作者:陸向陽

圖1 全世界最簡單的類GPT語音助理專案(圖片來源:Nick Bild)
ChatGPT的人性口語化回覆相信許多人已體驗過,也因此掀起一波大型語言模型(Large Language Model, LLM)熱潮,LLM即ChatGPT背後的主運作技術,但LLM運作需要龐大運算力,因此目前多是在雲端(Cloud)上執行。
然而在雲端執行也有若干缺點,一是Internet斷線時無法使用;二是或多或少會洩漏個資隱私;三是上傳的話語內容會被審查,但審查標準難以捉摸,且已有諸多矯枉過正的案例;四是因為模型已放在雲端與人共用,也可能已被他人誤導,俗稱模型被教壞了。
所以有些人也希望LLM能在本地端(Local)、本機端執行,如此就不怕斷線、洩漏隱私、內容審查、誤導等缺點。但要能在本地端執行,其LLM就不能太大,目前已經有諸多資訊技術專家提出各種嘗試,期望能將雲端的LLM輕量化、瘦身減肥,以便能在運算力有限的本機端執行。
全世界最簡單的類GPT語音助理
對此已有創客發起專案,專案名就叫World’s Easiest GPT-like Voice Assistant,即世界上最簡單的類GPT語音助理,以此實現完全在本機端執行的GPT語音服務,不需要任何Internet連線。
至於具體技術作法,首先是找一片樹莓派單板電腦,例如RPi 4,然後裝上麥克風與喇叭,成為語音互動對話的輸入輸出,而後安裝Whisper這套軟體,可以將麥克風接收到的語音轉成文字,文字餵給LLM。
LLM接收輸入後進行推論處理,處理後的結果以文字輸出,輸出的文字則透過另一個安裝軟體進行轉化,即eSpeak,把文字轉成語音後,再透過喇叭發聲回覆。

圖2 接上喇叭(右)與USB麥克風(左,取用自視訊攝影機附設的麥克風)(圖片來源:Nick Bild)
用TinyLlama-1.1B模型來實現類GPT語音助理專案
麥克風與喇叭只是末梢,重點是在LLM,哪來的輕量型、本機端執行的LLM?答案是llamafile專案,這個專案將LLM打包成單一個檔案,如此可方便地分發(分發distribute,通俗而言指可以輕易地下載檔案、傳遞分享檔案)與執行,專案發起者運用llamafile專案中的TinyLlama-1.1B模型來實現類GPT語音助理。
圖3 llamafile專案官網畫面(圖片來源:GitHub)
TinyLlama-1.1B確實是一個嬌小的LLM,以GPT-3而言就有175B,B即Billion指的是10億,LLM的大小通常以參數數目為準,1,750億個參數的LLM已相當龐大,需要對應強大的運算力才能順暢執行。
其他龐大的LLM還有MT-NLG,有5,300億個參數,或5,400億個的PaLM等,都難以下放到本機端執行,本機端很難有對應強大的運算力來跑模型。而TinyLlama-1.1B顧名思義只有11億個參數,參數大大減少下,本機端是有足夠運算力執行該模型。
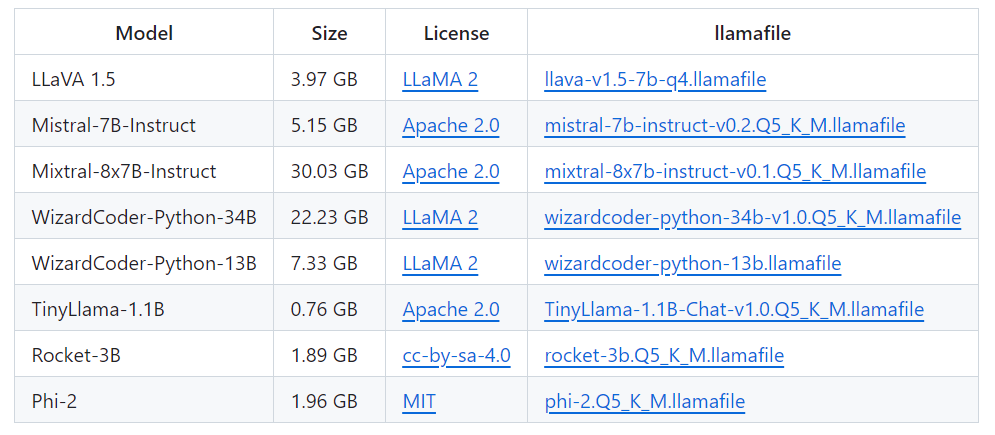
圖4 llamafile專案提供多種預訓練模型,目前以TinyLlama-1.1B最小,僅760MB(圖片來源:GitHub)
當然,上述所言均是預訓練模型(Pre-Train Model),或近期常稱為基礎模型(Foundation Model, FM),後續還是可以依據個人需要再行訓練與調整,以便有更精準、更切合需求的推論結果。
這個類GPT語音助理專案完成上述後,實際測試的結果是,多數的發話詢問後需要15秒左右的時間才能回覆,複雜的詢問則要更久的時間。有人可以等或覺得這時間還可以,若覺得太慢或許可以改用運算力更強的RPi 5單板電腦,可能可以快一點。
值得注意的是,這個專案不是用語音關鍵字(如Hey! Siri或OK! Google)來喚醒助理,而是設置一個按鈕,按下去後才讓樹莓派開始接收語音詢問。
另外,這整個專案用的都是開放原始程式碼及免授權費的軟體與模型,所以實現成本大概只有單板電腦、喇叭、麥克風、按鈕等硬體而已。
其他技術細節包含llamafile與Raspberry Pi OS不相容,所以在樹莓派上是改安裝Ubuntu Linux,更具體而言是64位元的Ubuntu Server 22.04.3 LTS。另外,當然也要安裝Python才能操控樹莓派的GPIO接腳,從而能讀取按鈕狀態(是否被按下)。
小結
最後,這肯定不是第一個也不是最後一個LLM本地端化的嘗試,各種嘗試正前仆後繼地進行著,有的是提供壓縮工具將原本肥大的LLM加以縮小,有的乾脆是原生訓練出輕量的LLM,現階段可謂是百家爭鳴。
而筆者個人的看法,1.1B的LLM已經很小,或許未來可以更小,但現階段可能改用更強的硬體會更務實,例如使用有GPU的桌上型電腦,或給樹莓派加裝AI硬體加速器等,以便讓類GPT語音助理更快速回應。
(責任編輯:謝嘉洵。)
延伸閱讀

- Windows PC上安裝PicoClaw最基礎實務 - 2026/03/03
- 跟上「龍蝦」潮了嗎?xClaw旋風現象觀察與後續 - 2026/02/26
- MakerPRO「2025台灣Edge AI開發者調查」初探 - 2026/02/11
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


