作者:陸向陽
人工智慧的計算機領域在機器人、控制系統等皆獲得廣泛的應用,AI 晶片市場因而快速成長。本篇文章介紹人工智慧演算原理、比較各推論晶片的格式與效能。
回顧 2018 年的人工智慧(AI)技術發展,有一個很大的重點在於推論型(Inference)人工智慧晶片的出現,包含 Google 推出 EdgeTPU、NVIDIA 推出 T4,以及 AWS 提出 Inferentia(僅揭露資訊,晶片尚未問世)。在 2018 年以前較知名的推論(或稱為推演、推算)用晶片是 Intel 的 Myriad 系列,該系列已歷經三代,即 Myriad(已停產)、Myriad2 以及 MyriadX,最初是 Movidius 公司獨立發展,之後 Intel 於 2016 年購併 Movidius 後接續發展。
AI 運算的訓練與推論
人工智慧運算主要分成兩個階段,一是訓練階段,即是透過大量的資料餵入、運算並進行參數調整,從而獲得一個可用的人工智慧運算模型;二是推論階段,即是模型完成後正式用在營運上,進行各種智慧偵測、智慧辨識。換句話說,訓練階段就是一個程式的開發階段(Dev time),而推論階段其實就是程式的執行階段(runtime)。
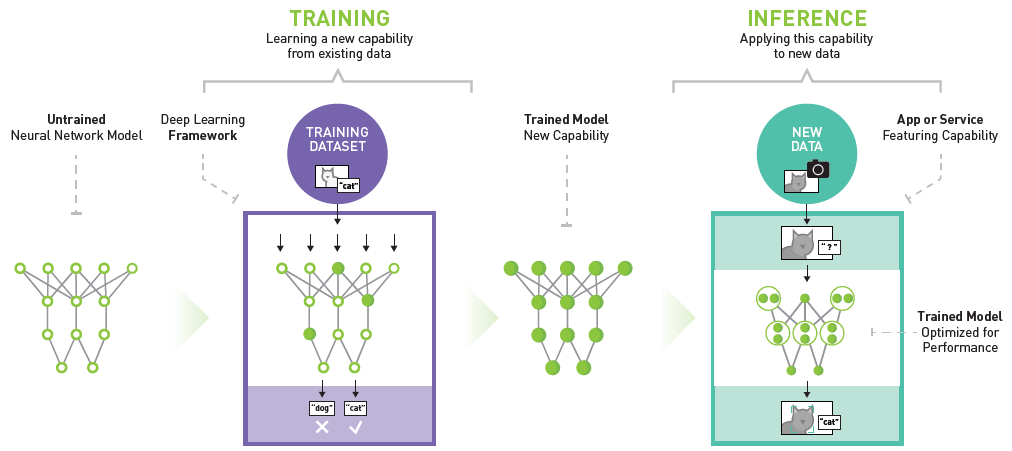
人工智慧運算主要分成兩個階段,一是訓練階段,一是推論階段(資料來源)
若用一個應用來譬喻,例如我們撰寫一個可以辨認貓臉的人工智慧演算法,然後先餵入一萬張各種不同帶有貓臉的照片,由演算法標示出照片中的貓臉位置,初期演算法辨識不佳,但經過開發人員對程式的判別進行調整修正後,辨識度高到一個可接受的程度,演算法即開發(訓練)完成。
而後我們將這套演算法放置在居家門口,用攝影機即時拍攝路口畫面,而後演算法對照片進行有無貓臉的辨識,有則標註起來,這個在前線現場例行執行的工作即是「推論」。當然!訓練也可以再精進,等於是對程式進行增訂修訂等改版動作,好讓辨識更精準,精進後的新版模型也要重新裝設到現場去執行,使推論工作再提升。
而回到晶片層面,人工智慧在訓練階段需要使用的運算力相當大,為了加快運算所以會用上 CPU 之外的加速晶片,例如 GPU、FPGA、ASIC 等,目前 NVIDIA 的 Tesla 系列是最常見的加速晶片,是以 GPU 晶片的硬體電路來加速 AI 運算。
NVIDIA 推出的 Tesla 系列常用於伺服器高效能電腦運算(圖片來源:NVIDIA)
不過,目前加速晶片除了用於訓練外也用於推論,但實際上推論的運算有時比訓練簡單,訓練期間可能需要用比較高精度的資料格式,但在推論時為了快速求解是可以降低精度的,運算力也不用在訓練時那麼強,是可以弱一些的,若用訓練用的加速晶片來執行推論,有時會覺得大材小用,過於浪費電力,所以才開始逐漸有專門只針對推論工作而專精設計的加速晶片出現。
AI 推論運算的計算機概論
眾所皆知的電腦運算的資料格式分成定點(或稱整數)、浮點(或稱小數)兩類,浮點為了達到表達的高細膩度會使用 64 位元、80 位元的寬度來表達,而整數一般用 8/16/32 位元即可。
64 位元的浮點數其實不常使用,有時候只用於一些科學研究運算上,即是高效能運算領域(High-Performance Computing, HPC),甚至一些情境下只會用 32 位元的浮點數好加快運算結果,為了簡單區分兩種不同表達細膩度的浮點數格式,64 位元一般稱為雙精度(Double Precision, DP),32 位元稱為單精度(Single Precision, SP)。浮點數除了用於 HPC 外也用於 AI 訓練,一樣會用到 DP 或 SP,有時用 SP 即足夠。
進一步的,前面提到 AI 推論時其實不用很精確,精度其實再降低,這時就有了 16 位元浮點數,稱為 FP16(FP=Float Point),由於位元數再降低,因而有了半精度的稱呼(Half Precision, HP)。
再進一步的,AI 推論運算有時會同時使用兩種不同格式,例如既使用16位元浮點數也使用 32 位元浮點數,同時運算 FP16 與 FP32,這時就會稱為混精度(Mixed Precision, MP)。雙精度、單精度是長久以來即有的用詞,而半精度、混精度是 2016 年新一波 AI 技術熱潮興起後才常見的詞。
不僅是降低浮點數的位元數,推論運算甚至可接受更低的精度,降成整數,因而有了 16 位元整數、8 位元整數、甚至是 4 位元整數的出現,稱為 INT16、INT8、INT4(INT=Integer)。
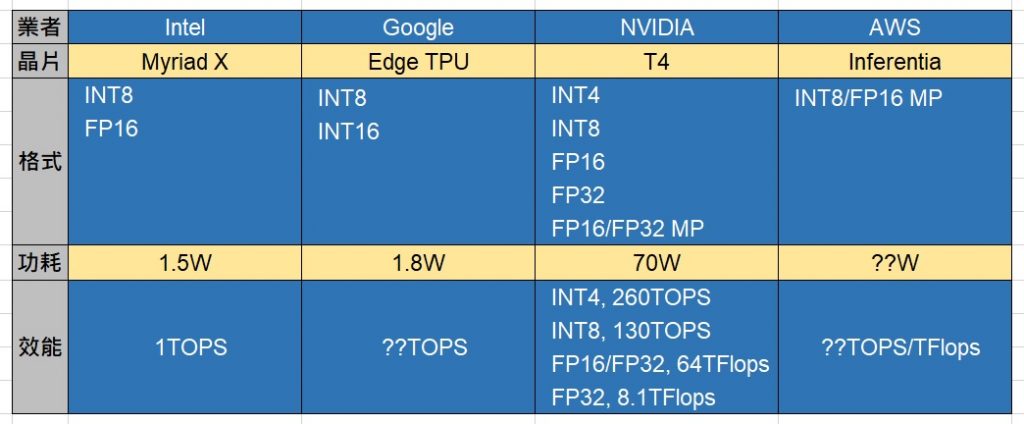
推論型人工智慧加速晶片比較表
了解這些後對應到前述的推論晶片,Intel Myriad X 可以原生支援 8 位元整數、16 位元浮點數的 AI 推論運算,Google Edge TPU 一律是整數運算,但有 INT8、INT16 之分,NVIDIA T4 支援多種格式,甚至可混用 FP16、FP32,尚未問世的 AWS Inferentia 則可以混用 INT8、FP16。
在效能方面,整數運算是以 OPS 為單位,浮點運算則以 Flops為單位,Intel Myriad X 推算運算的效能可達 4 TOPS(每秒4萬億次)以上(應是指 INT8),Google Edge TPU 與 AWS Inferentia 則尚未公佈其效能。至於 NVIDIA T4 則依據不同格式有不同的效能,若為最簡單的 INT4 格式可以達 260 TOPS 之高,反之 FP32 格式精度最高,效能也降至 8.1 TFlops。
推論專用晶片耗電量比較
雖然推論專用晶片就是為了省電與推論運算的專用加速而設計,但 Intel、Google 的晶片是訴求在前端使用,例如裝設在門口、櫃檯等,或者攜帶使用,所以不希望晶片太耗電,最好用電池也能使用很長一段時間,因此Intel Myriad X耗電約 1.5W(Watt,瓦)、Google Edge TPU約為1.8W(協力業者透露約 1.8W,Google 官方未揭露)左右,但 Tesla T4 依然訴求在機房內使用,只要比本來的 Tesla 精省電力即可,所以依然要 70W 電力,至於 AWS Inferentia 也資訊未明,若也是用於機房,估計也是數十瓦用 電的晶片,絕非 2 瓦之類的小晶片。
小結
推論專用晶片的出現也意味著 AI 運算需求已逐漸站穩腳步,不再單純試驗、評估,是真的能用於營運現場的,或者說科技大廠們認為這樣的市場即將到來,並對此先行準備。
(責任編輯:葉于甄)

- Windows PC上安裝PicoClaw最基礎實務 - 2026/03/03
- 跟上「龍蝦」潮了嗎?xClaw旋風現象觀察與後續 - 2026/02/26
- MakerPRO「2025台灣Edge AI開發者調查」初探 - 2026/02/11
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!



2019/02/17
A good introduction