圖
再來,就拿一張圖檢測看看CLIP的「圖找圖」功能。例如:輸入一張圖,然後由CLIP立即找出其「最接近的」圖像,如下:
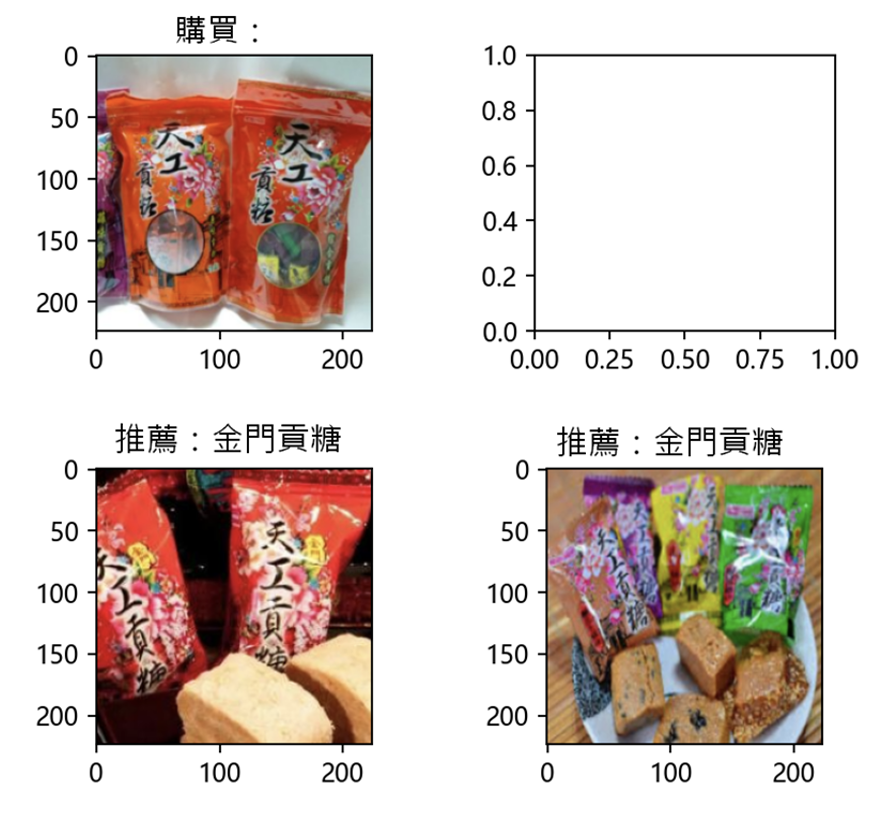
這CLIP的表現是很棒的。
結語
本文以大家很能理解的應用案例,來讓您體會CLIP幕後的作業,尤其是它將圖像特徵,以及文本特徵映射到潛藏空間,也就是將其編碼成為潛藏空間向量,並計算其相似度。最後,基於相似性來找出「最接近的」圖像或文本。

近5年來,從事於AI普及化教育工作,目前擔任銘傳大學AI課程、長庚智慧醫療研究所AI課程授課老師。也擔任永春國小、東園國小、立志中學、君毅中學、永春高中等學校的AI師資培育工作。
- LoRA微調三步驟:以大語言模型MT5為例 - 2024/05/02
- 為什麼Gemma採取Decoder-Only Transformer架構呢? - 2024/04/08
- 如何從0訓練企業自用Gemma模型 - 2024/04/03
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


