目前AI技術發展的重點,已從單純理解語言或影像,走向同時處理來自不同類型的數據或訊息的多模態(MultiModal)學習能力。這些數據可以來自不同的感官模態(如視覺、聽覺、觸覺、語言等),多模態AI模型能夠同時理解和分析來自多個模態的數據,並進行聯合推理或生成。多模態的應用情境相當多,例如:
視覺與語言:
-
- 圖像描述生成(Image Captioning):給定一張圖片,模型不僅要識別圖片中的物體(如人物、動物等),還需要根據圖片生成適當的文字描述。例如,”這是一隻正在玩球的狗”。
- 視覺問答(Visual Question Answering, VQA):給定一張圖片和一個問題(如“圖片中有多少隻人?”),模型需要根據圖片和問題來生成正確的答案。
語音與文本:
-
- 語音識別(Speech-to-Text)與語音生成(Text-to-Speech):這兩者分別處理語音與文本的轉換,實現語音到文字或文字到語音的相互轉換,這是一種典型的語言模態處理。
- 語音情感分析:通過語音信號中的音高、語速、語調等特徵來分析說話者的情感狀態。
視訊與文字:
-
- 視訊標註生成:視訊不僅包含影像信息,還有音訊信息,將視訊中的場景、動作、對話等轉化為文字描述是一種多模態應用。
- 視訊問答系統:給定一段視訊,並提出問題(如“視訊中的人是誰?”),模型根據視訊內容和問題進行回答。
當紅多模態模型 – LLaVA
LLaVA(Large Language and Vision Assistant)即是目前當紅的一種結合語言處理與視覺理解的開源多模能AI模型,主要開發者為微軟研究院,旨在提升機器對於圖像和文本的理解能力。LLaVA能夠在輸入的圖像和相關文本之間建立聯繫,並生成相應的描述、回答問題或進行互動,這使其在多模態應用中具有廣泛的應用潛力。
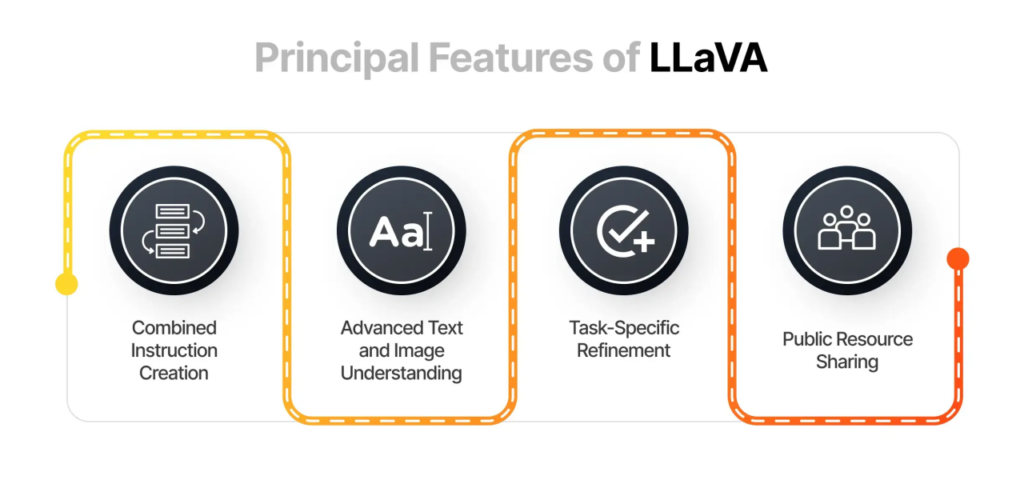
LLaVA的主要特色(Source)
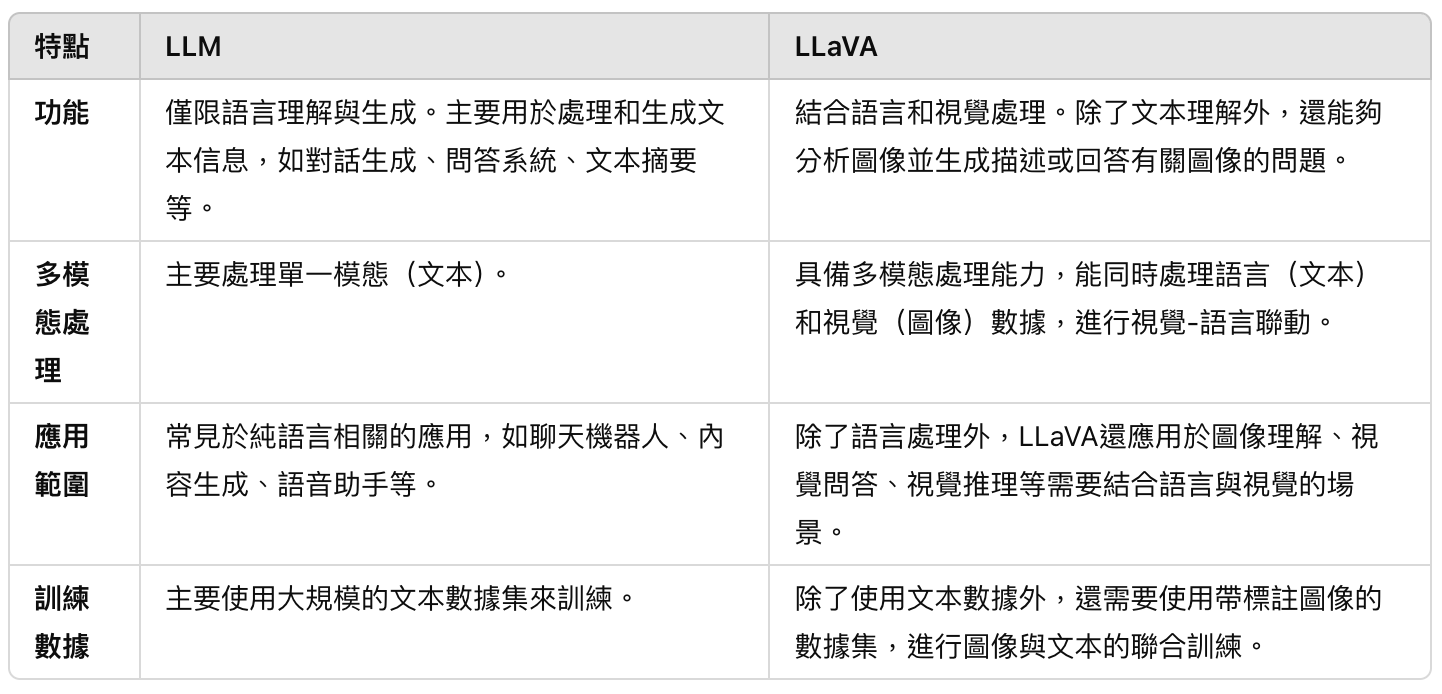
相較於LLM,LLaVA和LLM都屬於大型模型,是利用深度學習算法進行預訓練,尤其是基於Transformer架構,這使它們能夠捕捉語言和知識中的複雜模式,因此都具有強大的語言理解和生成能力,可以生成連貫的語句、回答問題和進行對話。
事實上,LLM 是 LLaVA 的基礎:LLaVA其實是在LLM的基礎上進行擴展和強化,加入了對視覺數據的處理能力。因此,LLaVA可以看作是融合了LLM和視覺理解的多模態模型。它在語言處理方面有LLM的強大能力,並且能夠理解和生成圖像相關的信息。
不過,LLaVA的創新之處在於能夠進行跨模態的理解與生成,將視覺信息與語言信息結合,提升了應用的廣度和深度,而LLM則是專注於單一模態的語言處理。兩者的差異比較可參考下表:
LLaVA的重要性
- 多模態理解:LLaVA能夠同時處理文本和視覺數據,這使其在理解複雜信息方面更加強大,例如對於圖像內容的深入分析。
- 應用範圍廣泛:LLaVA可以應用於許多領域,包括教育、醫療、電子商務和娛樂等。例如,學生可以用它來理解科學圖像或藝術作品,醫生可以用它來分析醫學影像。
- 人機交互的提升:透過結合語言和視覺信息,LLaVA能夠提供更加自然的互動方式,增強用戶體驗,讓機器能夠更好地理解和回應人類的需求。
- 促進創新:LLaVA的出現促進了多模態學習的研究,推動了新技術的發展,可能會引領未來人工智能的進一步創新。
LLaVA可行應用
以下是三個基於LLaVA的實際可行應用案例:
1.教育輔助工具
在教育環境中,LLaVA可以作為智慧教學輔助工具,幫助學生理解複雜的概念。例如學生可以上傳科學實驗的圖像,LLaVA會分析圖像並提供相應的解釋,例如反應過程、物質特性等。學生也可以提供藝術作品圖片,LLaVA可生成對該作品的歷史背景、技術分析和風格解釋的文本。
2.醫療影像分析
在醫療領域,LLaVA能夠協助醫生分析醫療影像(如X光片、CT掃描等)。醫生上傳影像後,LLaVA可以自動識別潛在的異常(如腫瘤、骨折等),並生成相應的診斷建議。此外,通過與患者溝通,LLaVA可以將影像分析結果轉化為簡明易懂的語言,幫助醫生解釋病情給患者,提升醫患之間的理解。
例如LLaVA-Med專案,即是LLaVA專注於生物醫學領域設計的模型分支,能分析醫學影像、解釋醫學圖表,並回答相關問題。
LLaVA-Med專案Logo
3.電子商務產品推薦
在電子商務平台上,LLaVA可以提升用戶體驗,幫助顧客做出購買決策。顧客可以上傳某種產品的圖片,LLaVA能夠識別該產品並推薦類似或相關的商品,提供詳細的產品信息和評價。若有進一步的客戶興趣和需求資料,LLaVA還可以生成個性化的購物建議,並解釋為何這些產品會符合顧客的需求。
推薦資源
如果您是開發者,以下是三個適合您深入了解LLaVA的網路資源:
- LLaVA官方Hugging Face資源:提供LLaVA的原始碼、模型檔案以及詳細的使用說明,開發者可以在此進行實驗和開發。
- LLaVA-MORE專案:這是對LLaVA架構的增強,首次將LLaMA 3.1整合為語言模型,並公開了8B參數模型的檢查點。
- LLaVA介紹與應用案例:這篇文章深入探討了LLaVA的工作原理、架構、訓練和性能,以及其在不同領域的應用案例,對開發者理解LLaVA的實際應用非常有幫助。
(責任編輯:歐敏銓)

- NVIDIA與全球機器人生態系推動具生產規模的實體AI - 2026/03/27
- 從VLA到落地部署:拆解新世代機器人開發關鍵路徑 - 2026/03/24
- 【Podcast】分散式代理時代:2026 Edge AI 技術全解析 - 2026/03/24
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


