下世代的人形機器人需要具備多功能的身體與智慧的大腦,要讓機器人能夠理解新情境、穩定應對現實世界中的多變性,並且能迅速學習新任務,就必須訓練一個建立在大量多樣化資料上的機器人基礎模型。NVIDIA提出了一個為人形機器人設計的開放式基礎模型: GR00T N1。
採雙系統架構 #
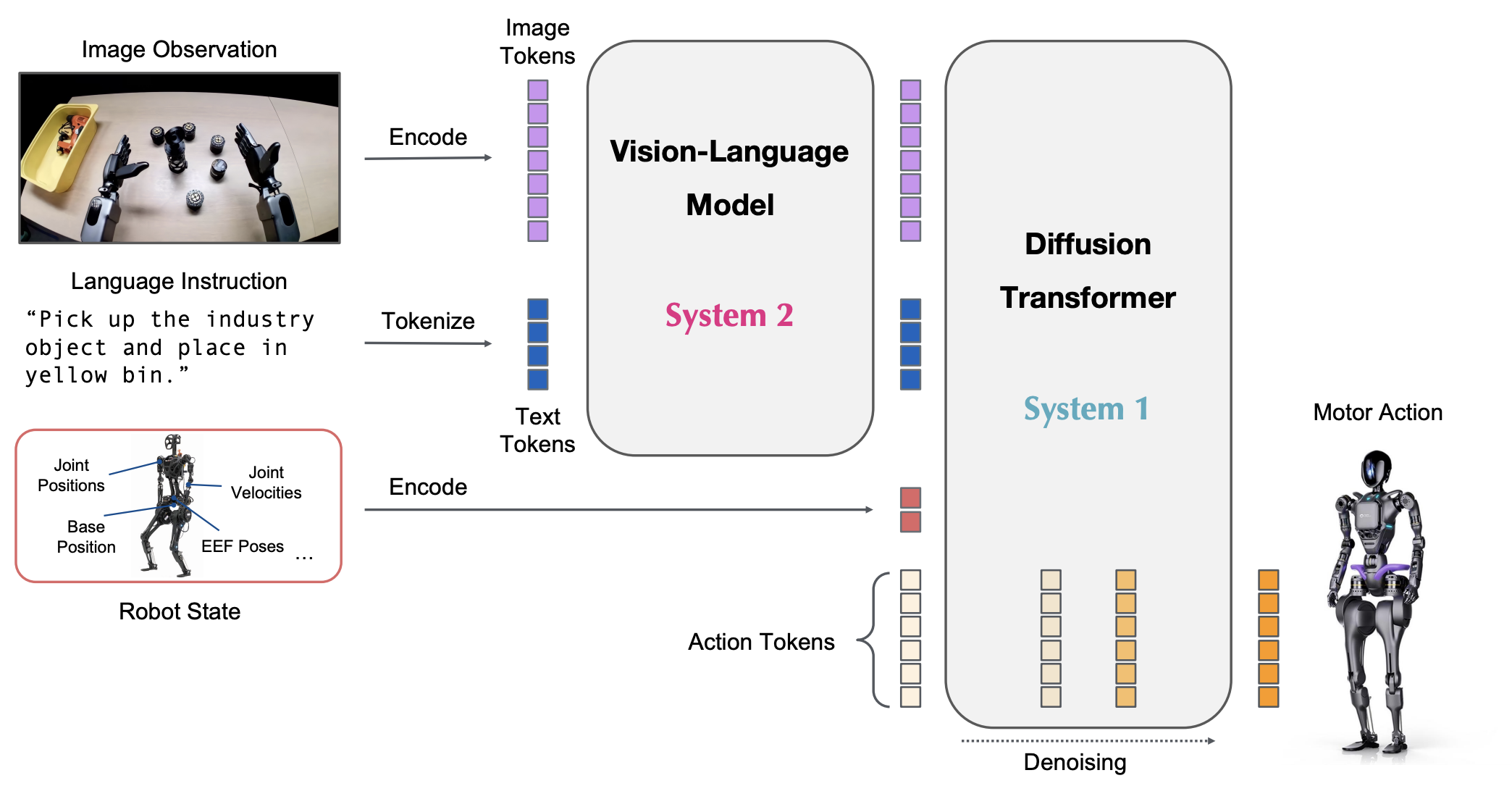
GR00T N1 是一個結合視覺、語言與動作(VLA)的模型,採用受到人類認知處理啟發的雙系統架構:
• System 2:
System 2推理模組是一個預先訓練的視覺語言模型 (NVIDIA Eagle-2 VLM),在 NVIDIA L40 GPU 上以 10Hz 的頻率運作。它處理機器人的視覺感知和語言指令來解釋環境並理解任務目標。
• System 1:
理解任務目標後,經過動作流匹配訓練的擴散變換器作為系統 1 動作模組。它交叉關注 VLM 輸出令牌,並採用特定實施例的編碼器和解碼器來處理運動產生的可變狀態和動作維度。它以更高的頻率(120Hz)產生閉環馬達動作。
System 1 和System 2 模組均基於 Transformer 的神經網絡來實現,在訓練期間緊密耦合並聯合優化,以促進推理和驅動之間的協調,技術架構見下圖:
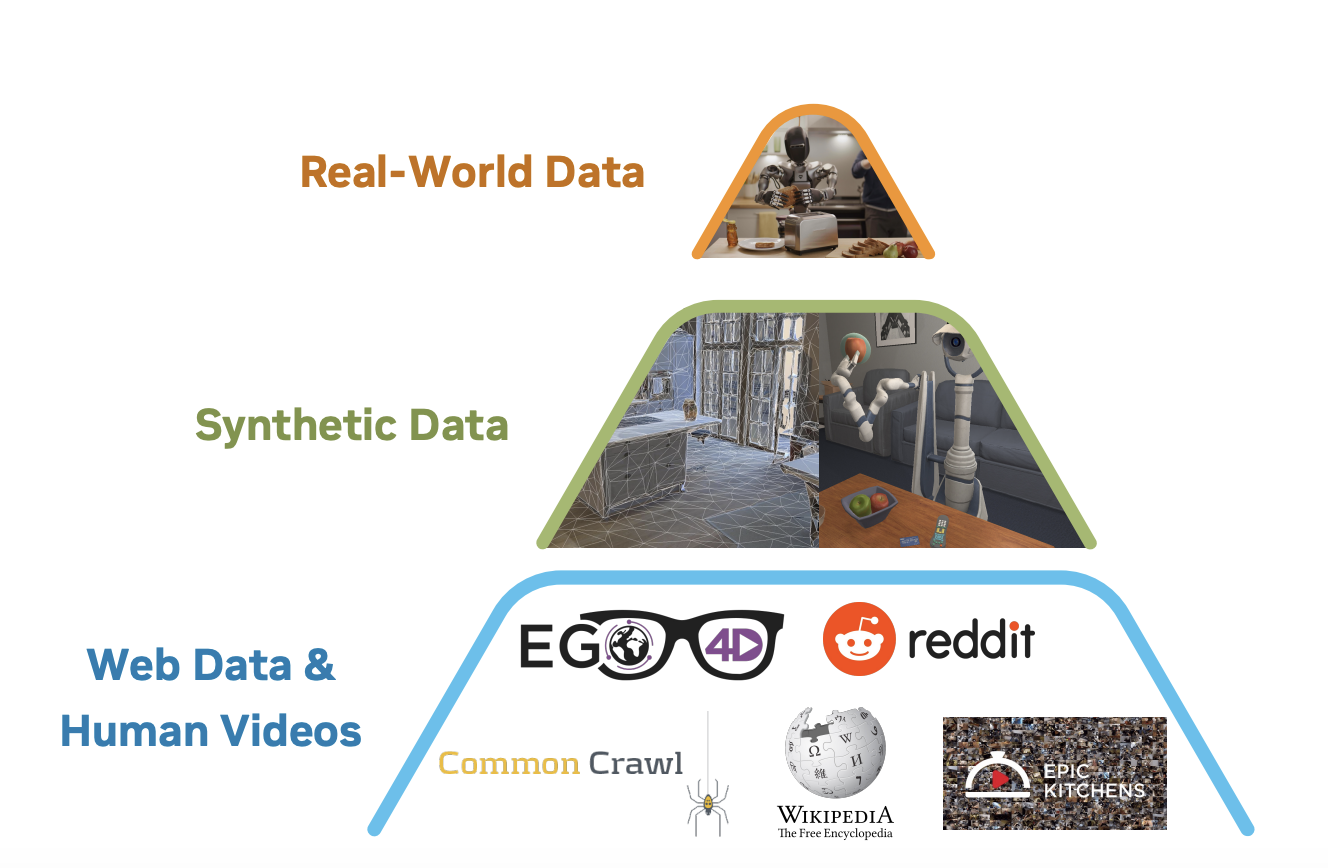
資料金字塔 #
NVIDIA以異質性資料組合來訓練 GR00T N1,資料來源包含真實機器人操作軌跡、人類影片,以及合成資料集,這些訓練語料庫建構成資料金字塔:大量的網路資料和真人影片構成了金字塔的基礎;透過物理模擬產生和/或透過現成的神經模型增強的合成資料構成中間層,而在物理機器人硬體上收集的真實世界資料構成頂層。
金字塔的下層提供廣泛的視覺和行為先驗,而上層確保具體化、真實機器人執行的基礎,如下圖所示:
》延伸閱讀:

