作者/圖片來源:CAVEDU 教育團隊
Jetson Inference範例是NVIDIA 提供給Jetson系列的邊緣裝置進行視覺影像識別的範例,主要的特色在於這些範例都特別強調以NVIDIA Jetson系列邊緣裝置內的GPU進行運算,在實測上也的確發揮了很好的影像識別效果,尤其在物件偵測(Object Detection)所使用的Detectnet範例更有效率的辨識效能,CAVEUD在本網站有詳細的安裝與測試教學文章(請參考連結)。
RealSense D435則是Intel推出的RealSense系列產品之一,這系列的產品主要是以輸出影像深度資訊(測距)的應用為主,RealSense D435透過光學測距的方式進行深度資訊的探測,在應用上有著不錯的探測效果,在CAVEDU 亦有相關的安裝與測試教學(請參考連結)。
影像物件偵測一直都是影像深度學習的重要應用之一,透過神經網路對於物件(Object)的種類進行辨識進而確認物件在影像中的直角座標位置,在辨識上僅能確認物件的影像方位,這樣的影像物件偵測由於缺少了物件與攝影機的相對距離,因此在更進一步的應用上便會受到一些侷限,例如:透過影像資訊控制機械手臂,自動夾取指定的物品、自駕車或無人飛行器精確的迴避障礙物或跟蹤控制。
因此本文將著重在物件與攝影機的相對距離應用在影像物件偵測的實作教學上,希望能夠透過這樣的實作教學讓每個使用者可以進一步的針對影像物件偵測進行測量距離,這次採用的微電腦平台是NVIDIA Jetson Nano 4GB嵌入式系統,與Intel的影像深度攝影機Realsense D435兩者進行整合,本次教學亦針對NVIDIA的GStreamer技術進行簡介,主要是因為NVIDIA的Jetson Inference相關應用,都是透過GStreamer進行影像資料的交換傳輸,透過GStreamer可以有效提升影像處理的效能。
Jetson Inference應用程式操作環境的安裝與設定
Jetson Inference程式操作環境的設定主要是會完成三個環境更新安裝與設定,分別是:
- Python程式的相依套件程式安裝(如:Pytroch等)
- Python程式的編譯與路徑參數設定
- 影像識別相關預訓練神經模型的安裝
有關Jetson Inference程式的安裝與設定,請參閱CAVEDU在本網站的網路教學文章進行安裝即可(請參考連結)。
CAVEDU的Jetson Inference教學文章(請參考連結)
本文所採用的主要的是detectnet這個範例應用為主,因此若使用者對於安裝空間有所斟酌的話,請優先完成這部分的安裝,請注意,本文建議盡可能將detectnet所需要用到的預訓練神經網路模型全部安裝,這樣可以避免未來在應用時產生補充安裝模型的問題。此外這裡的安裝會需要從網路下載大量程式與檔案,因此請務必確認網路傳輸環境在長時間運作下,能夠正常傳輸。
Jetson Inference的範例程式運作,主要是透過CUDA連結GPU的方式進行Tensor-RT的運算,也由於是透過GPU進行運算,在操作影像識別的神經網路運算時有著較佳的運作效能。透過GStreamer進行影像串流的處理,可以有效提升影像傳輸的效能,在Jetson Inference的神經網路運算時,也都是以GStreamer的方式進行影像資料的傳遞。
透過上述這兩方面的技術的整合,對於影像物件偵測是有非常重要的貢獻,根據實測在進行detectnet程式運作的時候,整體約莫會有25FPS的操作效能,這歸功於CUDA有效連結了GPU進行運算產生的效益。
intel Realsense D435深度影像應用程式操作環境的安裝與設定
Realsense相關應用程式操作環境的安裝與設定主要是針對以下三個事項進行設定,分別是:
- Python相依套件的安裝
- Realsense應用程式的編譯與路徑設定
- Realsense-viewer或Python程式的安裝
有關Realsense程式的安裝與設定,請參閱CAVEDU在本網站的網路教學文章進行安裝即可(請參考連結)。
CAVEDU的RealSense教學文章(請參考連結)
Realsense的影像資訊其格式必須經過numpy套件程式的轉換處理才能呈現即時影像,這部分的介紹將會在後續的介紹當中,透過片段程式的進行重點說明,Realsense在運作的時候基本上會有兩種不同內容的影像輸出,一個是標準RGB的影像輸出,另一個具有深度資訊的影像輸出,這兩個影像在應用時必須要注意「影像資訊對齊」,這主要的原因在於兩種影像在擷取的時候可能會有兩種不同的解析度的設定。在實際的硬體規格當中亦可以看出這兩種影像解析度的極限的確有所不同。
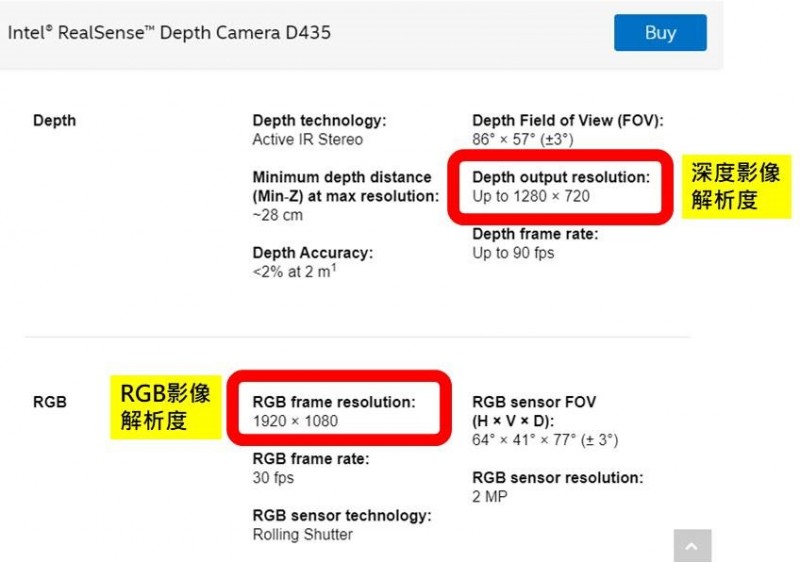
Intel Realsense D435原廠網站資料(請參考連結)
系統架構圖
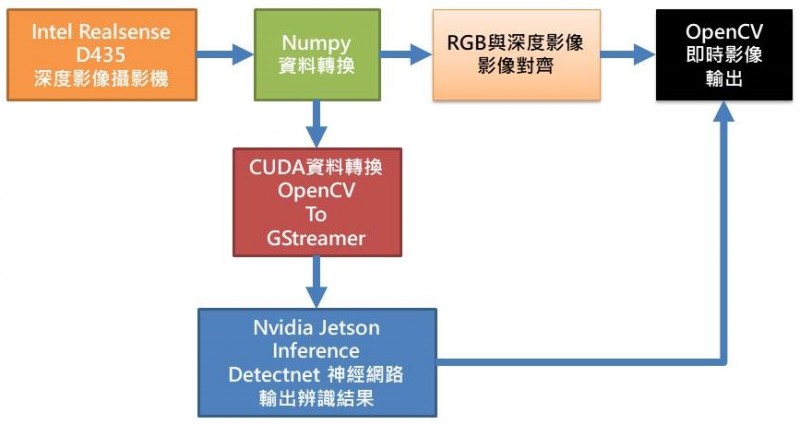
從上圖可知,Realsense D435要透過Numpy套件程式才能將影像資訊轉換成OpenCV格式進行後續的影像處理,如:繪邊界框、標註文字與即時影像顯示等,而要進行Jetson Inference的detectnet運算之前,亦必須先透過CUDA轉換資料將OpenCV格式轉換成GStreamer格式才能進行detectnet神經網路運算,之後再將detectnet辨識後的結果,如:邊界框位置資訊、物件種類名稱,加入至RGB影像訊息內容中,最後與深度影像資訊進行對齊,如此便可以OpenCV進行整合後的影像呈現。
程式設計說明
<匯入相關套件>
- Jetson Inference 相關套件
主要有inference、jetson.utils - Realsense相關套件
主要是pyrealsense2 - OpenCV相關套件
主要是cv2 - Numpy數值運算相關套件
主要是numpy
#!/usr/bin/python3
#
# Copyright (c) 2021, Cavedu. All rights reserved.
#
import jetson.inference
import jetson.utils
import argparse
import sys
import os
import cv2
import re
import numpy as np
import io
import time
import json
import random
import pyrealsense2 as rs
<程式外部參數設定>
- –network指定預訓練神經網路模型
- –threshold設定影像辨識閥值(多少以上才進行顯示)
- –width 設定影像寬度
- –height設定影像高度
# parse the command line
parser = argparse.ArgumentParser(description="Locate objects in a live camera stream using an object detection DNN.",
formatter_class=argparse.RawTextHelpFormatter, epilog=jetson.inference.detectNet.Usage() +
jetson.utils.logUsage())
parser.add_argument("--network", type=str, default="ssd-mobilenet-v2",
help="pre-trained model to load (see below for options)")
parser.add_argument("--threshold", type=float, default=0.5,
help="minimum detection threshold to use")
parser.add_argument("--width", type=int, default=640,
help="set width for image")
parser.add_argument("--height", type=int, default=480,
help="set height for image")
opt = parser.parse_known_args()[0]
設定jetson.inference的神經網路運算為detectnet,並且透過opt.network的外部參數進行設定預訓練神經網路模型。
# load the object detection network
net = jetson.inference.detectNet(opt.network, sys.argv, opt.threshold)
設定Realsense套件的起始條件,並且啟動Realsense套件程式。
# Configure depth and color streams
pipeline = rs.pipeline()
config = rs.config()
config.enable_stream(rs.stream.depth, opt.width, opt.height, rs.format.z16, 30)
config.enable_stream(rs.stream.color, opt.width, opt.height, rs.format.bgr8, 30)
# Start streaming
pipeline.start(config)
由於啟動本程式會進行大量運算,而使微電腦的核心產生高熱,因此透過本行程式啟動散熱風扇進行降溫。
os.system("sudo sh -c 'echo 128 > /sys/devices/pwm-fan/target_pwm'")
讀取Realsense D435影像內容並且透過Numpy將資料轉成OpenCV格式。
depth_image:深度影像資訊
show_img:BGR影像資訊
press_key = 0
while (press_key==0):
# Wait for a coherent pair of frames: depth and color
frames = pipeline.wait_for_frames()
depth_frame = frames.get_depth_frame()
color_frame = frames.get_color_frame()
if not depth_frame or not color_frame:
continue
# Convert images to numpy arrays
depth_image = np.asanyarray(depth_frame.get_data())
show_img = np.asanyarray(color_frame.get_data())
透過CUDA進行OpenCV的BGR影像格式轉換,並且將影像格式調整適用於神經網路運算的GStreamer格式(img)。
# detect objects in the image (with overlay)
detections = net.Detect(img)
取得所有detections中所有已辨識出來的物件種類與位置資訊。
box_XXXXX:邊界框座標
score:辨識信心分數
label_name:物件種類名稱
for num in range(len(detections)) :
score = round(detections[num].Confidence,2)
box_top=int(detections[num].Top)
box_left=int(detections[num].Left)
box_bottom=int(detections[num].Bottom)
box_right=int(detections[num].Right)
box_center=detections[num].Center
label_name = net.GetClassDesc(detections[num].ClassID)
透過OpenCV進行每個被辨識出來的物件其邊界框繪製、中心準線繪製與標註辨識結果內容文字。
point_distance=0.0
for i in range (10):
point_distance = point_distance + depth_frame.get_distance(int(box_center[0]),int(box_center[1]))
point_distance = np.round(point_distance / 10, 3)
distance_text = str(point_distance) + 'm'
cv2.rectangle(show_img,(box_left,box_top),(box_right,box_bottom),(255,0,0),2)
cv2.line(show_img,
(int(box_center[0])-10, int(box_center[1])),
(int(box_center[0]+10), int(box_center[1])),
(0, 255, 255), 3)
cv2.line(show_img,
(int(box_center[0]), int(box_center[1]-10)),
(int(box_center[0]), int(box_center[1]+10)),
(0, 255, 255), 3)
cv2.putText(show_img,
label_name + ' ' + distance_text,
(box_left+5,box_top+20),cv2.FONT_HERSHEY_SIMPLEX,0.4,
(0,255,255),1,cv2.LINE_AA)
透過net.GetNetworkFPS擷取神經網路辨識的FPS值,並且透過OpenCV在即時影像畫面中標註其FPS數值內容。
cv2.putText(show_img,
"{:.0f} FPS".format(net.GetNetworkFPS()),
(int(opt.width*0.8), int(opt.height*0.1)),
cv2.FONT_HERSHEY_SIMPLEX,1,
(0,255,255),2,cv2.LINE_AA)
透過OpenCV的resize函數進行顯示畫面的調整,並且進行即時影像的顯示。
display = cv2.resize(show_img,(int(opt.width*1.5),int(opt.height*1.5)))
cv2.imshow('Detecting...',display)
keyValue=cv2.waitKey(1)
if keyValue & 0xFF == ord('q'):
press_key=1
關閉即時影像畫面,並且結束Realsense的串流影像傳送。
# 關閉所有 OpenCV 視窗
cv2.destroyAllWindows()
pipeline.stop()
程式執行方式
1.可透過MobaXterm以SSH方式連線進入Jetson Nano作業系統操作終端機,或是直接以HDMI螢幕、USB鍵盤滑鼠直接操作亦可。
2.操作本文測試程式之前,請務必要先將Jetson Inference (請參考連結)與Realsense(請參考連結),兩個相關程式安裝完成,缺一不可。
3.進入終端機指定資料夾中(本文為Realsense_Jetson_Inference)
cd ~
cd Realsense_Jetson_Inference

4.請確定測試程式存於本資料夾中,並請執行以下指令(預設為ssd-mobilenet-v2模型):
python3 detectnet_realsense.py

執行結果如下:

5.或指定其他預訓練神經網路模型,請執行以下指令(本文例為pednet模型):
python3 detectnet_realsense.py --network=pednet


6.有關其他預訓練模型的載入請參考Jetson Inference範例程式安裝流程(請參考連結)。
完整程式
請點選連結以開啟完整程式內容。
相關文章:
- 在NVIDIA Jetson nano 上執行深度學習範例:影像辨識、物件偵測、影像分割(請參考連結)
- Intel 深度影像攝影機應用- 在NVIDIA Jetson Nano上使用RealSense D435(請參考連結)
- 【一分鐘小學堂系列彙整】Intel RealSense D435i x Jetson Nano(請參考連結)
- Jetson Nano搭配RealSenseD435-人臉辨識及距離偵測(請參考連結)
- 【OpenVINO x UP Squared x RealSense 深度攝影機】 使用深度影像實做道路避障偵測(請參考連結)
*本文由RS components 贊助發表,轉載自DesignSpark部落格原文連結(本篇文章完整範例程式請至原文下載)
(本文經CAVEDU同意轉載,原文連結;責任編輯:謝涵如)

- 【CAVEDU講堂】micro:bit V2使用TCS34725顏色感測器模組方法 - 2025/06/27
- 【CAVEDU講堂】NVIDIA Jetson AI Lab 大解密!範例與系統需求介紹 - 2024/10/08
- 【CAVEDU講堂】Google DeepMind使用大語言模型LLM提示詞來產生你的機器人操作程式碼 - 2024/07/30
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


