就在剛剛結束不久的農曆新年假期前夕,一款由中國開發的大型語言模型DeepSeek R1正式發布,震撼了美國金融市場,甚至讓NVIDIA的股價應聲下跌。這款AI模型因其卓越的性能和低成本(約600萬美元)引起了投資者的關注,尤其是與OpenAI、Gemini等動輒耗資數億美元開發成本的美國尖端AI模型相較,更是形成了鮮明對比。
針對DeepSeek旋風,一家總部位於美國的AI策略顧問機構Liftr Insights指出,中國對AI的野心遠不只有DeepSeek。根據該公司的研究,截至2024年第四季末,阿里雲與騰訊雲在所有主要雲端供應商中,共佔據31.4%的AI專屬運算實例類型( instance types),而AWS僅佔20.2%,甚至低於阿里雲的單獨占比(參考下圖)。此外截至2024年12月,Hugging Face平台上共有120萬個AI與機器學習模型,其中僅28.4%被標記為自然語言處理(NLP)。
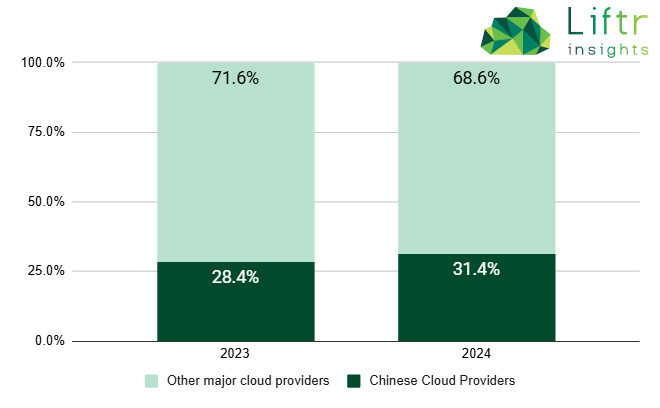
圖片來源:Liftr Insights
Liftr Insights的報告指出,DeepSeek的崛起及中國AI的快速發展,正在挑戰一些普遍的AI認知,重點如下:
- AI並不只有自然語言處理(NLP)
過去兩年來,NLP與通用大型模型獲得了大部分媒體、分析師和投資者的關注。然而,DeepSeek能在超過百萬個AI與機器學習模型中迅速崛起,顯示AI生態遠比想像的更加多元。即便NLP佔據了61.2%的下載量,但這是由少數幾個熱門模型所主導的。事實上,還有約90萬個AI與機器學習模型正在執行各種不同的任務,例如其中有5.6%是專注於電腦視覺(參考下圖)。
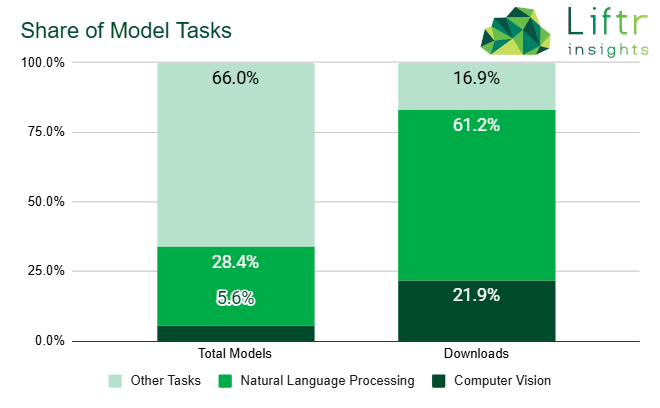
圖片來源:Liftr Insights
- AI模型不一定要「大」才能發揮效能
過去,AI開發往往仰賴巨大的運算資源與龐大的模型參數。然而,DeepSeek採用了蒸餾( distillation )模型技術,這種方法能夠「縮小」模型,使其更小、效率更高,且專注於特定任務。而且不僅是DeepSeek,我們也看到許多小型模型取得優秀成果。例如,IBM的Granite模型可提供不同規模大小的選項,從30億個參數到超過340億個參數不等,以滿足不同專案的需求。根據Liftr Insights的調查,在所有明確標示參數數量的模型中,有90.3%都是以中等規模參數為基礎訓練而成,有些小型模型甚至可以直接在CPU上運作,或是使用如MacBook Pro這類支援GPU的筆記型電腦,當然,具體性能表現可能會有所不同。
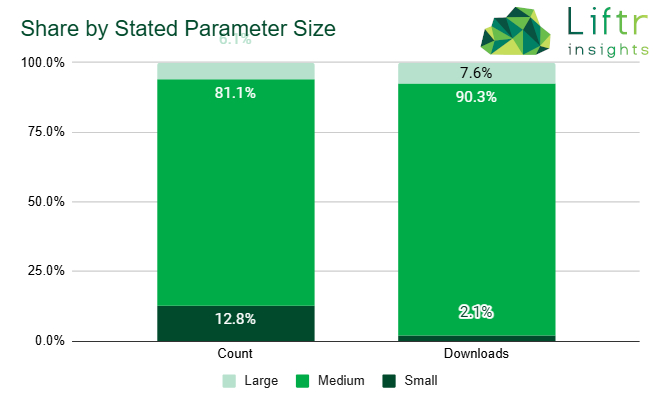
圖片來源:Liftr Insights
- AI的使用不一定要依賴雲端
雲端服務供應商一直在積極投資並推廣AI解決方案,這些供應商有強烈的商業動機來推動AI應用。但Liftr Insights指出,AI專屬運算實例的每小時成本,比單純的CPU實例高出20%到30%。雖然目前AI專屬運算實例佔據所有主要雲端工作負載的6.0%,企業卻不一定只能透過雲端來運行AI模型。包括DeepSeek、IBM、NVIDIA與Meta等公司,都提供既能在雲端運作,也能部署在企業內部資料中心的模型。而隨著小型模型的普及,私有部署變得比以往更加可行。
Liftr Insights也指出,雖然目前有Hugging Face等開放源碼平台提供便利的方式,讓企業能夠輕鬆取得AI模型,但開源AI與機器學習(ML)技術仍面臨與其他開源軟體類似的挑戰——企業需要確保模型的穩定性、可行性,以及是否有足夠的開發者社群支持。因此該機構建議,當企業制定AI策略時,與其單純相信市場的趨勢或大廠的行銷話術,更應該去深入了解各種不同類型的模型與工具發展趨勢,以及其中的互補與競爭關係,才能做出更明智的決策。

- 宇樹、智元出貨囊括八成 預估2026年中國人形機器人產量年增94% - 2026/04/09
- 【科技特寫】一人對決巨頭:Tom Turney與AI夥伴如何在7天內攀越Google技術高牆? - 2026/04/07
- NVIDIA擴展開放模型以推動下一波代理型AI、實體AI與醫療AI發展 - 2026/04/07
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


