MakerPRO活動列表

- This event has passed.
邊緣系統VLM視覺理解推論實作工作坊

在當前人工智慧市場的多模態技術浪潮中,VLM模型因其整合視覺與語言的能力而備受矚目,被視為是下一波將落地的當紅技術與應用。
VLM 是結合語言模型的一種多模態(Multimodal)模型,為了讓 VLM 能夠處理影像,它通常會使用 ViT(Vision Transformer) 或 CNN 作為影像特徵提取器,然後與語言模型(如 Transformer 或 LLM)結合,讓 AI 能夠理解影像與文字的關聯,適用於更廣泛的 AI 應用,如 AI 助理、圖像描述等,其中OpenAI提出的GPT-4V即是代表性的VLM應用。
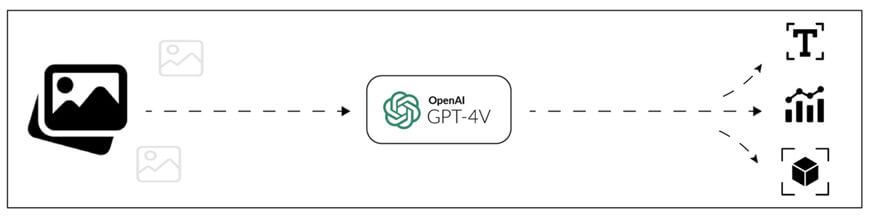
(圖片來源)
本工作坊將由尤濬哲博士主講,帶領您快速掌握以下重要內容:
1. 掌握AI最新主流:VLM是未來趨勢
在LLM爆發後,多模態AI成為下一波熱潮,尤其是結合視覺與語言的 VLM 正快速應用於自動監控、智慧工安、交通管理等場域。本工作坊帶你直接切入「影像 → 意義」的AI新世代,跳脫傳統影像辨識,搶先掌握視覺理解的技術紅利。
2. 動手實作!邊緣設備實戰操作不是紙上談兵
不只概念講解,課程還會實際演示如何在Google Colab上實測自己的VLM系統,並搭配 Llama 3.2 + Ollama + VILA 1.5 等業界主流工具。這是業界難得公開的技術操作流程,讓你從「看會」變成「做得出來」,實力直升!
》Llama 3.2: 這是 Meta 推出的LLM系列之一,它首次整合了多模態(Multimodal)能力,能同時處理文字與圖像輸入。這一版本針對行動裝置與邊緣運算進行了優化,提供多種模型尺寸,適用於從終端設備到雲端的各種應用場景。
》Ollama:Ollama 是一款開源的本地大型語言模型(LLM)運行框架,旨在簡化在本地環境中運行和管理大型語言模型的過程。它支援多種開源的大型語言模型,如 Llama 3、Phi 3、Mistral、Gemma 等,並且可以在 macOS、Linux 和 Windows 平台上運行。
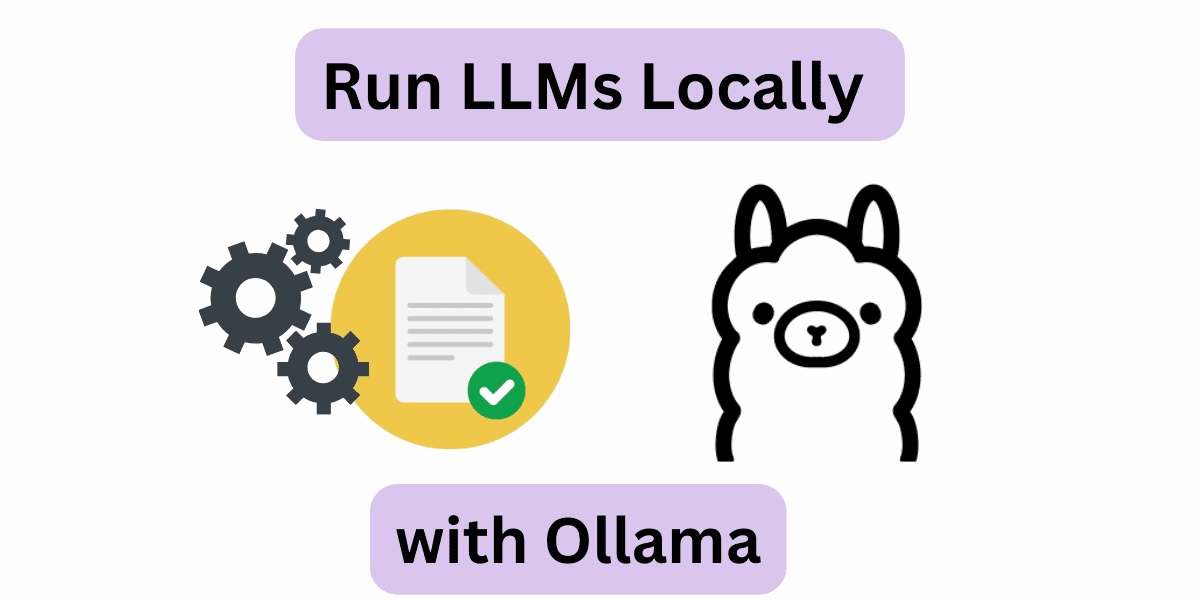
(圖片來源)
》VILA 1.5 :VILA 1.5 是一種針對多模態任務(Multimodal Tasks)優化的大型視覺語言模型(VLM, Vision-Language Model),由微軟研究院(Microsoft Research)開發,屬於 VILA 系列的升級版。
3. 實務導向,3大應用場景一次學會
工地安全、道路交通、員工工作狀態——這三大應用不僅實用,更代表著VLM在真實場景的落地實力。講師將帶你走過每一個案例,從資料輸入到推論結果,再到系統效能優化,真正做到理論與實務並重。

課程架構
1. VLM:從YOLO到ViT:
- 比較ViT與YOLO模型的不同,探討其技術發展與應用範疇。
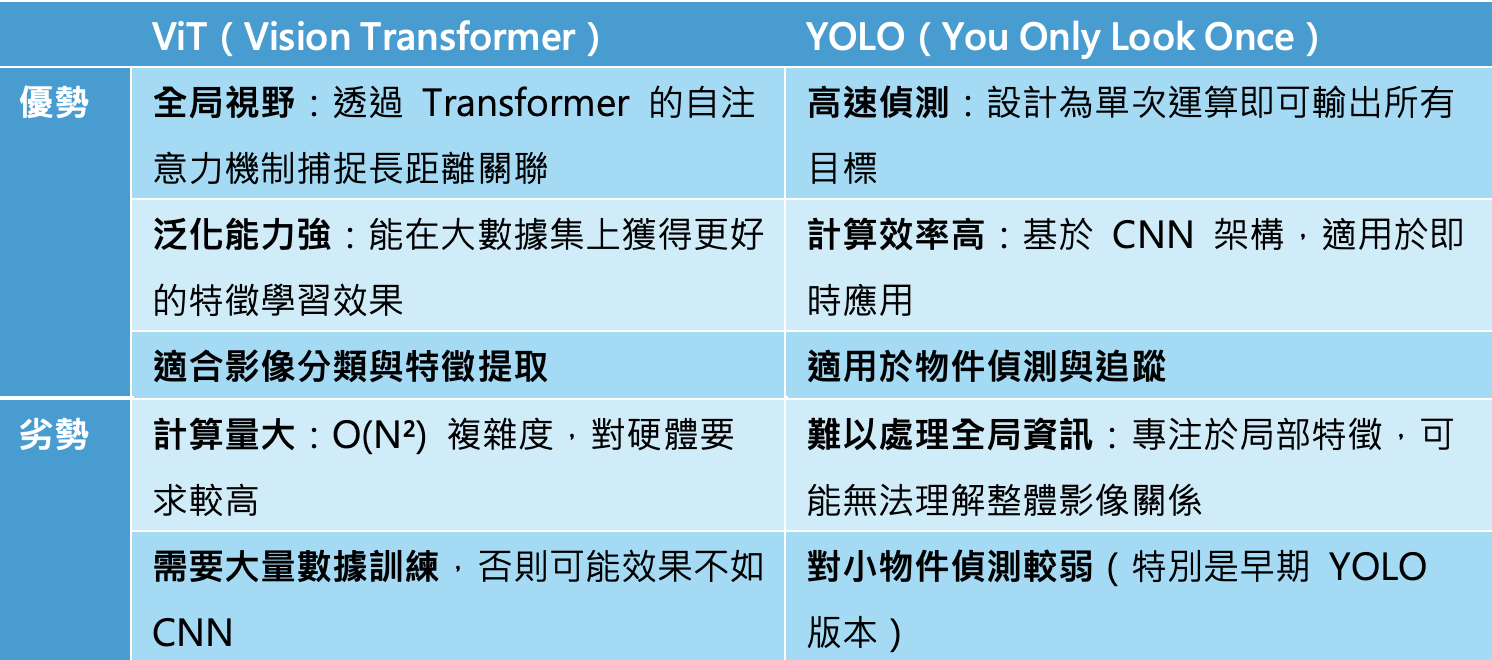
(圖片來源)
2. 架構VLM邊緣運算環境:
- 軟體環境概述:Llama 3.2、Ollama和VILA 1.5的整合與配置。
- 硬體環境介紹:介紹如何在Jetson Orin Nano Super及Google Colab上建置測試環境。
3. VLM應用實例與系統優化:
- 案例分享:工地安全監控、道路交通管理與員工工作狀態監測。

(圖片來源)
- 優化策略:提升系統效能和準確度的技術手段和實踐方法。
》延伸閱讀:
舊瓶裝新酒還是新瓶裝舊酒?Jetson Orin Super效能實測
課程資訊
► 主辦單位:MakerPRO
► 上課方式:Google Meet直播
► 時間:2025年5月14日(三) 14:00-16:20 (13:45開始報到)
► 收費方式:NTD 500元
► 聯絡方式:service@makerpro.cc;02-23679308 楊小姐
► 注意事項:報名成功後會發ACCUPASS e-mail通知,活動前MakerPRO也會發e-mail通知,請留意並準時上線
► 請於報名表中正確填寫二聯或三聯式發票資料,以便會後提供發票。
【講者介紹】
尤濬哲(夜市小霸王)

創辦「夜市小霸王」公司,專為對物聯網有興趣、零經驗的開發學習者而生的入門級AIoT教學,輕鬆開啟物聯網的大門。
曾任大學助理教授/專欄作家/知名部落客,以及點點滴滴科技研發總監等身份,專長包括人工智慧、多媒體互動(Unity)、智慧互動裝置(APP、Arduino)、虛擬實境與擴增實境互動、IoT 實做開發。
學歷:中山大學資訊管理研究所 博士