作者:賴桑
AI 一定要會寫 Python 程式嗎?其實不然,如果沒有太複雜,其實 Excel 就能幫忙,這集就教大家用 Excel 來操作一些簡單的例子吧!
之前幾次去講課,有人問我:「我們公司需要有 AI ,但目前很多人不太會寫 Python 程式,只能等學會 Python 才可以做 AI 嗎?」
答案:「當然不必。」事實上手邊工具能用就用,也是個不錯的選擇,如果你的問題不算太複雜,其實 Excel 說不定都可以幫忙,所以這次我們就試著用 Excel 來做一些簡單案例看看吧!
迴歸 (Regression)、分類( Classification) 與叢集( Clustering)
為什麼講這東西?很多人可能這樣問。其實,機器學習的範疇,依據使用者本身介入與否,大略分成兩大類型:監督式、非監督式。
所謂監督式,就是人已經知道答案是甚麼,一切依據人的標準來認定,還記不記得我們前一篇文有提到,機器學習的程式設計的輸入是資料跟答案,然後輸出的是規則,指的就是教電腦根據我們的想法去認定之後出現的目標,是不是符合規則而已。而迴歸、分類這兩種就屬監督式學習中,最常被歸納出來的解答方針。
所以無論是影像、聲音、語言文字…等,對電腦來說仍只是一大堆數值組合而已,電腦只會根據每次不同的輸入,比照我們提供標示出來的答案(就是我們想要的目標,術語叫 Label ),這些數據根據演算法會產生出指定的輸出數據,也就是我們前面講 CNN 時提過的「特徵」;我們不斷地輸入給電腦,然後電腦就跟已知的特徵比對,看相吻合的程度到多少,也就是監督式學習的精神。
那非監督式又是怎麼回事?其實又是個商業手法,資料量很大的時候,用人力來處理當然不划算,但如果我們人類提供大略準則,讓電腦自己根據這些準則,把資料整理出來並且提列出各項資料之間有無相關性呢?這就是叢集的想法。
回顧「迴歸」歷史緣由
舉些簡單的例子,讓大家一次想得到實際案例,先從迴歸開始。我們先了解一下迴歸到底指的是什麼,記得:要學一樣東西,先從它的歷史緣由來查,比較快又有效。
「迴歸」這個名詞,其實是英國人高爾頓爵士 Sir Francis Galton 發明的,高爾頓爵士是優生學的熱衷者,更在 1869 年寫了「遺傳的天才」( Hereditary Genius ) 這個著作,高爾頓爵士主張:人類的才能是能夠透過遺傳延續的。
然而 1877 年時高爾頓爵士開始研究遺傳的問題,發現小孩的確會接受雙親的遺傳使得某些特徵(好比高矮、聰明等等),可是這些遺傳的現象並不會一直延續,而是會逐漸回到人類社會的平均值,於是乎就提出了「迴歸到平均值」這個說法。這個雖然跟統計學課堂上所知道的迴歸意思不太一樣,不過,的確是迴歸一詞開始被運用的起源。
那麼到底迴歸一詞是什麼意思?說白話就是:「找出一條最能夠代表所觀測資料的線(其實就是個函數,一個算式就對了),接著用這條線(算式)代表變數之間的關係。問題在於:這條線呢…可不一定像是各位心裡想的又平又直,事實上如果有像我這樣讀電機電子背景的大大一定記得,所有電子元件的規格書,都只有保證在某些測試條件下,那些線才會又平又直,假如不是符合測試條件嘛… 就不太一定了。
簡單案例
好比說,一個氣體流量感測器好了,這個氣體流量感測器,根據實際測量氣體流量與輸出電壓的變化結果,可以做成一張這樣的表:
| 電壓(V) | 流量(cc) |
| 1.99 | 100 |
| 2.66 | 300 |
| 3.19 | 500 |
| 3.63 | 700 |
接著用 Excel 就能畫出這樣的圖,其中藍色的點,就是表中的數據,虛線的就是線性迴歸的線,那線性迴歸公式 y = 363.7x – 642.92 就會畫出線用的:
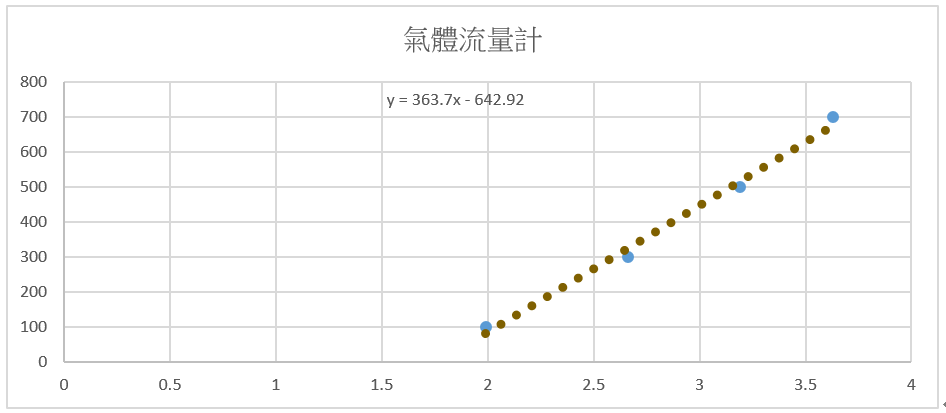
藍色的點是表中的數據,虛線的則是線性迴歸的線(圖片來源:賴桑提供)
這樣有甚麼好處?你沒注意到,我們只有四組數據嗎?而且流量間的差異還高達 200cc ,假如我要知道 15.5cc 的電壓是多少,根據表裡面的內容,怎麼查得出來?這就是真實情況,因為這些組數據都是實數 R ,無法完全提列出來,假如用這樣的方式,把電壓 V (就是橫軸的 X ),帶入算式求出流量 cc (就是縱軸的 Y ),那是不是簡便多了?
可是…實際上的線段,有剛好這麼簡單嗎?當然沒有,只是舉個簡單案例,而且誰規定一個算式只有兩個項目 X 和 Y ?可以透過以下方式獲得更精準的估算,這些也是目前業界用的:
1. 多次方程式趨近 X 最高不只一次方,不過業界會為了要讓嵌入式系統不要太高檔,通常不會超過三次方
2. 線性插值法,就是中學數學的內插、外插兩種而已
3. 把曲線分成好幾段小段的,然後每一段用一個直線方程式去迴歸
分類與叢集
分類更簡單~例如去超市買東西,分為生鮮、蔬果、海鮮、肉品…那就是整理的一種方法。那叢集呢?這裡回想到一個都市傳說…「啤酒與尿布」。
相傳,全球最大連鎖超市 Walmart 打算整理賣場的擺放櫥櫃,讓客人容易找到想要買的東西,這樣就可以提升在 Walmart 中消費的金額—人類其實不知道。於是乎,透過分析銷售的歷史資料,發現買尿布的顧客,有一定的比例也會買啤酒,所以就把啤酒跟尿布放在隔壁櫃子,果不其然尿布、啤酒兩項商品的購買數量都上漲了→從既有的資料跑程式去套出關聯性。
事實上,這後來被證實是以訛傳訛,不過呢,這個都市傳說倒是真讓大家對於 AI 眼睛為之一亮;那…程式上怎麼做到的?別把問題想太難,樞紐分析表, Excel 就可以做,還有教學影片跟範例。
不過前提是你的資料量不能太大,不然就不保證電腦會不會跟你搞罷工了。看了影片應該很有感了吧?只要人一開始對電腦下達「策略」,那電腦就會從資料裡面把符合的給「整理」出來。如果有人跟我一樣, 20 多年前修過資訊資工的課程,應該不難回想起 Data mining 這門課了吧!
樞紐分析表教學影片:
樞紐分析表範例資料:https://goo.gl/AeYgKu
小結
有仔細看這系列教學文的人,應該已經注意到了,其實真正說來,這些 NN 的功用,主要就在做迴歸、分類兩項,這是因為目前市場上,大部分還是希望電腦可以根據我們人類的想法去做我們要的事情,因此絕大多數都是監督式學習。
下一章開始,我們會帶著大家去認識一些 AI 目前市場上常聽到、常用的架構或工具,這樣拿 Python 寫一些程式時,就容易理解了。
(責任編輯:楊子嫻)

- 【開箱評測】用Mbed上手開發DSI 2599開發板 - 2020/08/03
- 【OpenVINO™教學】自製麵包影像辨識POS機的應用 - 2019/12/24
- 【邊緣運算】OpenVINO好夥伴 — athena A1 Kit x86單板 - 2019/11/18
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


