作者:歐敏銓
近來火熱的AIGC及LLM,正在各個領域延燒,其中一個值得開發者關注的議題,正是大型程式語言模型 – Code LLM。目前已有不少開發者運用ChatGPT來協助程式的撰寫與除錯,但還有幾個專門為程式設計和軟體開發而發起的LLM專案,例如Hugging Face推的StarCoderBase/StarCoder、Meta推的Code Llama,以及OpenAI推的Codex,未來將成為開發者重要的編碼助手。
不僅如此,一般使用者未來也可以用自己熟悉的自然語言來提出命令(英文~),這類專案的平台會試著編譯出程式碼,此舉化解了長久以來一般人無法透過「語言」與電腦溝通的鴻溝,讓「程式語言」與「自然語言」有機會打成一片,令人期待呢。
以下就來簡介一下幾個發展較到位的模型專案。
1. BigCode
 BigCode 是由 Hugging Face 和 ServiceNow 共同領導的開放科學合作項目,致力於開發大型程式語言模型(Code LLM),並推出了StarCoder 和StarCoderBase兩個模型,它們具有8K 上下文(context)長度、填充(infilling)功能和快速大批量的推理能力。
BigCode 是由 Hugging Face 和 ServiceNow 共同領導的開放科學合作項目,致力於開發大型程式語言模型(Code LLM),並推出了StarCoder 和StarCoderBase兩個模型,它們具有8K 上下文(context)長度、填充(infilling)功能和快速大批量的推理能力。
在2022年底,BigCode先釋出了一個僅有11億參數的高效能程式語言模型SantaCoder,可生成和填充Python、Java與JavaScript程式碼。SantaCoder模型雖小,但效能已經比起擁有67億參數的InCoder,以及27億參數的模型CodeGen-multi還要好。
StarCoderBase是150億參數的更大型程式碼生成模型,BigCode使用 GitHub 的授權資料來對StarCoder 和StarCoderBase進行訓練,這些資料包括 80 多種程式語言、Git Commits、GitHub issues和 Jupyter Notebook。其中StarCoderBase 使用 The Stack 的 1 兆個文字單位(Token)進行訓練,The Stack 是經過授權的 GitHub 儲存庫,具有檢查工具和選擇退出流程。BigCode再以35B Python token上對 StarCoderBase 進行了微調,從而創建了 StarCoder。
StarCoder模型的優點之一,是可以處理比其他大型語言模型更多的輸入,可以接受高達8,000個Token,而這將能支援更多樣的應用,像是經過一系列的對話指示,便可使StarCoder成為技術助理。而StarCoder也能勝任一般程式碼生成模型所能達成的任務,像是自動完成程式碼,遵循指令修改程式碼,以及用自然語言解釋程式碼片段等。
BigCode針對Code LLM 進行了全面評估,結果表明 StarCoderBase 優於 PaLM、LaMDA 和 LLaMA等開放 Code LLM,並且匹配或優於 OpenAI code-cushman-001 模型。此外,StarCoder 優於在 Python 上進行微調的所有模型,可以提示在 HumanEval 上達到 40\% pass@1,並且仍然保留其在其他程式語言上的效能。此外,BigCode採取了幾個重要步驟來實現安全的開放取用模型發布,包括改進的PII 編輯管道和新穎的歸因追蹤工具,並在更具商業可行性的開放式負責任AI 模型授權版本下公開提供StarCoder模型。評估結果如下表:
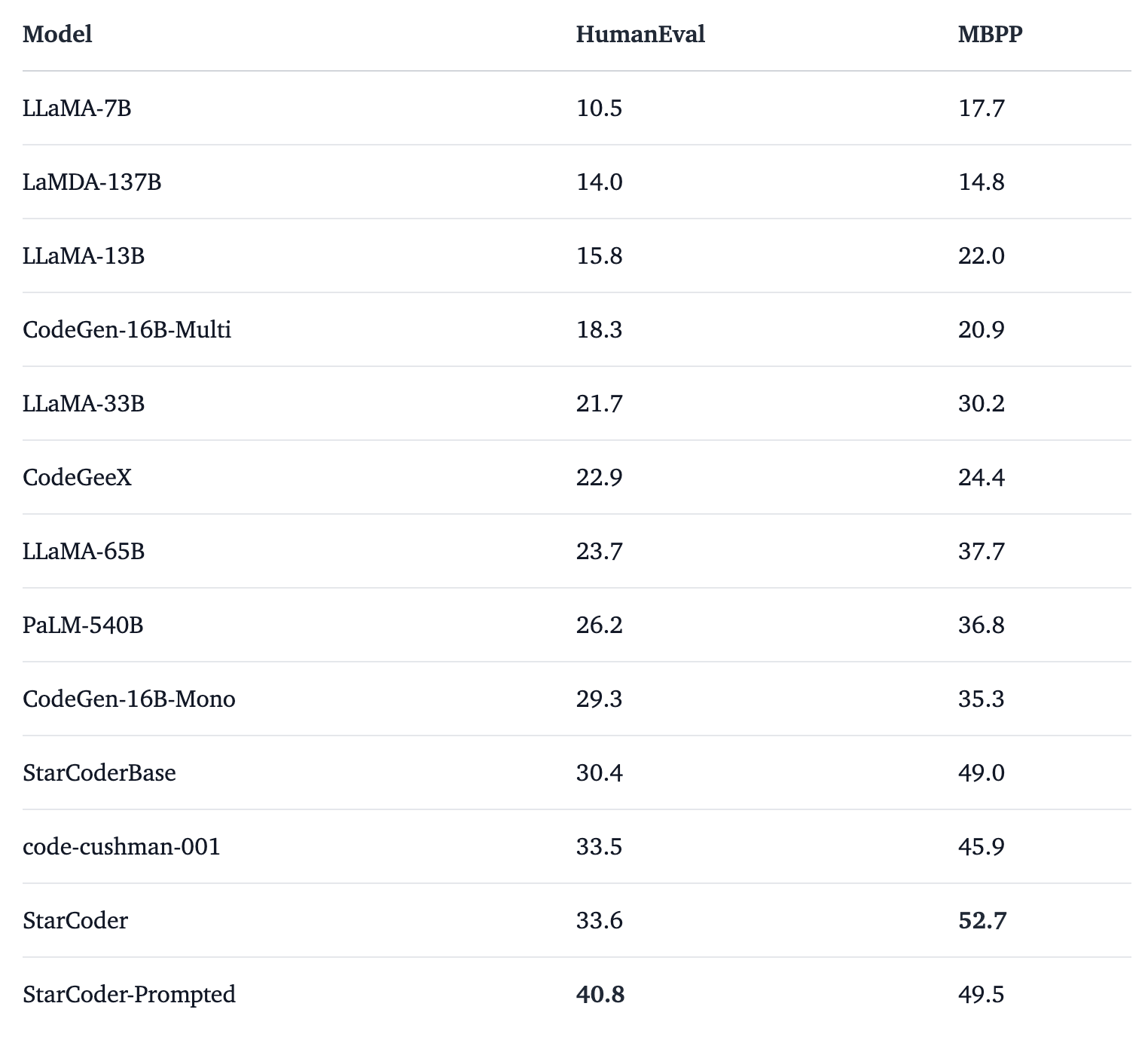
透過詳盡的評估,BigCode發現 StarCoder 除了有能力編寫程式碼外,也能夠充當技術助理並回答與程式設計相關的請求。
2. Code Llama

基於 Llama 2的Code Llama(資料來源)
Code Llama是一個基於 Llama 2 的大型程式碼語言模型系列,可使用文字提示產生程式碼,支援的語言包括 Python、C++、Java、PHP、TypeScript、JavaScript、C# 和 Bash。有興趣的開發者可以從Meta AI 網頁請求存取 Code Llama 。
Code Llama 免費用於研究和商業用途,目前發布了三種尺寸,分別具有 7B、13B 和 34B 參數。每個模型都使用 500B 程式碼tokens和程式碼相關資料進行訓練。7B 和 13B 基礎模型和指令模型經過中間填充 (fill-in-the-middle, FIM) 功能的訓練,可以將程式碼插入現有程式碼,這支援開箱即用的程式碼開發任務。
這三種模型可滿足不同的服務和延遲要求,例如,7B 模型在單一 GPU 上提供服務,而 34B 模型可返回最佳結果並提供更好的編碼幫助。Meta 對該工具的另外兩個變體進行了微調:Code Llama – Python 在 Python 程式碼的 100B 標記上進行了進一步微調;Code Llama – Instruct 進行了微調以理解自然語言指令。
HumanEval 測試顯示,未經過微調的CodeLlama-34B 和 CodeLlama-34B-Python 的通過率分別為48.8%和53.7%。而根據 phind 官方消息,研究團隊在Phind 內部數據集上對 CodeLlama-34B 和 CodeLlama-34B-Python 進行微調之後發現,這兩款模型微調之後,在 HumanEval 測試中的通過率達到67.6% ,CodeLlama-34B-Python 的通過率達到69.5% ,而 GPT-4在今年3月份的成績為67%。(資料來源)
3. OpenAI Codex
openai-codex
OpenAI Codex是為GitHub Copilot提供支援的模型,由OpenAI與GitHub合作創建的。它是 GPT-3 的後代,其訓練資料包含自然語言和來自公開來源的數十億行原始碼,包括公共 GitHub 儲存庫中的程式碼。OpenAI Codex 的能力最強的程式語言是 Python,但它也精通包括 JavaScript、Go、Perl、PHP、Ruby、Swift 和 TypeScript 甚至 Shell 在內的十多種程式語言。
小結
強大、好用的工具一直扮演著文明推手的角色,而軟體開發則在數位年代具有舉足輕重的影響力,如今因AI的進展有機會打破「自然語言」與「程式語言」的藩蘺,令人期待。不過,一般人想要跨入程式開發領域,仍需了解給Code LLM模型的出題技巧,包括想建構的問題架構,以及如何指示模型生成需求的程式碼(函式庫、API 或函數),才能發揮工具的強大之處。
》延伸閱讀:
StarCoder: A State-of-the-Art LLM for Code
Meta releases Code Llama LLM for coding
Personal Copilot: Train Your Own Coding Assistant
BigCode開放效能超越初代Copilot的程式碼生成模型Starcoder(iThome)

- 【產業觀察】Intel在VLA機器人市場的佈局與契機 - 2026/03/27
- AI如何讓機器人更有「人」味:跨越雙手協同鴻溝! - 2026/03/17
- 2026 Edge AI MCU技術趨勢與廠商方案現況比較 - 2026/03/12
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


