
本文將探討兩大主題,分叩是:1. 從〈Stable Diffusion + 企業圖庫〉訓練,進一步認識 AI 及機器學習;2. Stable Diffusion + ControlNet。
SD(Stable Diffusion)是當今頂級的Text-to-Image的繪畫技術,我將它比喻為「野貓」,為企業訓練的則稱為「家貓」。事實上,我們已為企業訓練出3只小家貓:CLIP、ControlNet和LoRA,並得到企業的極大讚賞,他們的心得是:「高等設計師將不會後悔使用ControlNet + SD(Stable Diffusion) + 企業圖庫。」
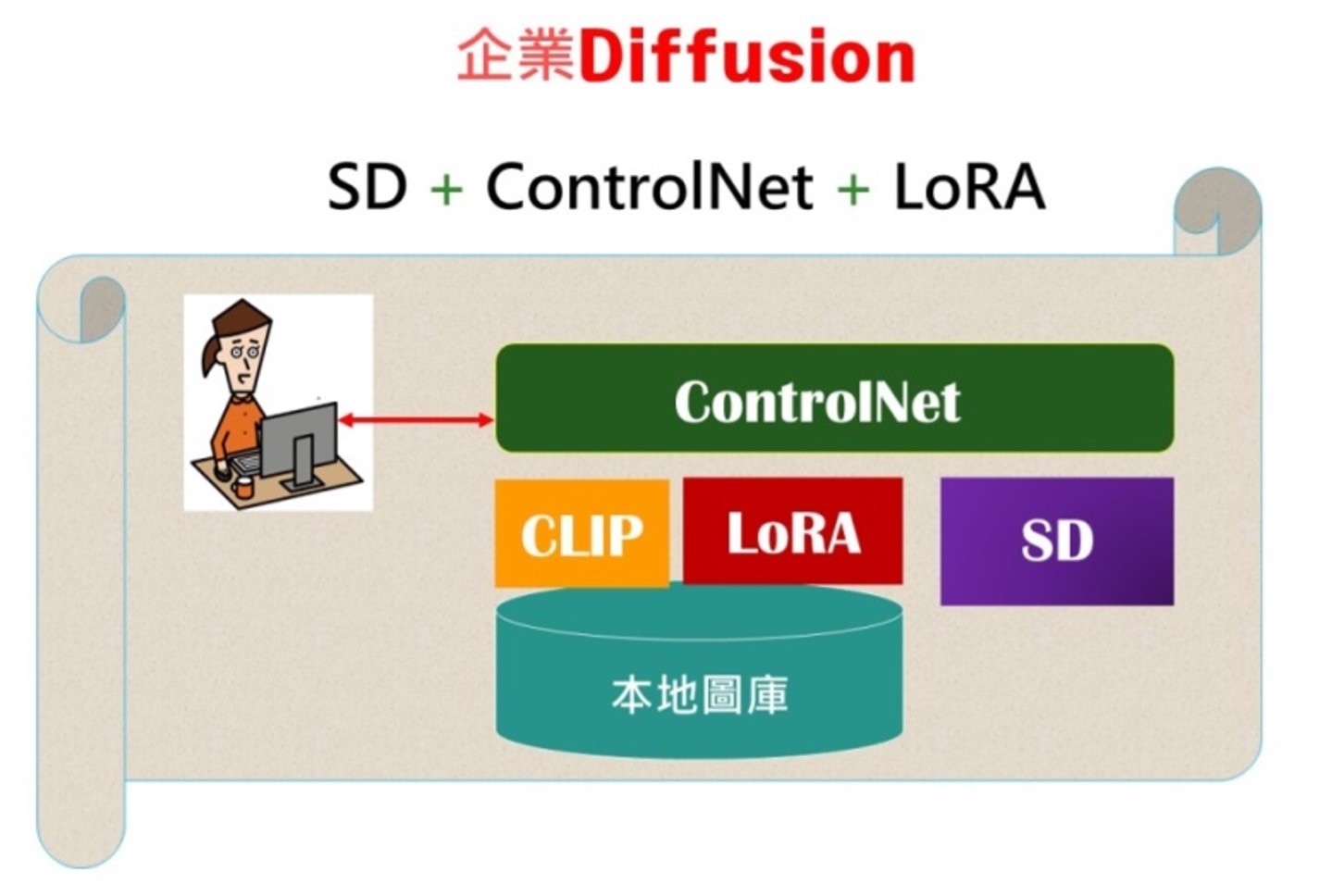
咱們逐漸分為兩個縱隊:1) 建模訓練SD+LoRA+ControlNet 。2) 開始使用SD+LoRA+ControlNet 進行美術設計。兩者都是以SD (Stable Diffusion )為主模型,搭配配合的3個子模型:CLIP 、LoRA、ControlNet。
這是Diffusion的基本架構圖:
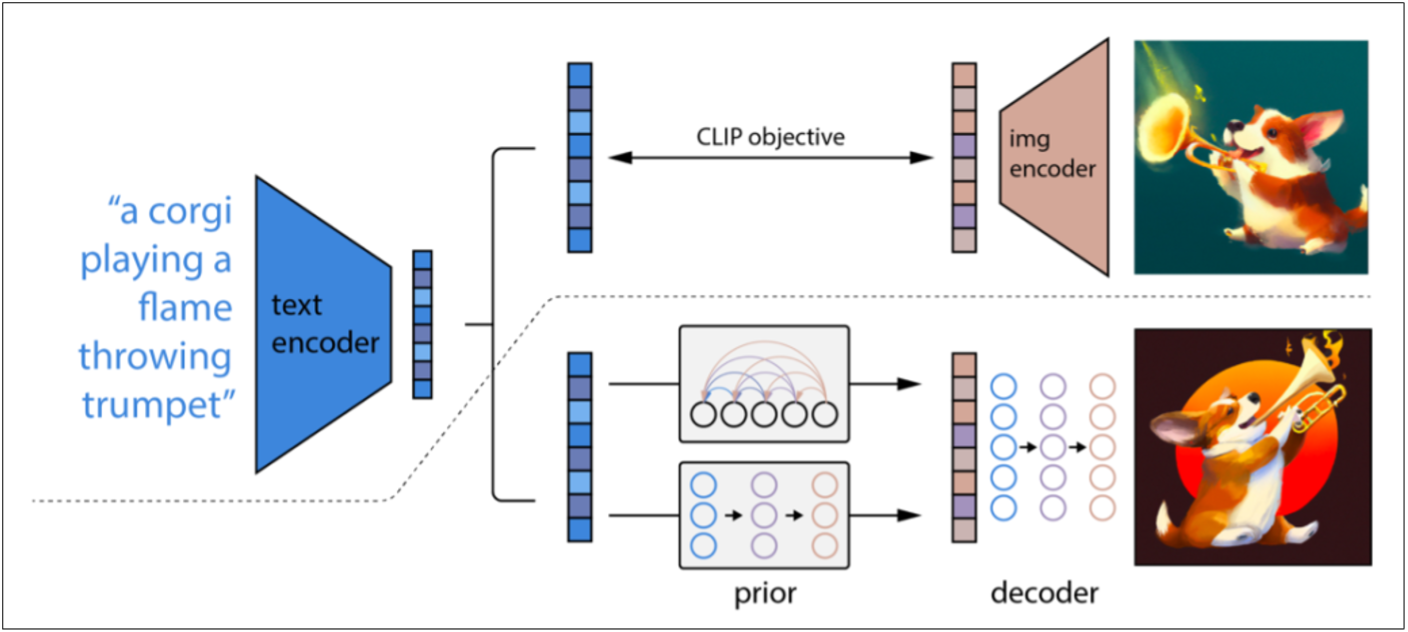
我發現有些人對圖中的encoder和decoder名詞含意似乎不夠清晰。這兩個是AI裡的基本名詞,處處常見。所以把它弄清楚是有必要的。為了充分掌握它,就必需從歐式空間來入手。所謂空間就是大家熟悉的座標空間。一維空間就是數線,例如:

這是兩個一維空間。人們隨著閱歷增多,逐漸學習,就會連連看,把兩個空間對映起來。

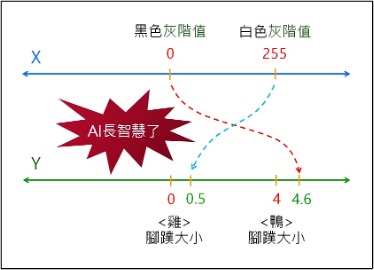
人們把它記憶於腦海裡。看到池塘裡有黑色家禽,就會聯想的「鴨」。看到池塘裡有白色家禽,可能就會聯想的「鵝」或「雞」。
茲回顧,在昨天的會議中,我們談論最多的就是:訓練AI。也就是如何引導AI去學習,就是所謂的:機器學習(ML:Mechine Learning)。於是,請您先思考:AI如何學會上述的連連看呢?
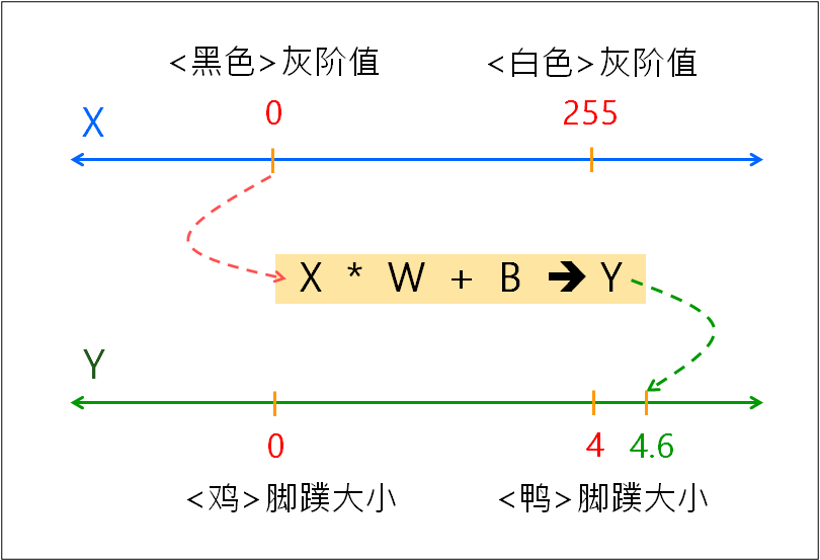
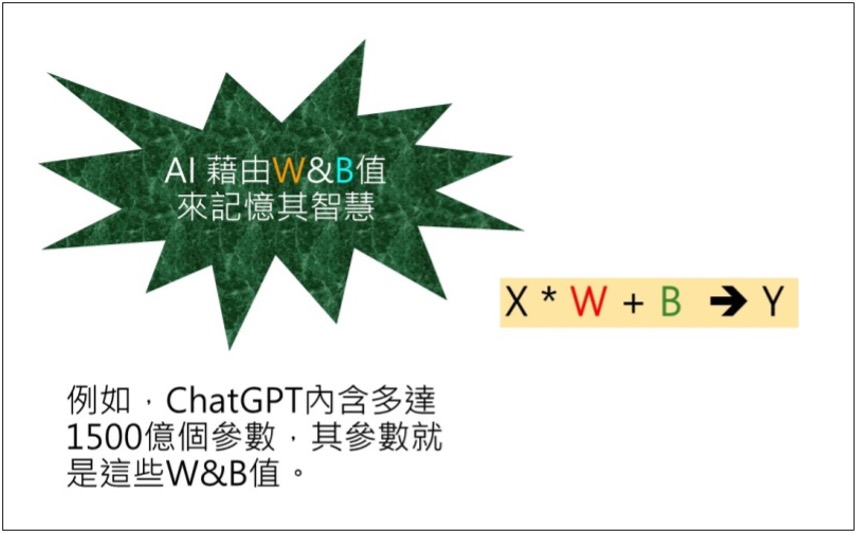
亦即,我們如何當老師,把我們上述的連連看智慧,傳授(教導)給AI模型,讓它也能記憶上述的連連看關係。也許您會覺得AI很笨,它就是依賴這個小學生都會的簡單數學公式,就是這個公式:Y = X * W + B。有時候會再延伸為: Z = Sigmoid(Y)。這個Sigmoid()函數,就稱為:啟動函數(Activation Function)。於是,拿來X=0,放入公式計算出 Y = 4.6。
於是,拿來X=255,放入公式計算出 Y = 0.5。
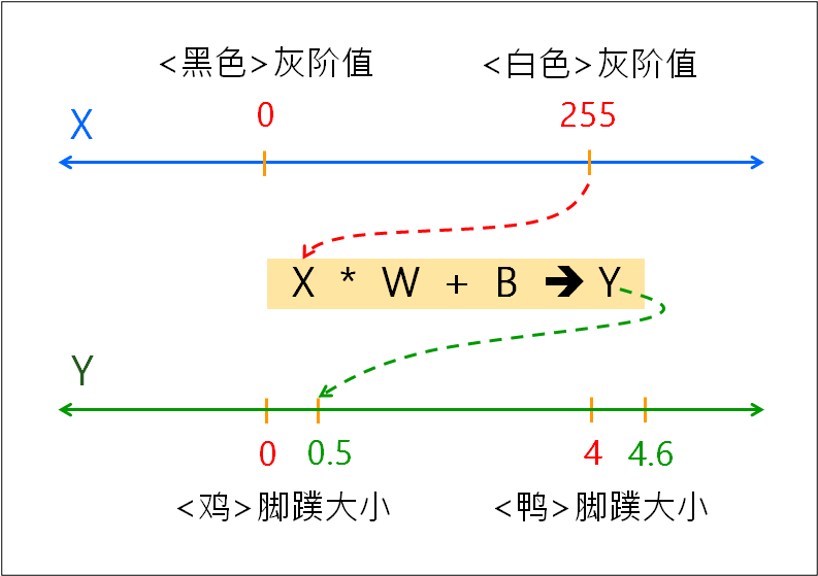
就這樣,只要AI記住W&B,就記住上述的連連看智慧了。
有了上述的基礎ML知識,就很容易理解encoder和decoder了。
當AI計算出Y=4.6,很接近於4, 就連結到「鴨」了,也就憑過去的學習經驗和智慧,拿起畫筆畫出一隻黑色鴨了。同樣地,AI計算出Y=0.5,很接近於0, 就連結到「雞」了,也就憑過去的學習經驗和智慧,拿起畫筆畫出一隻白色雞了。這就是AI美術創作的源點。
在上述的例子裡,白色灰階值為0,只有一個特徵值(feature )。上述例子是灰階圖像,每一個圖元(pixel)都有1個特徵(值)。把它擴大為彩色圖像,每一個圖元(pixel)都有3個特徵:RGB。
例如,白色RGB的特徵值是:〔 255, 255, 255 〕
例如,黑色RGB的特徵值是:〔 0, 0, 0 〕
例如,紅色RGB的特徵值是:〔 255, 0, 0 〕
那麼,請您試想,AI如何透過公式:X * W + B –>Y 來建立上述的關聯呢?答案是:把X設為向量(Vector )就可以了。就可以令 X = 〔R, G, B〕了。例如,〔250, 50, 3〕。
然而,我希望您的腦海裡,能夠出現一個歐式空間的景象:
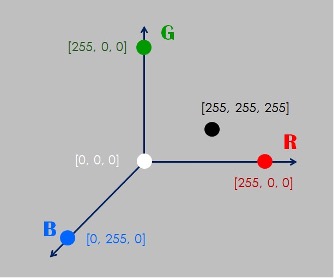
並且熟悉:x1 = [255, 0, 0],這一筆資料,一旦輸入到AI裡,它會成為「三維歐式空間」裡的一個點。所以這個歐式空間裡,可以儲存無限多個顏色資料。
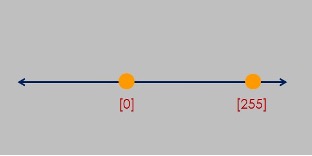
並且在您的腦海裡,時時運用一項概念:當 x = [255] 時,它即是1維歐式空間裡的一個點。
當 x = [255, 100] 時,它即是2維歐式空間裡的一個點。
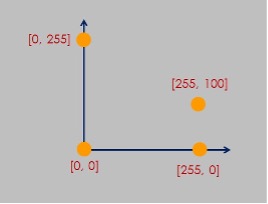
當 x = [255, 255, 255] 時,它即是3維歐式空間裡的一個點。
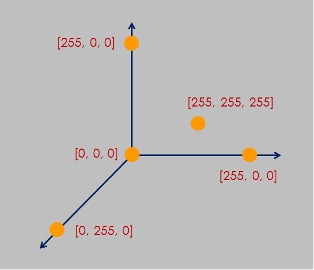
在AI裏,就拿歐式空間來表達宇宙中的一切事物或現象。例如,拿歐式空間來表達RGB色彩,就成為大家熟知的RGB色彩空間:
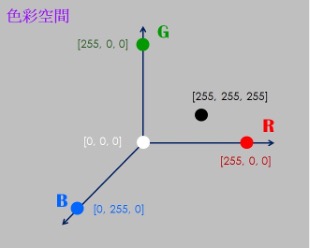
同理,也可以拿它來表達其它色彩空間,如:L*a*b 等等。
思維練習題:
有四張圖像,各章都由4個圖元(Pixel)所組成。
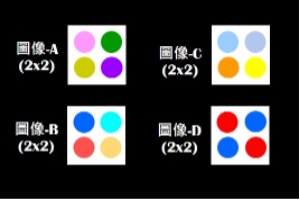
請您練習想想看,在AI裡如何使用歐式空間來表達這4件事物(即4張圖)呢?
答案是:每一張圖像有4*3=12個值(即12個特徵),每一個特徵值各在一維度軸上。於是,上述每一張圖在12維歐式空間裡,就是一個點。
以此類推,這是一張512 x512的 JPG圖像:

請您練習想想看,在AI裡如何使用歐式空間來表達這張圖像呢?
答案是:每一張圖像有512*512*3個值(即特徵),每一個特徵值各在一維度軸上。於是,上述這張圖在512*512*3維歐式空間裡,就是一個點。
希望您不要忽略上述基礎觀念。一旦您忽略了,可能就不容易看懂網路上許多關於AI及ML的文章。一旦您充分掌握這些AIGC的基本技巧和觀念,就能流暢看懂網路上的各文章,迅速成長了。
Embedding
基於上述的基礎,接下來,就可來理解一個常見的名詞:Embedded 及Embedding 。
剛才提到下圖:
其中,每一張圖像有4*3=12個值(即12個特徵),每一個特徵值各在一維度軸上。於是,上述每一張圖在12維歐式空間裡,就是一個點。
在這12維空間裡,存放(記載)這4張圖(只含4個點)。以乎有些浪費空間,計算也常比較費時。那麼,我們能否把它降維呢?例如,利用5維空間的4個點來代表這4張圖,會更省空間,也省時間。
再如,可否利用3維空間的4個點來代表這4張圖,會更省空間,也省時間。甚至,可否利用2維空間的4個點來代表這4張圖,會更省空間,也省時間。
答案是:可以的。但是,請想一想:5維空間的每一個點只能含有5個值(特徵),而上述每一張圖有12個值,該怎麼辦呢?
同理,請想一想:3維空間的每一個點只能含有3個值(特徵),而上述每一張圖有12個值,該怎麼辦呢?同理,請想一想:2維空間的每一個點只能含有2個值(特徵),而上述每一張圖有12個值,該怎麼辦呢?
這個降維過程,就稱為:嵌入(Embedding )。即是:高維空間裡的點,對應到低維空間裡的點。例如下圖:
這張圖像有512*512*3個值(即特徵),每一個特徵值各在一維度軸上。於是,上述這張圖在512*512*3維歐式空間裡,就是一個點。我們可把它嵌入到較低維空間,如32*32*3維空間裡。嵌入的計算方法就是這公式:Y = X * W + B。
在嵌入的過程中,需要過慮掉一些特徵值。例如原來上圖共有512*512*3個特徵值中,把不顯著的特徵值過慮掉,但保留顯著的特徵(如留下32*32*3個值)。這樣,逐漸地您會更熟悉Stable Diffusion 這張圖了:
茲放大如下:
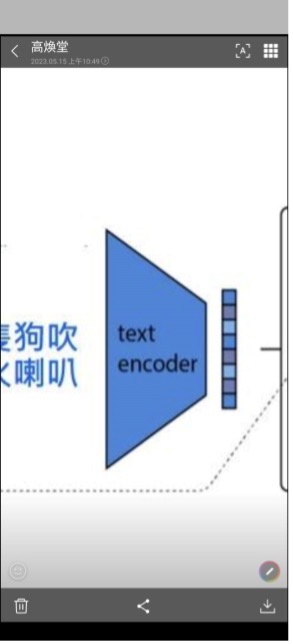
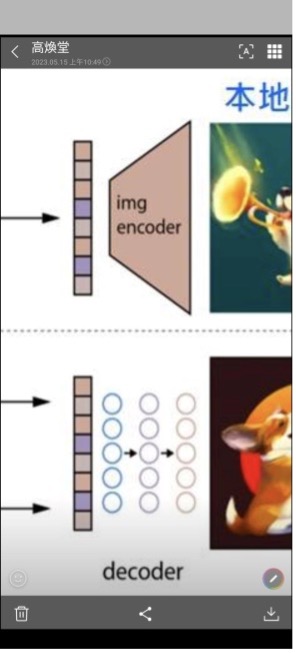
接著就可以進一步認識decoder 了。
請看下圖,將兩個不同的高維空間裡的點,嵌入到同一個低維(如3維)空間裡。
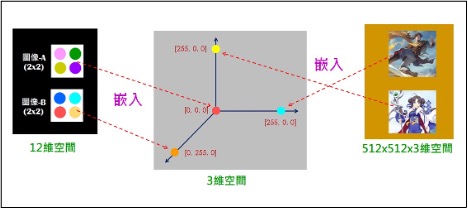
當我們告訴AI,讓AI知道:「趙靈兒」喜歡「圖像-B」,而「李逍遙」喜歡「圖像-A」。AI進行機器學習(Machine Learning)時,就會逐漸調整其嵌入的點,變成為:
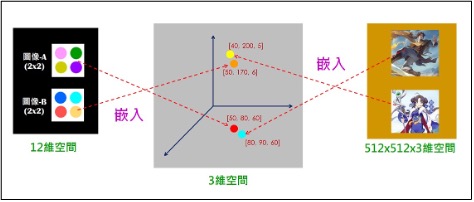
左右兩邊的高維空間是人們視覺的空間,稱為:可觀測空間(Obervable Space)。而中間的低維空間,非人們視覺可觀察並瞭解其含意的空間,通稱為:隱藏空間(Latent Space)。
當您問AI:圖像-B不見了,最可能是誰拿走了呢? AI依據隱藏空間,就回答:可能是趙靈兒拿走的。其中,擔任「嵌入」任務的AI模型,就通稱為:Encoder(編碼器)。
既然,上圖可以從高維空間嵌入到3維空間。當然也可以繼續從3維空間嵌入到2維空間。甚至繼續從2維空間嵌入到1維空間。這項嵌入動作又稱為:空問映射(Space mapping )。
請您動動腦,想想AI這樣進行多層映射,猜猜其目的和效益何在?這樣的多層映射(可多達100層映射),就是〈深度學習〉(Deep Learning )的機制。其中的”Deep”就是指含有「很多層」映射。
「嵌入」的相反動作就是:「生成」。負責嵌入的模型叫:Encoder ,而負責生成的核心模型叫:Decoder 。這Encoder的中文是:編碼器,而Decoder的中文是:解碼器。請您再看看這張圖:
我們可設計一個encoder模型來擔任左邊的嵌入動作。例如我們把圖像-B的12個值輸入給encoder,它會輸出3個值:(50,170,6),它是隱藏空間裡的一個點。
依循反向流程,我們可設計一個decoder模型來擔任左邊的生成動作。例如我們把橘色點的3個值圖(50,170,6)輸入給decoder,它會輸出12個值,若繪成圖像,它將很近似於圖像-B。這即是AIGC (AI生成)。
請試想:為什麼這是電腦計算的結果,而其生成圖案只會是「相似」於原圖像-B而已,並不會完全一樣呢?如果您能說出其緣故,就恭喜您已入門AI了。
其緣故是,因為 Encoder在進行嵌入到低維空間時,會過濾掉一些訊息。例如,從圖像-B的12個值,刪減一些訊息,成為3個值。因而圖像-B裡的一些細節部分會被過濾掉。
然後,把這3個值輸入給Decoder,此時Decoder必需把被過濾掉的細節部分弭補起來,於是把輸入的3個值,添加弭補的訊息,來恢復出12個值。這Decoder所添加弭補的部分,就是AI生成的內容。
再請您想想:Decoder又根據什麼規則或知識,來決定添加些什麼訊息呢?
上述的答案是:Decoder根據它自己的知識(或智慧)來決定添加(生成)那些訊息,然後繪出成為高維(如3*512*512維)的JPG圖像。
那麼請您繼續試想:這Decoder 自已的知識又從那裡而來呢?答案是:Decoder 經由它自己努力學習而得的知識或智慧。這項學習,就稱為:機器學習(Machine Learning )。
無論是Encoder 、Decoder 或其它AI模型,都具備有〈學習〉的能力,都能從文本(Text)、圖像(Image )、聲音(Audio )等特徵資料來學習其中的知識,以從人類專家的指引學習。
從AI角度而言,上述學習過程,稱為:機器學習。換個角度,改從人角度看,則上述機器學習又稱為:人類訓練(Train) AI模型。所以,AI模型的學習(Learning ),就等同於(人們)訓練(Training ) AI模型。
我們可以建立不同的Encoder來進行從(人眼)可觀察空間,將可觀察事物(如圖像)的特徵值,嵌入到人眼看不見的潛藏空間(Latent Space)裡。這稱為:Sapce mapping。例如:
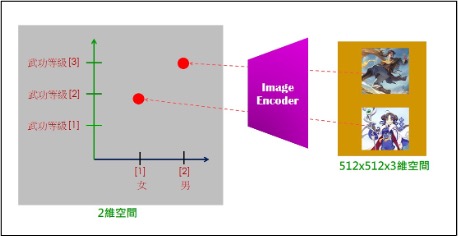
再如:
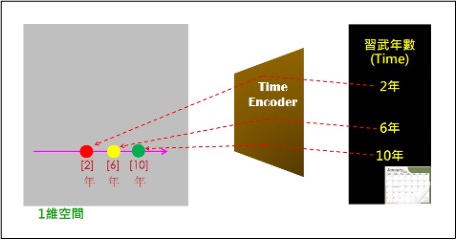
人們想像可觀察空間裡事物,例如:有人正在偷看靈兒在山泉下洗澡。而AI就在潛藏空間裡,對潛藏框空間裡的嵌入資料(通稱為:Embedding code)進行操作,來組合、生成創新的東西(仍在潛藏空間裡),然後交給Decoder來還原出可觀察空間的事物(如新圖像、或新文句等)。
例如,把兩個潛藏空間(2維和1維),匯合成為一個潛藏空間(3維)。
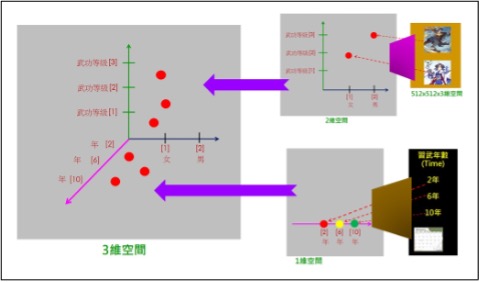
人們就如同餐廳裡的客人,想像飯桌上的香色菜餚、米飯甜點的情境。而AI就如同廚房裡的大廚師,在悶熱的廚房裡(即潛藏空間)煮飯、炒菜、蒸甜點、添蔥加醋等,努力進行操作,來組合、生成創新的東西(仍在潛藏空間裡),然後交給Decoder來還原出可觀察空間的事物(如新圖像、或新文句等)。
再如:
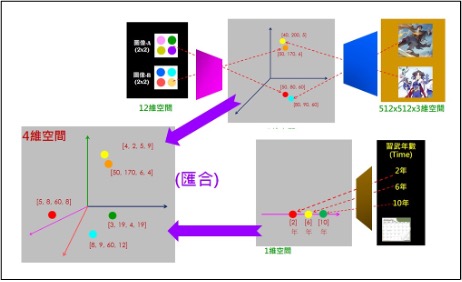
俗語說,怕熱的就不要進廚房(潛藏空間:Latent space)。我希望您雖然不必親自捲袖做羹湯,但也可以走進廚房增進一些新知識。

近5年來,從事於AI普及化教育工作,目前擔任銘傳大學AI課程、長庚智慧醫療研究所AI課程授課老師。也擔任永春國小、東園國小、立志中學、君毅中學、永春高中等學校的AI師資培育工作。
- LoRA微調三步驟:以大語言模型MT5為例 - 2024/05/02
- 為什麼Gemma採取Decoder-Only Transformer架構呢? - 2024/04/08
- 如何從0訓練企業自用Gemma模型 - 2024/04/03
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!
