作者:CAVEDU 教育團隊
MIT App Inventor 團隊滿早就發佈了 look extension,概念上是使用預先訓練好的 tensorflowjs 模型來做到簡單的物件分類,但除非您本身會 tensorflowjs 還要會打包 app inventor extension,不然就是玩玩看 look 就算了,談不上什麼客製化。對於AI視覺辨識來說:「當然就是要 app 看懂我們要它看懂的東西,這樣才酷啊!」
MIT App Inventor 有位帥氣學生開發者,針對繁複的訓練流程建立好一個網頁,您可用電腦或手機(手機操作會比較辛苦,因為還沒針對行動裝置調整版面)開啟這個網頁就可以進行操作。
這確實呼應了我們的新書書名《實戰AI資料導向式學習》,只有您自己最清楚「怎樣才是夠好的資料」,請直接下載 .aia 來玩吧(感謝 CAVEDU 2019 實習生陳俊霖同學),本範例已經針對 CAVEDU AI 車情境的路牌訓練好了,按下 app 的按鈕,拍照就可以透過之前訓練好的神經網路進行視覺分類,無需使用任何雲端服務,聽起來很棒吧!

(圖片來源:CAVEDU提供)
視覺分類網頁介紹
1. 加入訓練資料
請開啟 https://classifier.appinventor.mit.edu/ 就會看到以下畫面並打開 webcam,請先設定 label 再開始拍照或上傳照片,以下圖來說各拍了30張。
另外也可以看到提供了 upload model 的選項,供進階開發者使用。
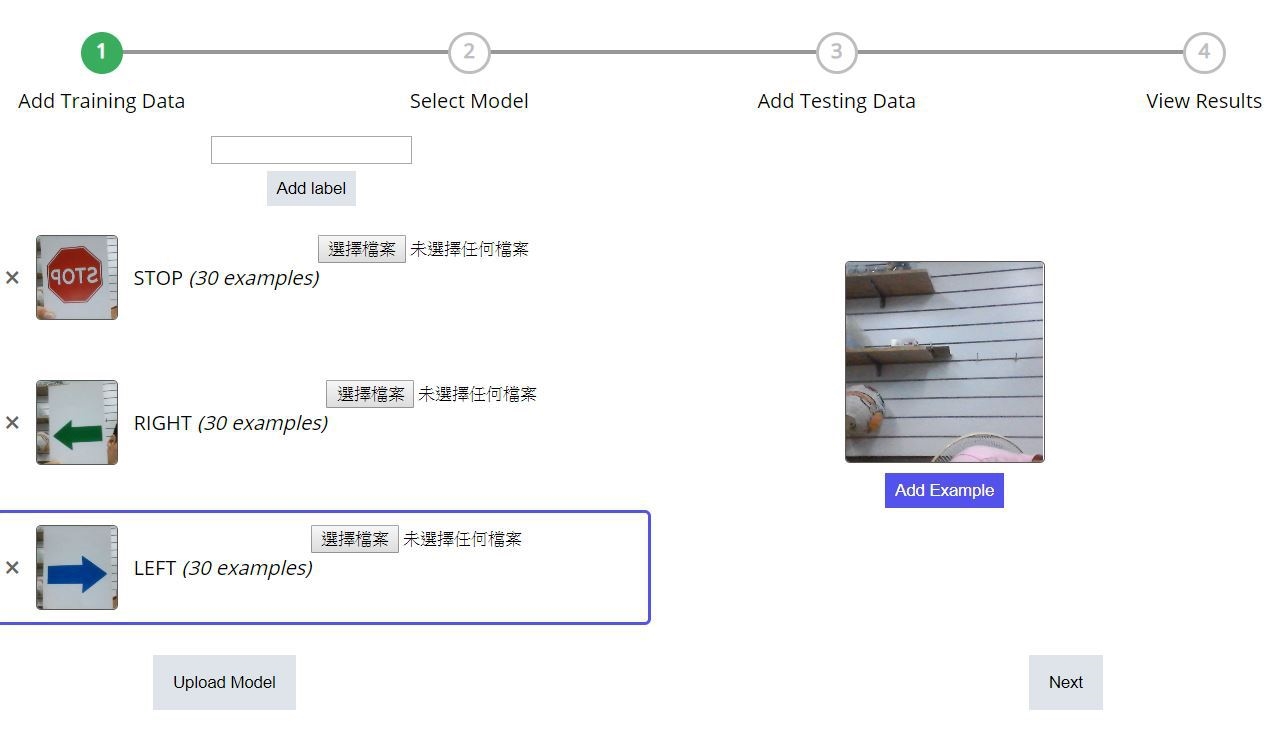
(圖片來源:CAVEDU提供)
2. 選擇神經網路模型
類似 Microsoft CustomVision 或 Google AutoML Vision 這類的線上 AI 視覺服務雖然很方便好用,只要提供要辨識的照片再標好 label 就可以有不錯的訓練結果。
但一些細節就被隱藏起來了,例如您無法去調整訓練的超參數與神經網路架構。本網頁針對針對不同技術背景的開發者真的有很多貼心的地方,請多多使用喔。
a. 設定模型:
目前只有 MobileNet 與 SqueezeNet 可以選。
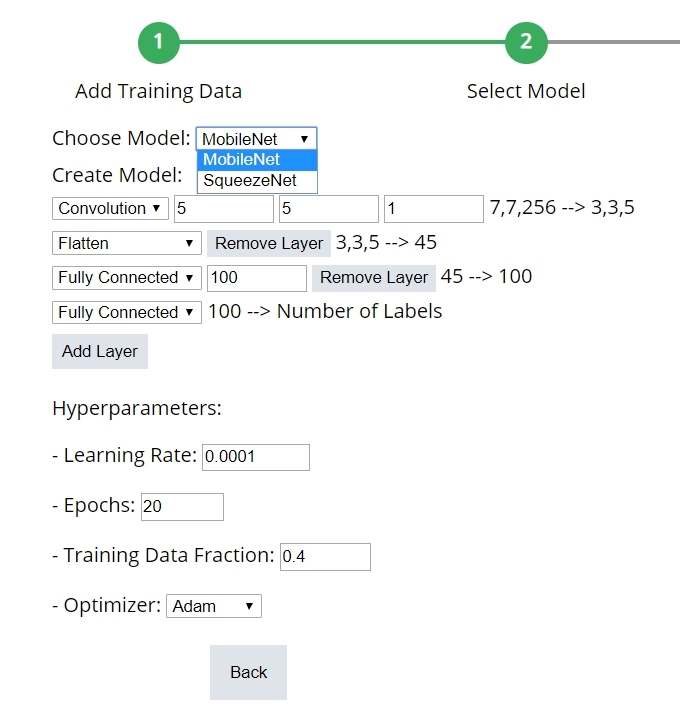
(圖片來源:CAVEDU提供)
b. 建立模型
本頁面讓您自行新增所需要的神經網路層。當然啦,您必須要對卷積神經網路有基本概念才會覺得這裡很貼心,不然也是看不太懂在做什麼。一邊玩玩看一邊增進自己的實力吧!
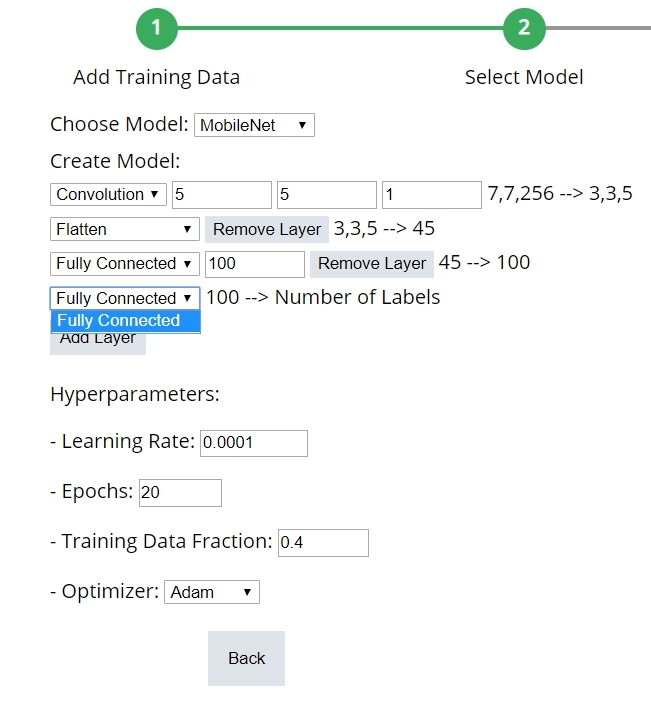
(圖片來源:CAVEDU提供)
c. 調整超參數
一些名詞如果還不熟就先放著吧,但 Epochs (訓練回合數)是一定要理解的,訓練愈多次理論上會有更好的準確度,但是所需的時間也會愈久。

(圖片來源:CAVEDU提供)
d. 訓練
按下 step(2) 右下角的 [Train Model] 按鈕就會根據先前的設定與提供的資料進行訓練,可以看到訓練時間與 loss(評估神經網路成效的指標之一)。訓練速度當然不算快,請稍等一下囉!

(圖片來源:CAVEDU提供)
3. 加入測試資料
訓練完了要考試才知道成效如何。請加入測試資料(最好是未用於訓練的資料)。您可以換一個背景試試看偵測的效果如何。請上傳照片或使用 webcam 拍照,完成後按下 [Predict] 按鈕,會直接跳到(4)。
4. 檢視結果與下載神經網路模型檔
這個步驟會看到您所提供測試資料的驗證結果,如下圖右側可以看到正確識別為 STOP 與 RIGHT,對應的信心參數也可以看到。畫面左下角的 Lablel Correctness 與 Confidence Graph 是告訴您哪些辨識成功與失敗,以及信心程度的分配情形。
如果您對於本次訓練結果不滿意的話,就要回到先前步驟增加更多訓練資料或調整神經網路模型才能得到更好的結果。存檔副檔名為 .mdl。要匯入到後續的 app 專案中。
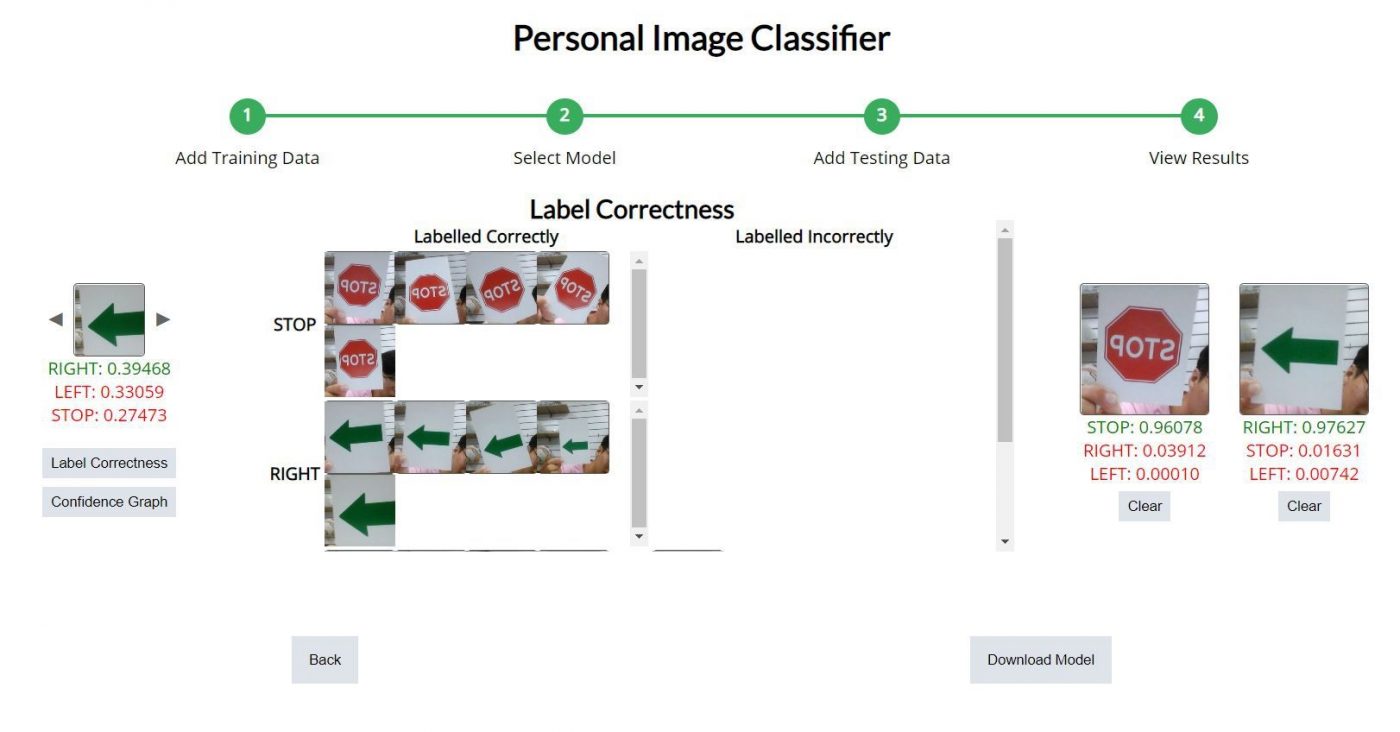
(圖片來源:CAVEDU提供)
匯入訓練好的模型
請用我們寫好的 .aia 吧,已經載入了 PersonalImageClassifier 這個元件,請點選它的 Model 欄位後上傳訓練好的模型檔即可。
按照這樣的架構,只要在 app 允許的專案大小之下,可以針對專案需求來切換不同的模型檔。但目前無法動態切換,在元件屬性調整之後要重新打包才行。
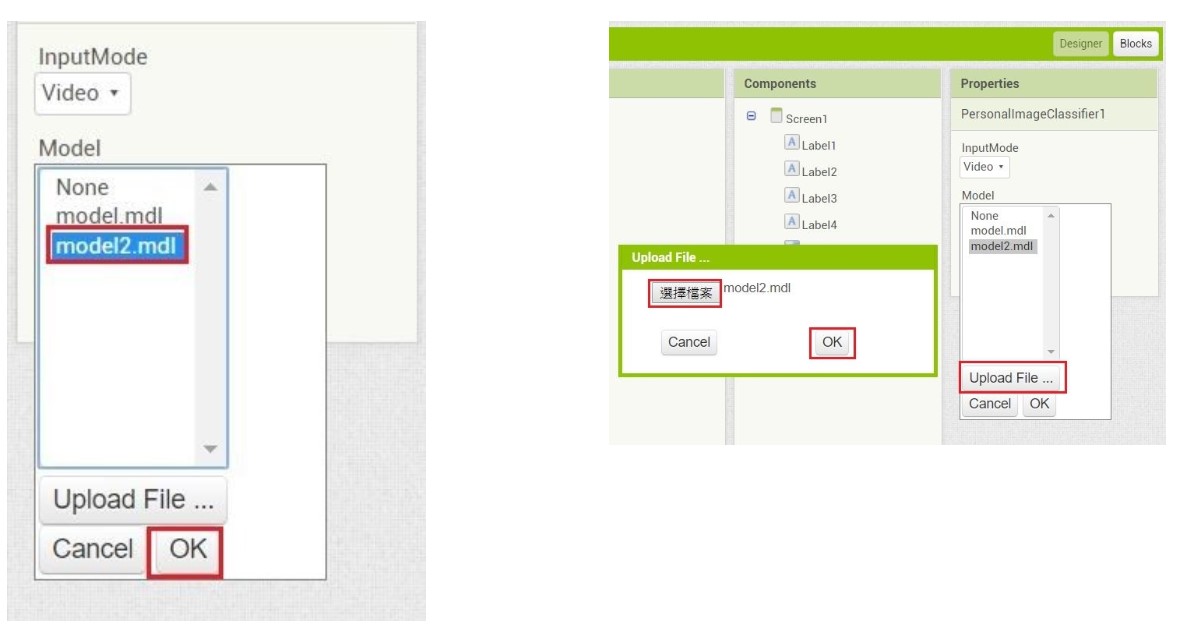
(圖片來源:CAVEDU提供)
執行畫面
由下圖可以看到不同畫面的辨識結果,好感動啊!下一步就是要讓手機根據辨識結果來控制機器人,是不是很棒呢!

(圖片來源:CAVEDU提供)
重要 Blocks 說明
本範例關鍵在於上述訓練模型的網頁,匯入模型檔之後 app 寫起來相當輕鬆,記得載入您訓練好的模型檔即可。
按下按鈕之後會呼叫 PersonalImageClassifier.ClassifyVideoData 來辨識連續影像。您也可以改用 .ClassifyImageData 來辨識單張照片,端看您的需求。接著在 ClassifierReady 事件中呼叫 .GetModelLabel 取得辨識結果。
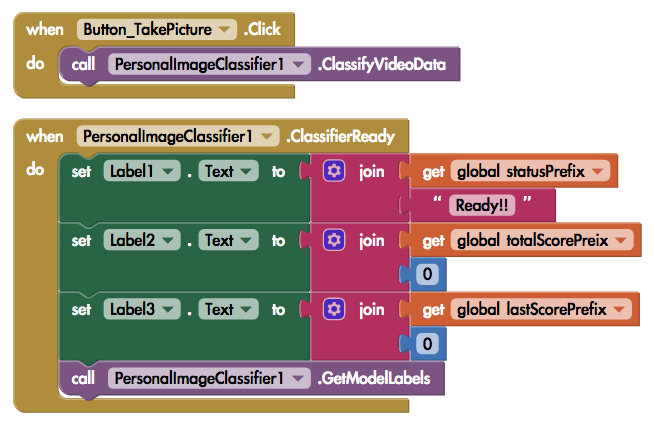
(圖片來源:CAVEDU提供)
在 .GotClassification 事件中,先取得 result 清單的第一個元素(label name),再根據第二個元素(信心指數)顯示對應的結果。
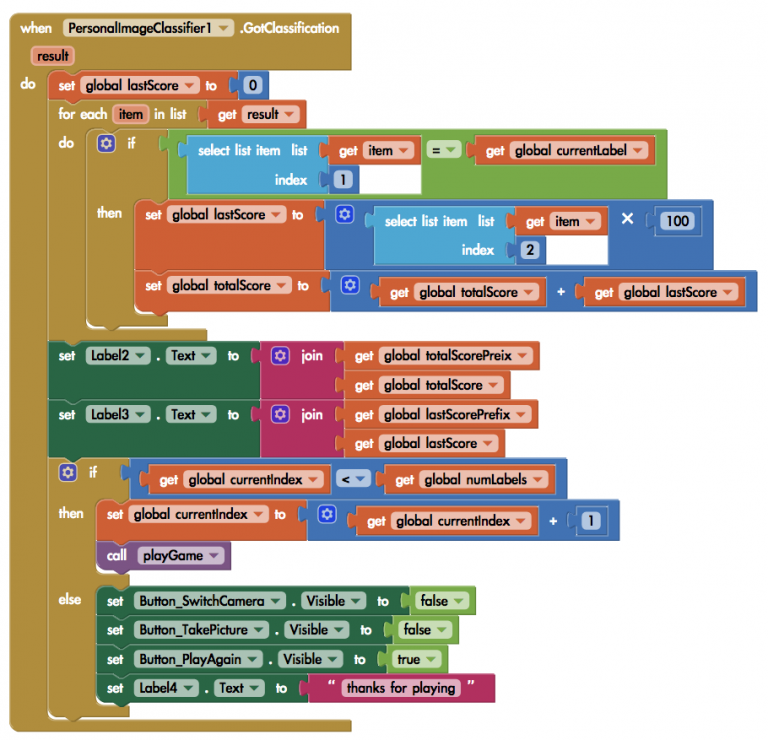
(圖片來源:CAVEDU提供)
(本文轉載自 CAVEDU 教育團隊、原文連結;責任編輯:楊子嫻)

- 【CAVEDU講堂】micro:bit V2使用TCS34725顏色感測器模組方法 - 2025/06/27
- 【CAVEDU講堂】NVIDIA Jetson AI Lab 大解密!範例與系統需求介紹 - 2024/10/08
- 【CAVEDU講堂】Google DeepMind使用大語言模型LLM提示詞來產生你的機器人操作程式碼 - 2024/07/30
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


