作者:許哲豪 Jack
語音助理發展至今,儼然已成了「超級紅海」,但下一個「藍海」在那裡呢?會是帶著顯示器的語音助理,甚至是擁有分身代理(Avartar Agent)具像化的虛擬(偶像)助理嗎?接下來就從應用場景、關鍵技術及市場趨勢來為大家說明。
應用場景
2011年Apple首先將語音助理Siri變成旗下iPhone等系列產品的標準功能,使用者可直接用語音查詢天氣及採購商品,還能陪你聊天。Amazon在2014年推出Alexa更進化到可以用語音控制家電,使得智慧家庭得以實現。而Google也不干示弱於2016年加入這個戰場,推出Google Home系列產品來應戰。加上大陸及台灣大廠及新創團隊的加入,語音助理這塊餅是越來越大,影像式的AI虛擬助理也逐漸出頭,先從電影裡一探AI虛擬助理的應用吧!
常看科幻電影的朋友,對2002年「時間機器」中圖書館員的橋段應該不陌生:1889年的亞歷山大駕著自己開發的時光機到了2030年的圖書館中想查資料,卻被眼前看似玻璃的顯示器中突然出現的虛擬圖書館員(VOX-114)嚇了一大跳,不但可以用真人形象出現,更能用流利的口語及豐富的表情和亞歷山大對話。

電影「時間機器」虛擬圖書館員場景(圖片截圖來源:https://youtu.be/CQbkhYg2DzM)
查詢到的資料更能以影像呈現,對於想進一步了解的資訊更能以圖文、影片及語音說明,對於相同關鍵字推薦內容不是想要的也能馬上更換,因為其背後可連結到全世界所有的數據資料庫。

查詢到的資料以影像呈現(圖片截圖來源:https://youtu.be/CQbkhYg2DzM)
日本知名長夀電視影集「世界奇妙物語」2014年推出一部非常具有未來感的影片「廢材的他和可愛的她」,主要描述政府為解決單身男女不婚問題,設置專門供單身男女居住的公寓,入住後輸入自己喜好,會出現一個全息投影,真人尺寸的智能虛擬管家,除了協助居家生活所需的技能外,更會像一位貼心的男(女)朋友給予生活及工作上的建議,陪你渡過各種高興和不如意的情境。

電視影集「世界奇妙物語」虛擬管家場景(圖片截圖來源:https://youtu.be/ideWNy-TfA4)
關鍵技術
雖然上述場景目前仍有許多技術仍在發展中甚至難以實現,但這裡還是就所需要的關鍵技術及會遇到的問題簡單介紹一下,主要分為自然語言處理(Natural Language Processing)、電腦視覺辨識(Computer Vision Recognition)、虛擬代理呈現(Virtual Agent Presentation)及真實場景互動(Real Scene Interaction)等四大領域技術。
1. 自然語言處理
這部份技術包括語音轉文字(Speech to Text)、文字(意圖)分析(Text/Intent Analysis)、語言/情緒理解(Language/Emotion Understanding)、語句合成(Sentence synthesis)、文字轉語音(Text to Speech)等技術。雖然這部份目前已較為成熟普及,但仍有許多地方有待突破。比方說語音轉文字部份在不同年齡、地區口音(腔調)及多語系(中/英/台)混合時常會誤判,轉換好的文字在相同字詞上下文搭配不同時容易造成意圖誤解等。
而在長語句或文章的語言及情緒內涵,常會受反串文(明褒暗諷)誤導,中文更是容易受標點符號位置、斷詞及前後文排列方式甚至語氣產生語義誤解。比方A問:「你對台大校長的事怎麼看」,B回答:「不要管」,此時電腦(人工智慧)就很難判讀究竟B想表達是叫A不要管這件事,還是B在表達不想要管先生接任校長。當語義判讀完成後,產生回應句子的通順性及相同問題是否能產生些許差異,更接近口語化亦是重點。
最後,文字轉語音的技術當然是要把句子讀的通順,且更接近人類說話時的抑揚頓挫,才不會讓人一聽就像機器人在說話從頭到尾都是平平的語調。以上這些問題也是成為大家努力突破的地方。
2. 電腦視覺辨識
這部份技術涵蓋範圍相當廣泛,主要以人機互動(Human Machine Interaction, HCI)為主,包括人臉身份/表情(Face ID/Expressions)、頭部姿態(Head Pose)、視點位置(Gaze Point)、手勢肢體動作(Gesture/Body Action) 、場景/物件辨識(Scene/Object Recognition)、物件定位/分割(Object Location/Segmentation)、三維場景重建(3D Scene Reconstruction)等技術。首先虛擬助理必須了解使用者是誰,站在機器的那個位置(方向及距離),正看著顯示幕上的那個位置或那個物件,當互動時使用者的表情如何,以確認虛擬助理應該產生的反應或回答。

電腦視覺辨識(圖片來源:Nextep)
接著,要能理解使用者互動時的手勢(移動軌跡、外形輪廓等),包括點擊確認、滑動切換、旋轉快進、放大縮小、手指(拳頭)夾取放開甚至能看懂手指彎折後比出的數字或文字。除了手勢外,肢體動作也是非常重要,這也可看成對使用者行為模式的判定,包括靜態的坐、立、臥姿態及連續動作的行走、跌倒、徘徊踱步、點頭搖頭等。
最後,還要能理解目前所在地的三維場景及物件位置、數量、外形輪廓都要能正確識別出來,這樣才能確認使用者在場景中作了什麼動作、拿了什麼東西。另外,更進階甚至還可加入紅外線熱感影像,感測使用者的體溫變化,以了解使用者的健康或情緒狀況。
3. 虛擬代理呈現
在一般語音助理上不需要這個部份,但具像化虛擬助理如上述電影中的情節,為了讓使用者好像面對真人或虛擬(動漫、電玩、影視)偶像對話,所以必須透過顯示屏幕呈現並與其互動。主要用到電腦圖學(Computer Graphic)技術,包括三維模型建構(3D Model Construction)、材質/燈光(Material/lighting)、語音驅動模型(Voice Driven Model)、動作/表情補捉(Motion/Expression Capture)、物理計算引擎(Physical Computing Engine)及視覺顯示(Visual Display)等技術。
這部份在動畫、廣告、電視及電影工業的驅動下目前已非常成熟,甚至透過現成遊戲引擎(Unity、Unreal等)就可輕易完成建模及互動。首先,要以三維建模軟體(3DsMax、 MAYA等)建立期望對話人物的模型,並貼上材質打上合適的燈光。再來,為了讓模型能看起來會說人話,就必須引入聲音驅動模型(嘴形)模組,使其能依自然語言處理產生的文字串,能依序讀出並驅動嘴形產生開合。
另外,單只有嘴部動作可能太過呆板,還須透過自然語言處理,了解對話內容後加上電腦視覺,辨識出使用者的位置,令三維模型產生頭部移動、視點追蹤、對應的表情、手勢及肢體動作,使模型更像在和真人對話。而這些就需要以傳統的動作/表情補捉技術建構出基本動作/表情元素再合成產生。而物理引擎則會確保虛擬人物在虛擬世界和其它物件產生碰撞時能有正確反應,才不會虛擬人物想去伸手拿個杯子呈現給使用者近看,卻發現手竟然穿過杯子拿不起來。

全息膜投影(圖片來源:https://www.jfdaily.com/news/detail?id=55189)
最後要把所有產生的影像呈現給使用者觀看,最簡單的方式就是顯示在一般LCD顯示幕上。近年來有些開發商開始使用透過透明顯示器或微投影機投影在一種透明的全息膜(Holographic Film)上,顯示內容看似浮在半空中,使模型和真實場景融合,讓使用者更有真實對話的感受。
4. 真實場景互動
近年來受「智慧音箱」及「智慧家庭」市場的急速成長,所以智慧音箱早就以可以輕易地控制家中的燈光、音響、空調等,並可以結合各式環境感測元件偵測使用者所在環境狀態,更能進行線上查詢及採購商品,讓使用者動動嘴就能完成一切。
而這些工作現階段已有廠商將控制、查詢的資訊以文字、圖像、影音等方式顯示在帶顯示屏幕的智慧音箱上。相信下一世代具像化虛擬助理結合更進步的人工智慧技術後,除了可以被動接受命令產生資訊外,更能透過電腦視覺輔助,主動貼心提醒使用者生活習慣、穿搭建議、居家安全並協助心理諮詢、擴增社交網路甚至遠端照護等,讓人機互動能更加順暢。
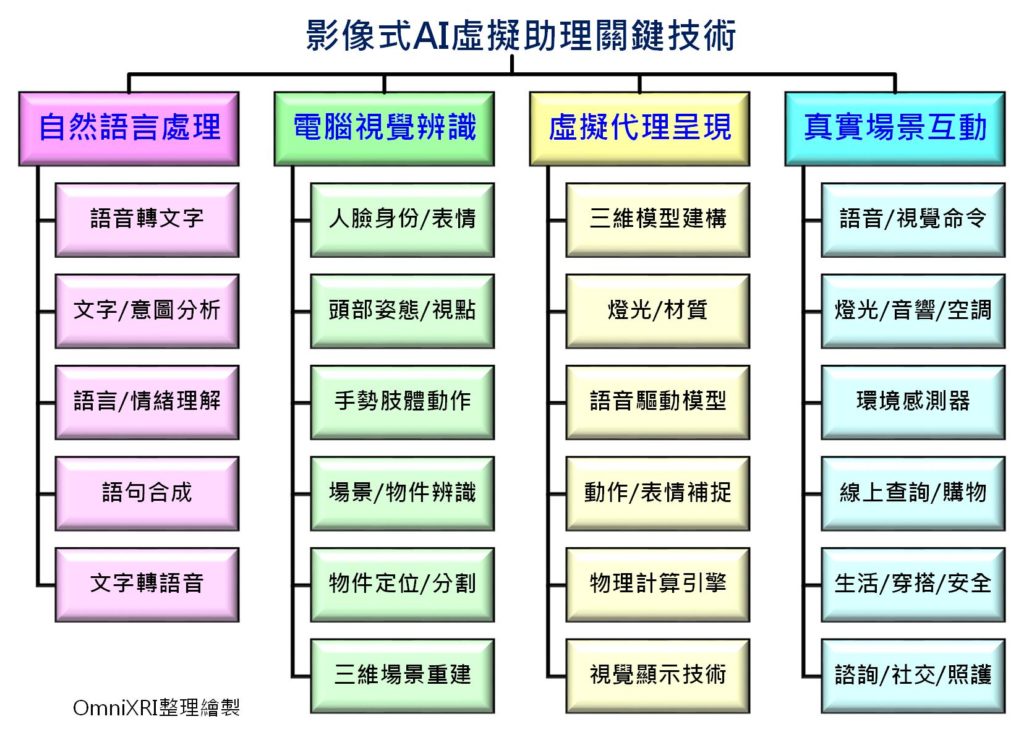
影像式AI虛擬助理關鍵技術 (OmniXRI整理製作)
小結
從電影、電視劇當中我們可以一探人們對於AI虛擬式助理的想像,然而要實現這樣的願景,需要自然語言處理(Natural Language Processing)、電腦視覺辨識(Computer Vision Recognition)、虛擬代理呈現(Virtual Agent Presentation)及真實場景互動(Real Scene Interaction)這四大領域技術才能讓人機的互動更加流暢,更貼近真人之間的互動。
下篇,我們即將要討論現在市場的趨勢為何?概念性的產品又是怎樣孕育而生的?
(本文同步發表於歐尼克斯實境互動工作室、原文連結;責任編輯:葉于甄)

主持歐尼克斯實境互動工作室(OmniXRI):http://omnixri.blogspot.com
Edge AI Taiwan邊緣智能交流區:https://www.facebook.com/groups/edgeaitw/
- 【Arduino UNO Q專欄05】家庭氣象站 - 2026/07/07
- 【Arduino UNO Q專欄04】人臉偵測開關燈具 - 2026/06/22
- 【Arduino UNO Q專欄03】板載點矩陣LED應用 - 2026/06/08
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


