作者:Felix Lin
Maker 玩 AI 系列專欄用深入淺出的方式,介紹 Maker 容易入門的 AI 軟硬體工具,並且以實際案例引領上手。有好用的 AI 軟硬體也歡迎留言討論喔!
Google 於 2017 年製作了 Teachable Machine(以下簡稱 TM) 網頁版本的AI軟體工具,甫一推出就受到優異的好評與回響,原因在於這個網站幾乎可以不需要任何說明與敘述,就可以自行摸索搞懂原來用AI實踐電腦視覺是這麼一回事!
之後更於2019年推出 Teachable Machine V2,除了將原有的Image Classification(影像分類)由固定三個分類擴充為自定義分類數量,並且增加了Audio(聲音)與Pose(人體姿勢)兩個類別的分類器,此外更支援專案的存檔與轉匯出功能,不但能保留資料於日後繼續編輯,同時還能匯出Keras、TensorFlow、tf.js等不同格式的模型檔案,大幅提高了後續轉應用的可玩性!
怎麼玩?
進入 [TM 網站]點選 “Get Started”,會看到新專案選擇頁面,這邊可以選擇開啟三種不同類型的新專案,分別為影像、聲音與姿勢,建議就從最基本的的影像專案(Image Project)開始。
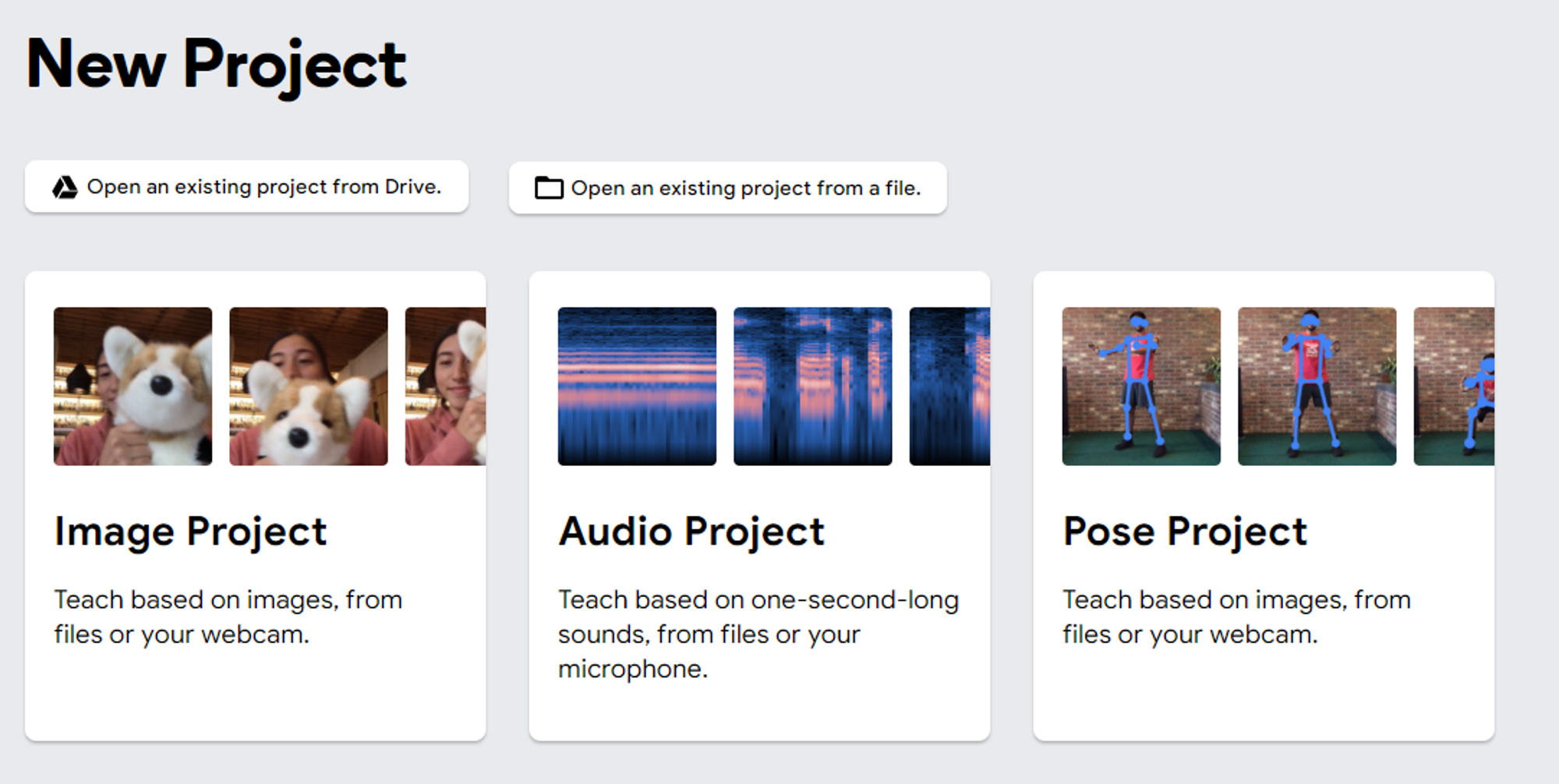
Teachable Machine 上三種不同類型的專案
點選後會有一個彈出是對話框,詢問要選擇標準影像模型(Standard image model)或是嵌入式影像模型(Embedded image model)。兩者的差異在於輸入的影像尺寸是標準的 224×224 像素,或是精簡的 96×96 像素小尺寸影像,後者特別適用於搭載 TensorFlow Lite 的嵌入式系統或是微控制器。建議可以先選擇較為泛用的標準尺寸模型,在此一旦選定了,後續就不能夠再做更換。

模型尺寸選擇
接著就會到訓練模型的介面了,這裡可以看到左邊、中間、右邊三個區塊,彼此之間用線連接起來,可以理解這分別代表訓練神經網路模型的三個階段:收集資料、訓練模型與測試預覽模型。左邊區塊是要餵進神經網路的各類資料,預設有兩類,類別不足可以點選 “Add a class” 增加新的類別。這邊筆者就來實際操作 Maker 開發板的分類器,拿了 LinkIt 7697、Raspberry Pi PICO、TTGO T-Display 來做分類,並且增加一個 Nothing 總共四類。

Teachable Machine 訓練介面
在每一個類別中最上方有個名稱標籤(label),可以點選旁邊的修改圖示自行更名為想要顯示的類別名稱。下方則是影像資料區塊,有兩種方式可以加入資料,分別是透過 Webcam 網路攝影機以及上傳檔案的方式。最便捷的方式就是使用 Webcam 收集資料了,只要手邊有要分類的物品,就可以直接透過 Webcam 拍照儲存成訓練資料。

Teachable Machine 訓練資料設定
選擇 Webcam 拍照的方式瀏覽器會先詢問要求存取攝影機的權限,開啟後會顯示拍照介面。若電腦上有多個攝影機,會有一個下拉式選單選擇要從哪一個攝影機拍照,只有一個攝影機則不會出現此選單。下方即是攝影機的即時預覽畫面,左上角有個裁切影像的按鈕,如果要拍攝的物體比較小,可以使用此功能將畫面裁切到合適大小,畢竟大部分的攝影鏡頭都有 1280×720 的解析度,而 TM 神經網路的影像只需要 224×224 大小,因此適度的裁切並不會影響模型的訓練。按下 “Hold to Record” 按鈕,就會自動拍攝照片。

Webcam 拍照介面
點選右下的齒輪後,會跳出拍攝的相關設定:
•FPS: 每秒拍攝張數,預設為 24。若設定過高可能會拍攝到大量重複的照片,建議設定為 5~10 張。
•Hold to Record:按住按鈕時拍照功能,放開按鈕就會停止拍攝。若設定 FPS 為 10,按住 3 秒則會拍攝到 30 張照片。關閉這功能可以騰出雙手,在拍照時更便利調整物體的角度與方向。
•Delay: 按下按鈕後,延遲多久開始記錄。關閉 “Hold to Record” 時可用。
•Duration:開始記錄後,持續多久。若設定 6 秒,FPS 為 10,則會連續記錄 6 秒,得到 6 x 10 = 60 張影像。

webcam 拍照設定介面
完成設定就可以開始拍攝要分類的物體,提供不同角度、正反面、不同背景的照片。照片的數量建議至少超過100張會比較理想,也要明確地能夠記錄到物體的相關特徵。如果有拍攝到不適合的照片,也可以從右側的圖庫當中將其給剃除。

拍攝合適的訓練資料
此外如果是沒辦法取得該物體現場拍照的分類,則可以上傳檔案功能。檔案可以從本地端電腦上傳,或是連結 google drive 雲端硬碟匯入資料,資料的格式可以是各類圖檔(jpg, png, bmp等)或是將所有圖檔壓縮起來的 zip 檔。由於神經網路輸入的影像尺寸為 224×224 像素,因此不論是從 Webcam 拍照或是上傳照片檔,所有的圖片都會被裁切為正方形,並且壓縮為 224×224 大小。

上傳照片介面
順帶一提,在各分類右上角的選單內,有幾個實用的選項,分別是刪除類別(Delete Class,此分類照片也會消失)、停用類別(Disable Class,不納入訓練資料中,但照片會保留)、清空照片(Remove All Samples)、下載照片(Download Samples)以及將照片儲存到 Google Drive (Save Samples to Drive)。以筆者的使用經驗來說,有時候想要把照片匯出到其他深度學習框架中訓練,在 TM 上拍攝照片再搭配 “Download Samples” 這功能就非常實用。

對單一分類的設定操作
在筆者的範例中,各分類都拍攝了約 300 張照片,收集完所有類別的照片資料後,就可以進行訓練了。訓練開始前會需要配置記憶體、準備模型等前置作業,實際開始訓練時約莫花費一分鐘左右即可完成。

訓練完成後在右側的區塊就能看到從 Webcam 抓取即時影像的推論結果,下方則會顯示各個分類的信心值是多少,總合為 100%,占比最高即為此模型所辨識出的物品。
即時預覽與識別
從 TM 看深度學習參數
仔細看 Training 按鈕下方有一個 “Advanced” 摺疊選單,展開之後有一些額外的超參數(Hyperparameter)可以設定,而這些參數也是我們在訓練神經網路時經常調參(tuning)的幾個參數:
• Epochs: 訓練次數,要把所有訓練資料都丟進神經網路訓練幾次,預設值為 50。理論上越多越好,但花費的時間也會越多,且不合適的資料也可能造成模型無法收斂或是過擬合。
• Batch Size: 每次迭代 (Iteration) 要從訓練資料中抓取多少資料進行訓練,預設值為 16。在資料量固定的情況下,Batch Size 越大跌代次數就會越少,但因為同時間要讀取更多的影像資料,所占用的記憶體空間也會更大,且迭代次數過少也會影響到模型的精確度。
• Learning Rate: 學習率,預設為 0.001。可以把學習率理解為神經網路模型往最小誤差的目標,每次移動的步伐大小,步伐過小需要走很久才會到,步伐過大可能不小心就走過頭,更嚴重則永遠走不到目標處。學習率的調整需要更多的經驗,且通常都不會設定太高。

訓練參數 Hyperparameter
除了訓練參數可以調整,也有訓練過程的數據可以參酌。 在 “Advanced” 摺疊選單最下方有一個 “Under the hood” 選項,點選之後會彈出右側欄,上面就會顯示本次在訓練過程的相關數據。依序會看到 Accuracy per class (各類別精確度)、Confusion Matrix(混淆矩陣)、Accuracy per epoch(每次訓練後的精確度折線圖)以及 Loss per epoch(每次訓練後的損失折線圖)。
TM 在訓練時會將所有類型的資料按比例拆分為 85% 訓練資料以及 15% 的測試資料,其中 15% 測試資料是不會餵進去神經網路進行訓練的,而是在其訓練完成後,用以測試模型的訓練狀況之用。 Accuracy pre class 就是顯示這些不同類別的訓練資料的正確率,所顯示的樣本數 45 張則是來自於各類別總體樣本 300 張裡的 15% 。Confusion Matrix 則是更詳盡地顯示出,如果在測試時出現錯誤的部分是錯在哪裡,方便使用者發掘是不是其中有分類資料過於相近、不夠明確、標記錯誤等問題,在下一次的訓練之前做調整。

最下方兩張趨勢圖則是顯示在每次訓練後準確度以及損失值的變化,原則上準確度是越高越好而損失值是越低越好。這兩張圖在完整的深度學習框架上會非常實用,用以判斷整個模型在訓練過程是否能有效收斂。

準確度(Accuracy)與損失(Loss)的變化趨勢圖
專案匯出與保存
Maker 們應該都會希望訓練出來的神經網路模型,可以落實在不同領域做應用吧!點選右側 Preview 區塊旁的 “Export Model”(匯出模型)按鈕,會彈出一個對話框,最上方的三個頁籤顯示出可以匯出三種被同類型的神經網路模型檔案,分別為 Tensorflow.js(用於網頁)、Tensorflow(Tensorflow框架與Keras)與 Tensorflow Lite(用於樹莓派等嵌入式系統)。在 Tensorflow.js 頁籤中,可以選擇把模型上傳到 google 雲端或是下載到本地電腦,下方也有簡易的使用範例程式碼,提供開發者直接用於自己的網頁上。

匯出模型功能
即便導出了模型檔,但難免還是會有需要重新修改模型或是新增類別等狀況,為了不讓每一次訓練模型都是從零開始,TM 當然也支援儲存專案功能。更方便的是可以連結 Google 帳號後,直接將專案存放在雲端硬碟,日後也只要登入雲端硬碟,就能開啟既有專案重新調整與訓練啦!

社群專案
鑒於 TM 的方便易用,網路上自然有不少使用 TM (或TensorFlow.js) 衍生的社群專案,像是整合 Arduino 控制的Tiny Sorter,運用筆電的網路攝影機分類穀片與棉花糖,並連帶使用 Arduino 控制伺服馬達,將其丟置對應的碗盆中,讓 TM 從軟體的分類器演化成”實體的分類器”了!

Teachable Machine 整合 Arduino 控制的 Tiny Sorter 專案
Semi-Conductor則是運用人體姿勢的模型 PoseNet 辨識手勢的位置,藉此您將化身一個指揮家帶領一個虛擬的管弦樂團進行曲目的演奏。運用人體姿勢的影像辨識,來達到互動藝術的效果。

Semi-Conductor 專案
抑或 Maker 們也可以使用 TM 來快速訓練分類模型,再藉由其匯出功能,將模型匯出成 TensorFlow 或 Keras 格式模型,在放到邊緣運算裝置上運行。筆者日前的文章著作也實作了在 TM 訓練模型並匯出 TensorFlow 格式,再使用 Intel OpenVINO toolkit 進行模型最佳化,最終可以放到筆電或是邊緣裝置上實現電腦視覺。
倘若是使用 Arduino IDE 開發 MCU 程式的 Maker ,也可以使用 TM2MQTT這套工具,將 TM 的模型在電腦推論後所得到的結果,藉由 WebUSB 或是 MQTT 的方式傳送給微控制器。TM2MQTT Host 在 github 上面,如同 TM 一樣只要開啟網頁即可操作。 在匯入雲端模型網址之後同時會開啟 Webcam 進行影像辨識,同時可以設定將辨識到的分類 ID 傳送給到 Serial port 序列埠,或是發送到指定的 MQTT Broker。如此一來即使是無法進行 AI 推論的微控制器,也能因此體驗到邊緣運算的應用優勢。

TM2MQTT,將 Teachable Machine 的推論結果傳送給效能較低的微控制器
小結 - 雖不完美、但已足矣
即便 TM 功能簡單陽春且也僅能訓練分類模型,但應用於國內外的教育現場教學也處處可見,不論是中小學的電腦課程,或是AI線上教學資源都能見到其足跡。很多時候我們並不需要一個完美且強大的瑞士刀,而是一個恰如其分、能有所啟發與延伸的小工具,就可以大大滿足了!稍微探聽一下,是否各位讀著周遭就有不少人是藉由 TM 來啟蒙深度學習的呢?
(本篇文章經同意轉載自vMaker,原文連結;責任編輯:謝嘉洵。)

- 以MCU開啟Edge AI新境界:Renesas RA8P1實測 - 2025/10/22
- Windows on Snapdragon部署GenAI策略指南 - 2025/09/23
- 運用Qualcomm AI Hub結合WoS打造低功耗高效能推論平台 - 2025/08/01
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


