作者:DT42/DeepThought
本文譯自 Alasdair Allan 的 Benchmarking Machine Learning on the New Raspberry Pi 4, Model B 的 Part I — Benchmark,用意是讓更多中文讀者也能快速了解 AI 模型在 Raspberry Pi 4 上的效能測試結果,如果覺得文章還不錯,或是對 Part II — Methodology 有興趣的讀者,除了幫我們的中文翻譯版拍拍手,也別忘了回到原始英文版給作者一些 claps 喔!
Raspberry Pi 4 熱騰騰上市,想必大家都很好奇 AI 模型在 Model B 上的運算效能相較之前的硬體快了多少?答案是 — 真的快很多。
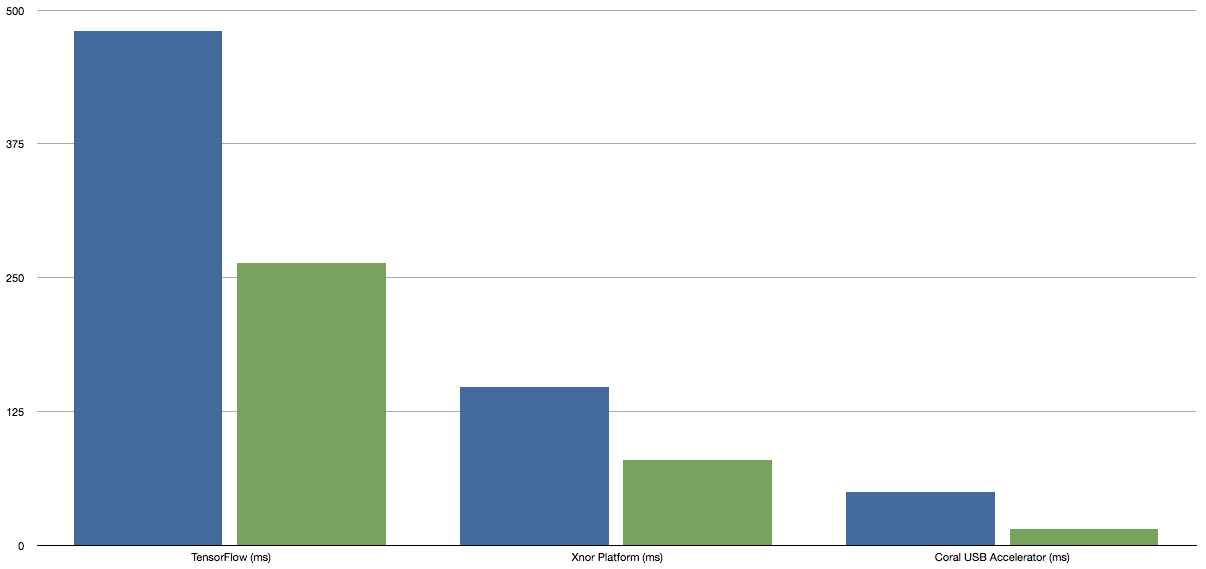
Raspberry Pi 3(藍色,左側)與 Raspberry Pi 4(綠色,右側)的 inference 時間(毫秒)(圖片來源:source)
上個月科技部落格作者 Alasdair Allan 把幾台常見的 Edge 硬體跟上一代的 Raspberry Pi 拿來做比較。評估出來的結果,發現比預期的運算能力慢了許多。根據 community 的修正,不是硬體本身的問題,而是選錯了軟體。因為沒用 Tensorflow Lite,而是用了比較慢的 Tensorflow,才造成這麼明顯的運算時間落差。
由於最近 Xnor.ai 新釋出的 AI2GO 使用了新一代的二元權重(Binary Weight)模型,因此,作者 Allan 也將此模型加入比較,發現這些新一代的模型確實比「傳統」的 TensorFlow 快了不少。
不過,計畫趕不上變化,在此同時又新出了 Raspberry Pi 4B,於是,Alasdair Allan 重新做了一次效能測試,想看看新款 Raspberry Pi 4 的速度比前一代快多少。結果一如預期,新的真的比較快。
總體來說,新的 Raspberry Pi 4 比前代的Raspberry Pi 3 快得多。更詳盡的 AI2GO 平台的測試請參考這裡。
不管是原始 TensorFlow 或者 Xnor AI2GO 平台的 inference 運算基準測試,皆達到約 2 倍的效能改進。

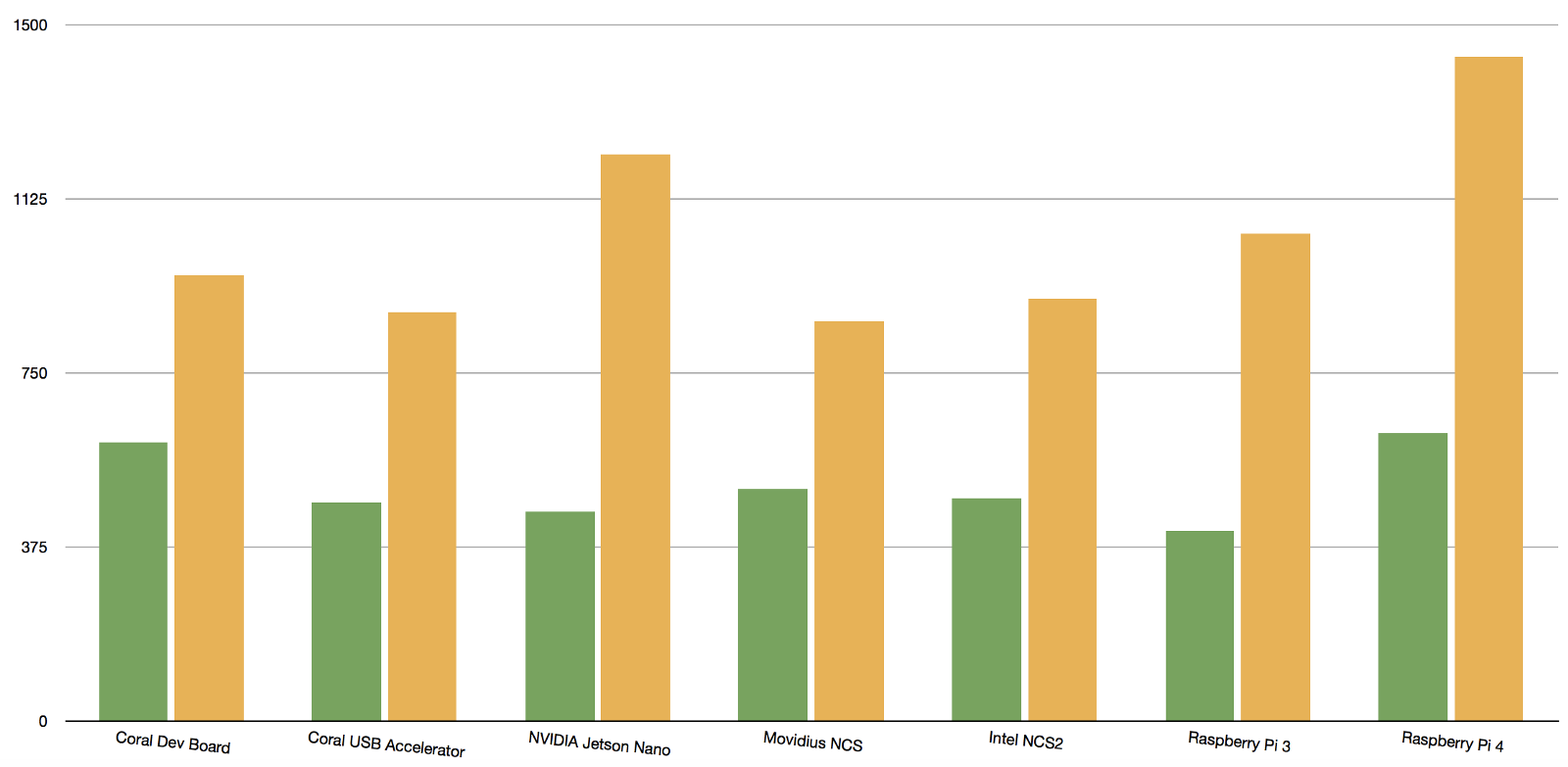
這是 MobileNet v1 SSD 0.75 深度模型和 MobileNet v2 SSD 模型的基準測試結果(以毫秒為單位),兩者均使用 COCO 資料集進行訓練,輸入影像尺寸為 300×300,運行在 Raspberry Pi 3B+( 左)和新的Raspberry Pi 4B(右)(圖片來源:source)
更有意思的是,從 Google 的 Coral USB AI 加速器的基準測試,我們可以看到相當大幅度的進步,這與 Raspberry Pi 4 新增的 USB 3.0 有關,比起連接 USB 2.0,整體的運算效能提昇了 3 倍。
反之,如果把相同的 Coral USB AI 加速器連接到 USB 2 而不是 USB 3,在相同硬體、相同模型的比較基準之下,整體運算效能與 Raspberry Pi 3 相比卻反而慢了 2 倍。對於這個結果讓 Allan 有點訝異,因為單單只是改善系統架構,整體的運算就會因此改變。
對於效能測試的結果,Eben Upton,Raspberry Pi 基金會創始人是這樣說的:「這顯示了 NEON 運算效能的提昇,以及採用 USB 3.0 所帶來的好處。儘管我們變更 USB 設計原意,其實是為了讓使用者能連接更大容量的保存設備,不過能看到這個設計在額外的應用獲得改善很有趣。」
效能測試
更深入的分析
Raspberry Pi 3 上的測試是基於 TensorFlow 與 Tensorflow Lite 且運行在Model B + 上,Raspberry Pi 4 的效能測試採取了相同的軟體配置,硬體則使用了 Model B 配上 4GB RAM。
Inference 的模型是使用 MobileNet v2 SSD 以及 MobileNet v1 0.75 深度 SSD 來進行,兩者都是基於 COCO 資料集所訓練而成。
以上的測試配置同樣也應用在今年新出的 Coral USB AI 加速器,並比較了 USB 2.0 與 USB 3.0 的差異。
補充資訊
原始的效能測試比較了 Coral Dev Board、NVIDIA Jetson Nano、Raspberry Pi 3B+ 加上 Coral USB Accelerator、RPi 3B+ 加上第一代 Intel Movidus Neural Compute Stick、以及 RPi 3B+ 加上第二代 Intel Neural Compute Stick,還有生產於 2016 年、作者自己的 Apple MacBook Pro(四核2.9 GHz Intel Core i7),並以無加速配備的 RPi 3B+ 當作標準。
Xnor.ai AI2GO 平台的效能測試使用的是廚房物體偵測模型。此模型是一個二元權重模型,雖然訓練資料集並沒有公開,但 Xnor.ai 提供了技術論文讓使用者參考。
測試用的原始影像是一張 3888×2916 像素的照片,其內包含一條香蕉 🍌 和一顆蘋果 🍎 。作者將此影像的尺寸調整為 300×300 像素並反複運行 inference 模型 10,000 次,最後取得平均 inference 時間。
由於 TensorFlow 模型第一次使用時要預載,因此,第一次 inference 運行的時間並未被算在平均之內。
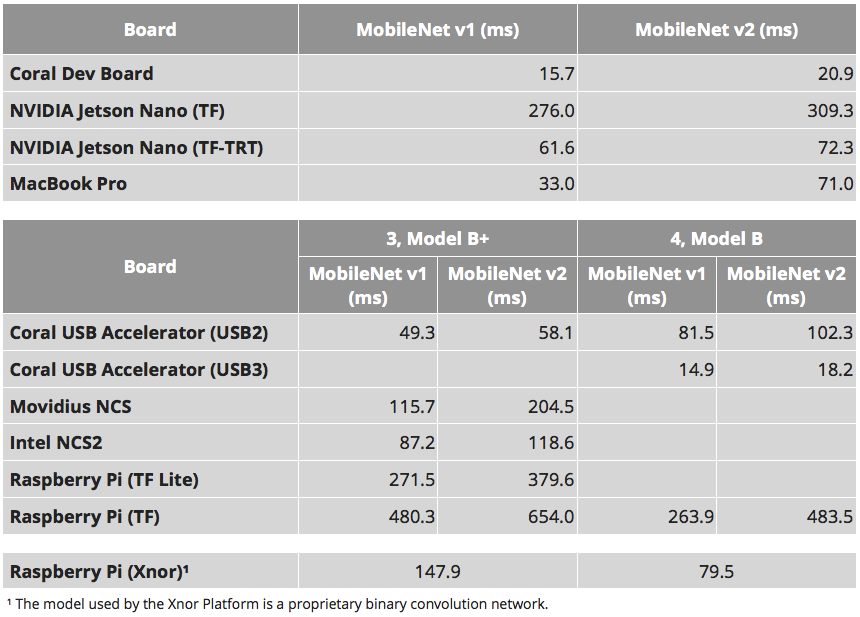
MobileNet v1 SSD 0.75 深度的模型以及MobileNet v2 SSD 模型都是以 COCO資料集進行訓練,模型的輸入尺寸為測300×300(圖片來源:source)
溫馨小提醒
在測試過程中,為了運行 TensorFlow 、 AI2GO 以及 Coral USB AI 加速器,作者必須更新 RPi 上的 Raspbian 系統從 Stretch 升級到 Buster,也就是等於安裝的 Python 版本 將會從 Python 3.5 升級到 3.7。
這個改動可能會造成 TensorFlow Lite,Movidus Neural Compute Stick 或 Intel Neural Compute Stick 2 無法運行。雖然 TensorFlow Lite 的問題可能很容易解決,但如果你想要使用 Intel OpenVINO 框架就沒這麼輕鬆了,需要花一點時間才能從 Python 3.5 移到 3.7 才能使用,可能會造成 Raspberry Pi 4 在短時間無法和 Intel Neural Compute Stick 搭配使用。
大致說來,如果是運行在 CPU 上的模型,在新款的 Raspberry Pi 上至少都能獲得兩倍的效能增長。
與 Raspberry Pi 3 相比,RPi 4 的 NEON 容量大約是其兩倍。基於良好實做的 NEON 核心,以及解決溫控調頻問題,在 MobileNet v1 模型和 Xnor.ai AI2GO 框架運算獲得兩倍加速是符合預期的結果。
AI2GO 平台二元權重模型在未加速的 Raspberry Pi 4上,達到 inference 時間為 79.5 毫秒。性能足以與 2016 年的 MacBook Pro 匹敵(跑 MobileNet v2 SSD inference 時間為 71 毫秒)。
但是比較起來,MobileNet V2 模型的效能改進就小得多,表示 v2 模型在 TensorFlow 中運作時,某些運算的最佳化仍有改善空間。
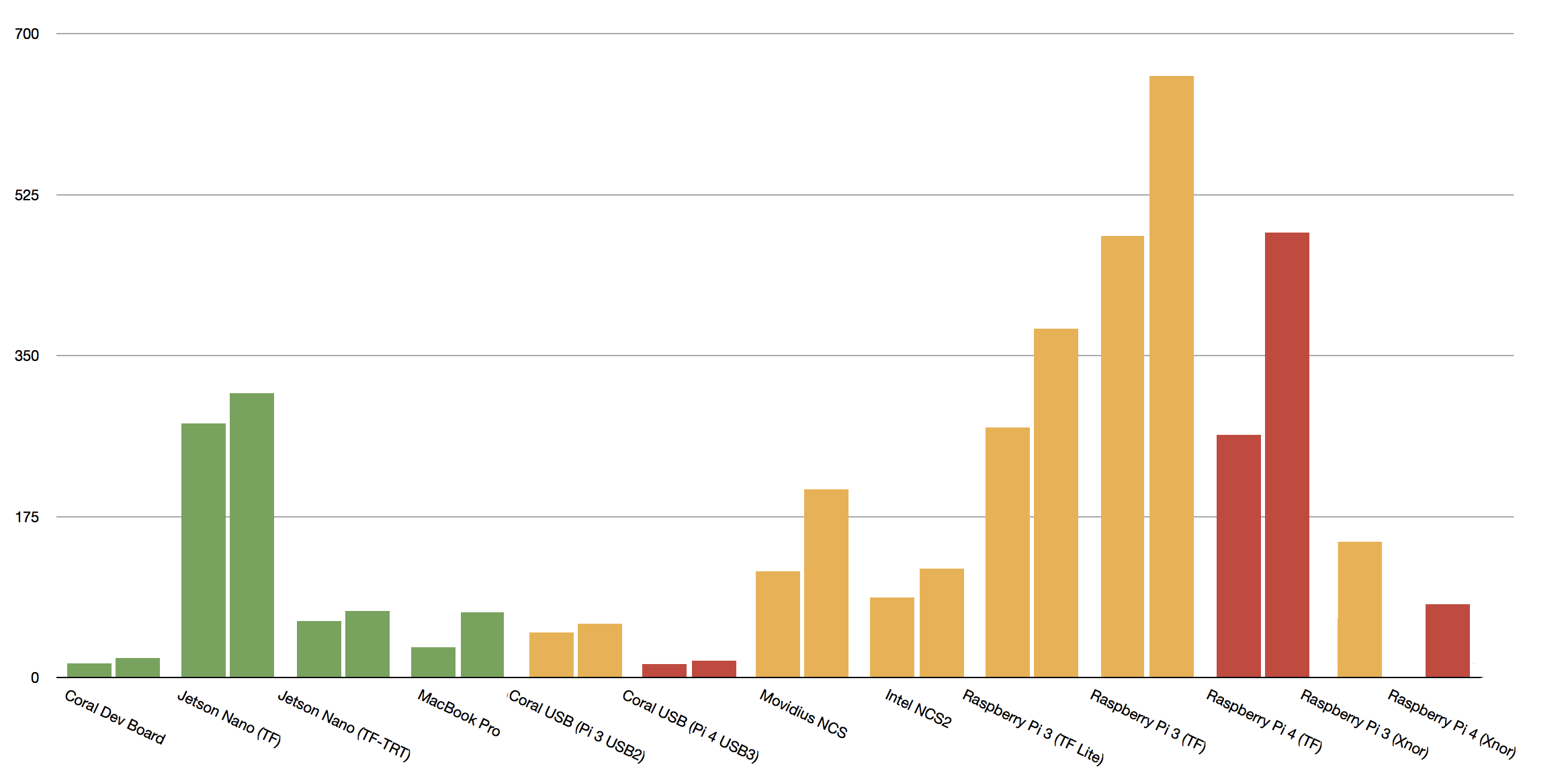
用於 MobileNet v1 SSD 0.75 深度模型(左方)和 MobileNet v2 SSD 模型(右方)的 Inference 時間(毫秒),均使用COCO資料集進行訓練,模型輸入大小為 300 ×300。Xnor AI2GO 平台的使用的是其專有的二元權重模型。Raspberry Pi 3B+ 的所有測試結果為黃色,Raspberry Pi 4B為紅色。其他平台則是綠色(圖片來源:source)
由於升級到 Python 3.7 的時候,wheel 包出現了一些問題,導致 TensorFlow Lite 的 inference 測試無法型,不過 Allan 估計 RPi4 的性能大概是 RPi3 的兩倍。
對於想使用 Raspberry Pi 4 進行 inference 的使用者,最大的收穫大概是 Coral USB AI 加速器比運行在 Raspberry Pi 3 上的效能增加了3倍。
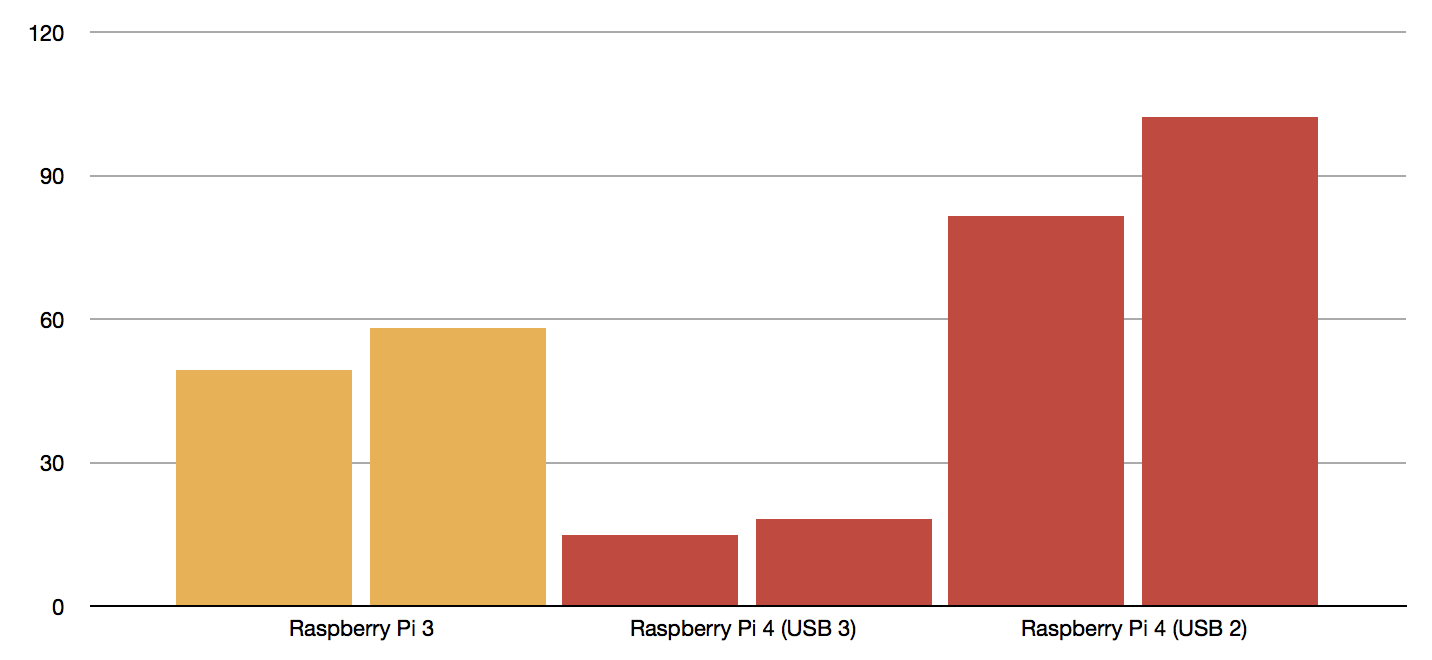
使用 MobileNet v1 SSD 0.75 深度模型和MobileNet v2 SSD 模型的 Coral USB AI 加速器的效能的測試結果(毫秒),兩者均使用Raspberry Pi 3B +(左)的COCO資料集進行訓練,和Raspberry Pi 4B USB 3.0(中)和USB 2(右)(圖片來源:source)
根據測試結果, MobileNet V1 0.75 SSD 模型的運行速度從 49.3 毫秒降低到 14.9 毫秒,MobileNet V2 SSD 模型也從 58.1 毫秒降低到 18.2 毫秒。換句話說 Raspberry Pi 4B加上 Coral USB AI 加速器(配合USB 3.0)整體的 inference 時間低於 Coral Dev Board(15.7 和 20.9 ms)。
但很奇妙的是:如果透過 USB 2.0 來連接 Coral USB AI 加速器而不使用 USB 3.0,inference 時間較Coral Dev Board 卻又慢了兩倍,這是因為 XHCI host 位於 PCIe bus 的遠端,因此可能有較長的延遲。而對於傳輸通道的使用,阻塞模式較串流模式來得慢。
補充資訊
作者使用了 4GB 的 RPi 4B,但若換成 1GB 或 2GB RAM 的 Raspberry Pi 4主板加上 Coral Dev Board,仍可預期得到相同或近似的效能測試結果。
環境因素
雖然 inference 速度對於運行 edge AI 的裝置優劣可能是最重要的衡量標準,但我們還是要同時考慮散熱與能耗,畢竟要達到最佳的運算速度,還是需要在各方因素中做取捨。
電量消耗
電流測量使用了透過 USB 線連接的萬用電表進行,精度為 ±0.01 A(10mA)。電流消耗的閒置值與峰值,分別代表能耗測試進行前與進行中。所有透過 USB 連接的加速器的測量,均基於 Raspberry Pi 3B +。
除了 MacBook Pro 外,所有平台都採用標準 5V 輸入電源。但實際上由於電路板的要求,電壓會在一定程度上震盪,大多數 USB 電壓實際上位於 +5.1 到 +5.2V 左右。因此,作者選擇了 +5.15V 作為功率計算(以瓦特為單位)的標準。
尤其是使用週邊設備時 Raspberry Pi 的能耗會震盪。也是應為這個原因,許多手機充電器無法很好地透過 micro USB 提供穩定的電流。這也是 Raspberry Pi 從 micro USB 轉向標準 USB-C 的原因之一。
峰值電流(黃色,右方)與閒置電流(綠色,左方)的比較(圖片來源:source)
在之前的效能測試中,Raspberry Pi 3B + 相對耗電,耗電的程度只輸給 NVIDIA Jetson Nano。新的測量顯示,Raspberry Pi 4 是所有 edge AI 平台中最耗電的,在峰值需要超過 1,400mA。閒置時的能耗也最高,比 Coral Dev Board 所需的電量還高。
發熱與散熱
在之前的測試中,Raspberry Pi 溫度接近但不超過 80°C (如果超過,CPU 會自動進行熱量節流)。
第一次進行 AI2GO 效能測試時, inference 時間為 90.9 ms,遠遠高於預期。然而在測試的過程中,作者發現溫度遠高於溫控調頻的門檻值。
在幫 Raspberry Pi 自帶的 GPIO 加一個小風扇後,才讓 CPU 溫度保持在 45°C。

一個小風扇就足夠讓 CPU 的溫度保持穩定(圖片來源:source)
穩定 CPU 溫度後,inference 時間從 90.9 ms 下降到 79.5 ms,比較接近預期結果。
由於在測試期間必須主動冷卻 Raspberry Pi,若長時間使用它進行 inference,作者建議至少添加一個被動散熱片。如果想要避免 CPU 溫控調頻的限制,裝個小風扇可能是個好主意。
小結
新的 Raspberry Pi 4 帶來的性能提升,使其成為極具競爭力的機器學習 inference 平台。透過效能測試,RPi 4B 使用 AI2GO 平台的二元權重模型的 inference 時間足以跟 NVIDIA Jetson Nano 和 TensorRT 優化的 TensorFlow 模型相匹敵。而加了 USB 3.0 後,讓 Raspberry Pi 不僅是運算效能有競爭力,價格競爭力亦能與同類最佳的 Google Coral Dev Board 相匹敵。
售價 35 美元的 Raspberry Pi 4 的 1GB 版本比 149 美元的 Coral Dev Board 便宜得多。結合 74.99 美元的 Coral USB AI 加速器與 Raspberry Pi 4 ,意味著您可以以 109.99 美元的價格超越之前的「同類最佳」主板。性能不但超越 Coral Dev Board,還可以省下 39.01 美元。
(本文經同意轉載自DT42 Medium、原文連結;責任編輯:楊子嫻)

- Molex強化次世代AI資料中心基礎設施技術支援 - 2026/06/23
- 結合TAIWAN AI RAP平台資源 國研院推賦能方案及實戰工作坊 - 2026/06/18
- Nordic以超低功耗邊緣AI與無線連線技術引領物聯網創新 - 2026/06/16
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


