
DCGAN 憑空產生的各種虛擬事物是藉由固定維度的 latent space(通常為 100 dim 的隨機常態分配值),產生的特定類型圖像。但如果想要將某一類型的圖片轉換為另一種形式,例如將黑白圖片上色成彩色、將圖片轉成指定風格的畫作、將平面街景轉為立體街景等,這一類的 GAN 模型就不能再使用隨機值的 latent space,而必須使用現有圖像作為 latent space,代表的模型如 CGans(conditional-GAN)與 Pix2Pix(predict from pixels to pixels)。
CGans 與 Pix2Pix 在訓練上最大的差異在於 Pix2Pix 需要的兩類型圖片是成對的(即轉換前與轉換後兩兩成對的相片),而 CGans 也是需要兩大類相片,但並不需要成對,因此在資料搜集上比 Pix2Pix 容易。
本文要介紹與實作的模型是 Pix2Pix,它與 DCGAN 同樣是由兩個相互競賽的模型組成—Generator 與 Discriminator(但有些許的變化);而使用的程式是參考周凡剛老師所開的課程,並作一些修改,使之能應用在本文的範例上。
Generator
虛擬出來的圖片來自另一張圖片,因此 Generator 的 input 不是使用隨機空間而是讀入圖片。首先要進行傳統的 CNN 取得既有的圖片特徵,再將圖片Conv/Pooling,然後進行上採樣(反捲積)成一張新的圖片。Pix2Pix 的 Generator 導入的 U-Net 模型架構如下:
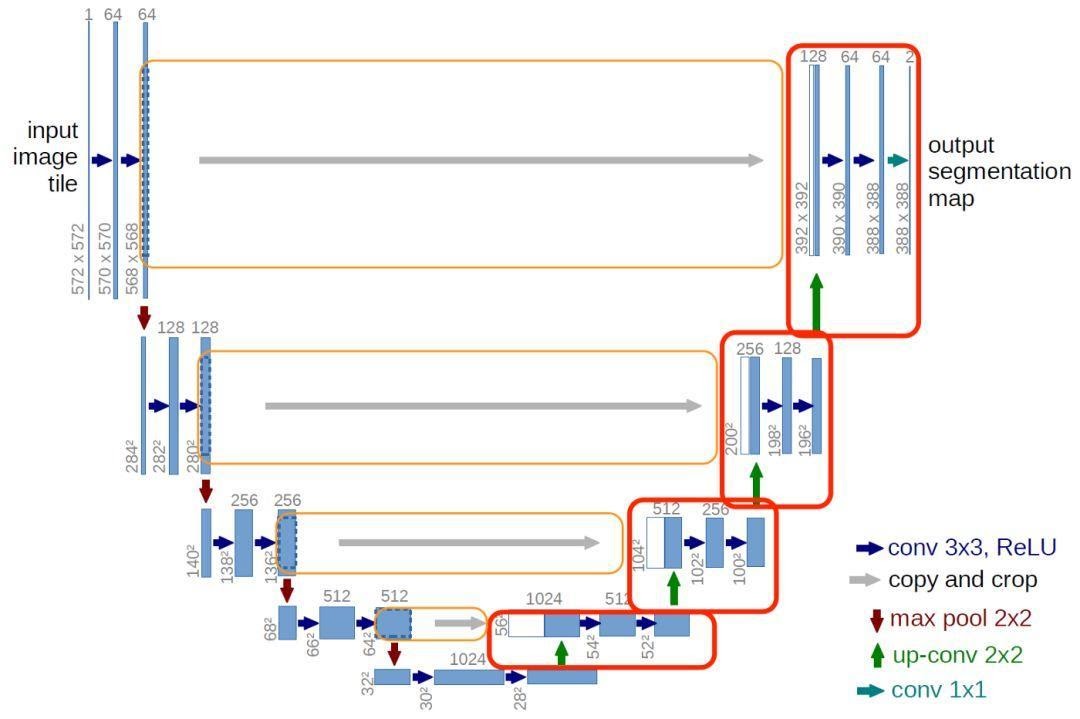 (圖片來源:曾成訓提供)
(圖片來源:曾成訓提供)
U-Net 這個名稱來自於它的網路架構形狀,從 U 字左側開始,輸入圖像後依次進行傳統的 Conv/Pooling下採樣,接著在右側進行 Deconv 反捲積上採樣(其實原本 U-Net 最主要的應用在於圖像的語意分割,但導入 GAN 模型後,下採樣的特徵可作為產生圖片 Deconv 反捲積時的參考特徵,讓產生的圖像與原圖類似)。
#標準的CNN: CNN--> LeakyRelu--> BN。輸入為圖像def conv2d(layer_input, filters, f_size=4):
# 一樣使用步長=2來取代pooling
d = Conv2D(filters, kernel_size=f_size, strides=2, padding='same')(layer_input)
d = LeakyReLU(alpha=0.2)(d)
d = BatchNormalization()(d)
return d
def deconv2d(layer_input, skip_input, filters, f_size=4):
# Upsampling反向卷積:Upsampling CNN LeakyRelu BN
u = UpSampling2D(size=2)(layer_input)
u = Conv2D(filters, kernel_size=f_size, strides=1, padding='same')(u)
u = LeakyReLU(alpha=0.2)(u)
u = BatchNormalization()(u)
# U-Net,將之前的正向捲積特徵skip_input加入
u = Concatenate()()
return u
# 輸入尺寸為(256, 256, 3)
d0 = Input(shape=img_shape)
# 輸入的圖片進行正向卷積, 長寬縮小, 特徵變多
d1 = conv2d(d0, 32)
d2 = conv2d(d1, 64)
d3 = conv2d(d2, 128)
d4 = conv2d(d3, 256)
d5 = conv2d(d4, 512)
d6 = conv2d(d5, 512)
d7 = conv2d(d6, 512)
d8 = conv2d(d7, 512)
# 進行反向卷積產生圖片, 長寬放大, 特徵變少
u0 = deconv2d(d8, d7, 512)
u1 = deconv2d(u0, d6, 512)
u2 = deconv2d(u1, d5, 512)
u3 = deconv2d(u2, d4, 256)
u4 = deconv2d(u3, d3, 128)
u5 = deconv2d(u4, d2, 64)
u6 = deconv2d(u5, d1, 32)
# 最後一層, filter數 = 3代表RGB channels, activation使用tanh
u7 = UpSampling2D(size=2)(u6)
output_img = Conv2D(3, kernel_size=4, strides=1, padding='same', activation='tanh')(u7)
generator = Model(d0, output_img)
generator.summary()
Generator model的summary
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_3 (InputLayer) (None, 256, 256, 3) 0
__________________________________________________________________________________________________
conv2d_8 (Conv2D) (None, 128, 128, 32) 1568 input_3
__________________________________________________________________________________________________
leaky_re_lu_7 (LeakyReLU) (None, 128, 128, 32) 0 conv2d_8
__________________________________________________________________________________________________
batch_normalization_7 (BatchNor (None, 128, 128, 32) 128 leaky_re_lu_7
__________________________________________________________________________________________________
conv2d_9 (Conv2D) (None, 64, 64, 64) 32832 batch_normalization_7
__________________________________________________________________________________________________
leaky_re_lu_8 (LeakyReLU) (None, 64, 64, 64) 0 conv2d_9
__________________________________________________________________________________________________
batch_normalization_8 (BatchNor (None, 64, 64, 64) 256 leaky_re_lu_8
__________________________________________________________________________________________________
conv2d_10 (Conv2D) (None, 32, 32, 128) 131200 batch_normalization_8
__________________________________________________________________________________________________
leaky_re_lu_9 (LeakyReLU) (None, 32, 32, 128) 0 conv2d_10
__________________________________________________________________________________________________
batch_normalization_9 (BatchNor (None, 32, 32, 128) 512 leaky_re_lu_9
__________________________________________________________________________________________________
conv2d_11 (Conv2D) (None, 16, 16, 256) 524544 batch_normalization_9
__________________________________________________________________________________________________
leaky_re_lu_10 (LeakyReLU) (None, 16, 16, 256) 0 conv2d_11
__________________________________________________________________________________________________
batch_normalization_10 (BatchNo (None, 16, 16, 256) 1024 leaky_re_lu_10
__________________________________________________________________________________________________
conv2d_12 (Conv2D) (None, 8, 8, 512) 2097664 batch_normalization_10
__________________________________________________________________________________________________
leaky_re_lu_11 (LeakyReLU) (None, 8, 8, 512) 0 conv2d_12
__________________________________________________________________________________________________
batch_normalization_11 (BatchNo (None, 8, 8, 512) 2048 leaky_re_lu_11
__________________________________________________________________________________________________
conv2d_13 (Conv2D) (None, 4, 4, 512) 4194816 batch_normalization_11
__________________________________________________________________________________________________
leaky_re_lu_12 (LeakyReLU) (None, 4, 4, 512) 0 conv2d_13
__________________________________________________________________________________________________
batch_normalization_12 (BatchNo (None, 4, 4, 512) 2048 leaky_re_lu_12
__________________________________________________________________________________________________
conv2d_14 (Conv2D) (None, 2, 2, 512) 4194816 batch_normalization_12
__________________________________________________________________________________________________
leaky_re_lu_13 (LeakyReLU) (None, 2, 2, 512) 0 conv2d_14
__________________________________________________________________________________________________
batch_normalization_13 (BatchNo (None, 2, 2, 512) 2048 leaky_re_lu_13
__________________________________________________________________________________________________
conv2d_15 (Conv2D) (None, 1, 1, 512) 4194816 batch_normalization_13
__________________________________________________________________________________________________
leaky_re_lu_14 (LeakyReLU) (None, 1, 1, 512) 0 conv2d_15
__________________________________________________________________________________________________
batch_normalization_14 (BatchNo (None, 1, 1, 512) 2048 leaky_re_lu_14
__________________________________________________________________________________________________
up_sampling2d_1 (UpSampling2D) (None, 2, 2, 512) 0 batch_normalization_14
__________________________________________________________________________________________________
conv2d_16 (Conv2D) (None, 2, 2, 512) 4194816 up_sampling2d_1
__________________________________________________________________________________________________
leaky_re_lu_15 (LeakyReLU) (None, 2, 2, 512) 0 conv2d_16
__________________________________________________________________________________________________
batch_normalization_15 (BatchNo (None, 2, 2, 512) 2048 leaky_re_lu_15
__________________________________________________________________________________________________
concatenate_2 (Concatenate) (None, 2, 2, 1024) 0 batch_normalization_15
batch_normalization_13
__________________________________________________________________________________________________
up_sampling2d_2 (UpSampling2D) (None, 4, 4, 1024) 0 concatenate_2
__________________________________________________________________________________________________
conv2d_17 (Conv2D) (None, 4, 4, 512) 8389120 up_sampling2d_2
__________________________________________________________________________________________________
leaky_re_lu_16 (LeakyReLU) (None, 4, 4, 512) 0 conv2d_17
__________________________________________________________________________________________________
batch_normalization_16 (BatchNo (None, 4, 4, 512) 2048 leaky_re_lu_16
__________________________________________________________________________________________________
concatenate_3 (Concatenate) (None, 4, 4, 1024) 0 batch_normalization_16
batch_normalization_12
__________________________________________________________________________________________________
up_sampling2d_3 (UpSampling2D) (None, 8, 8, 1024) 0 concatenate_3
__________________________________________________________________________________________________
conv2d_18 (Conv2D) (None, 8, 8, 512) 8389120 up_sampling2d_3
__________________________________________________________________________________________________
leaky_re_lu_17 (LeakyReLU) (None, 8, 8, 512) 0 conv2d_18
__________________________________________________________________________________________________
batch_normalization_17 (BatchNo (None, 8, 8, 512) 2048 leaky_re_lu_17
__________________________________________________________________________________________________
concatenate_4 (Concatenate) (None, 8, 8, 1024) 0 batch_normalization_17
batch_normalization_11
__________________________________________________________________________________________________
up_sampling2d_4 (UpSampling2D) (None, 16, 16, 1024) 0 concatenate_4
__________________________________________________________________________________________________
conv2d_19 (Conv2D) (None, 16, 16, 256) 4194560 up_sampling2d_4
__________________________________________________________________________________________________
leaky_re_lu_18 (LeakyReLU) (None, 16, 16, 256) 0 conv2d_19
__________________________________________________________________________________________________
batch_normalization_18 (BatchNo (None, 16, 16, 256) 1024 leaky_re_lu_18
__________________________________________________________________________________________________
concatenate_5 (Concatenate) (None, 16, 16, 512) 0 batch_normalization_18
batch_normalization_10
__________________________________________________________________________________________________
up_sampling2d_5 (UpSampling2D) (None, 32, 32, 512) 0 concatenate_5
__________________________________________________________________________________________________
conv2d_20 (Conv2D) (None, 32, 32, 128) 1048704 up_sampling2d_5
__________________________________________________________________________________________________
leaky_re_lu_19 (LeakyReLU) (None, 32, 32, 128) 0 conv2d_20
__________________________________________________________________________________________________
batch_normalization_19 (BatchNo (None, 32, 32, 128) 512 leaky_re_lu_19
__________________________________________________________________________________________________
concatenate_6 (Concatenate) (None, 32, 32, 256) 0 batch_normalization_19
batch_normalization_9
__________________________________________________________________________________________________
up_sampling2d_6 (UpSampling2D) (None, 64, 64, 256) 0 concatenate_6
__________________________________________________________________________________________________
conv2d_21 (Conv2D) (None, 64, 64, 64) 262208 up_sampling2d_6
__________________________________________________________________________________________________
leaky_re_lu_20 (LeakyReLU) (None, 64, 64, 64) 0 conv2d_21
__________________________________________________________________________________________________
batch_normalization_20 (BatchNo (None, 64, 64, 64) 256 leaky_re_lu_20
__________________________________________________________________________________________________
concatenate_7 (Concatenate) (None, 64, 64, 128) 0 batch_normalization_20
batch_normalization_8
__________________________________________________________________________________________________
up_sampling2d_7 (UpSampling2D) (None, 128, 128, 128 0 concatenate_7
__________________________________________________________________________________________________
conv2d_22 (Conv2D) (None, 128, 128, 32) 65568 up_sampling2d_7
__________________________________________________________________________________________________
leaky_re_lu_21 (LeakyReLU) (None, 128, 128, 32) 0 conv2d_22
__________________________________________________________________________________________________
batch_normalization_21 (BatchNo (None, 128, 128, 32) 128 leaky_re_lu_21
__________________________________________________________________________________________________
concatenate_8 (Concatenate) (None, 128, 128, 64) 0 batch_normalization_21
batch_normalization_7
__________________________________________________________________________________________________
up_sampling2d_8 (UpSampling2D) (None, 256, 256, 64) 0 concatenate_8
__________________________________________________________________________________________________
conv2d_23 (Conv2D) (None, 256, 256, 3) 3075 up_sampling2d_8
==================================================================================================
Total params: 41,937,603
Trainable params: 41,928,515
Non-trainable params: 9,088
Discriminator
Discriminator model 與之前 DCGAN 的差異在於 Input 需輸入兩張圖片,而輸出不是 True/False 的二元論,而是 4×4 向量特徵值,這是因為 Pix2Pix 採用了 PatchGan 的方法,將圖片切分成固定尺寸(本文為 4×4)後才進行比較差異。
from keras.optimizers import Adamdef d_layer(layer_input, filters, f_size=4):
# 卷積--> Leaky Relu--> BN
# 一樣使用步長=2取代pooling
d = Conv2D(filters, kernel_size=f_size, strides=2, padding='same')(layer_input)
d = LeakyReLU(alpha=0.2)(d)
d = BatchNormalization()(d)
return d
# Discriminator的input是兩張圖片:原圖+對應圖
# 原圖+真的對應圖 -> 1(真)
# 原圖+假的對應圖 -> 0(假)
img_A = Input(shape=img_shape)
img_B = Input(shape=img_shape)
# 兩張圖合併
combined_imgs = Concatenate(axis=-1)()
d1 = d_layer(combined_imgs, 64)
d2 = d_layer(d1, 128)
d3 = d_layer(d2, 256)
d4 = d_layer(d3, 512)
validity = Conv2D(1, kernel_size=4, strides=1, padding='same')(d4)
discriminator = Model(, validity)
optimizer = Adam(0.0002, 0.5)
discriminator.compile(loss='mse', optimizer=optimizer)
discriminator.summary()
Discriminator model的summary
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, 256, 256, 3) 0
__________________________________________________________________________________________________
input_2 (InputLayer) (None, 256, 256, 3) 0
__________________________________________________________________________________________________
concatenate_1 (Concatenate) (None, 256, 256, 6) 0 input_1
input_2
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, 128, 128, 32) 3104 concatenate_1
__________________________________________________________________________________________________
leaky_re_lu_1 (LeakyReLU) (None, 128, 128, 32) 0 conv2d_1
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, 128, 128, 32) 128 leaky_re_lu_1
__________________________________________________________________________________________________
conv2d_2 (Conv2D) (None, 64, 64, 64) 32832 batch_normalization_1
__________________________________________________________________________________________________
leaky_re_lu_2 (LeakyReLU) (None, 64, 64, 64) 0 conv2d_2
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, 64, 64, 64) 256 leaky_re_lu_2
__________________________________________________________________________________________________
conv2d_3 (Conv2D) (None, 32, 32, 128) 131200 batch_normalization_2
__________________________________________________________________________________________________
leaky_re_lu_3 (LeakyReLU) (None, 32, 32, 128) 0 conv2d_3
__________________________________________________________________________________________________
batch_normalization_3 (BatchNor (None, 32, 32, 128) 512 leaky_re_lu_3
__________________________________________________________________________________________________
conv2d_4 (Conv2D) (None, 16, 16, 256) 524544 batch_normalization_3
__________________________________________________________________________________________________
leaky_re_lu_4 (LeakyReLU) (None, 16, 16, 256) 0 conv2d_4
__________________________________________________________________________________________________
batch_normalization_4 (BatchNor (None, 16, 16, 256) 1024 leaky_re_lu_4
__________________________________________________________________________________________________
conv2d_5 (Conv2D) (None, 8, 8, 512) 2097664 batch_normalization_4
__________________________________________________________________________________________________
leaky_re_lu_5 (LeakyReLU) (None, 8, 8, 512) 0 conv2d_5
__________________________________________________________________________________________________
batch_normalization_5 (BatchNor (None, 8, 8, 512) 2048 leaky_re_lu_5
__________________________________________________________________________________________________
conv2d_6 (Conv2D) (None, 4, 4, 512) 4194816 batch_normalization_5
__________________________________________________________________________________________________
leaky_re_lu_6 (LeakyReLU) (None, 4, 4, 512) 0 conv2d_6
__________________________________________________________________________________________________
batch_normalization_6 (BatchNor (None, 4, 4, 512) 2048 leaky_re_lu_6
__________________________________________________________________________________________________
conv2d_7 (Conv2D) (None, 4, 4, 1) 8193 batch_normalization_6
==================================================================================================
Total params: 6,998,369
Trainable params: 6,995,361
Non-trainable params: 3,008
合併Model及Training
傳統的 GAN 讀入整張圖片後能判斷其真偽,缺點是無法控制一些圖形的細節,因此 Pix2Pix 在進行training 時,導入了 PatchGan 方法,先將圖片切解為一個個小方格(如 4×4)後,再針對這些小方格進行評分判斷,而非針對整張圖片。
# 合併Generator及Discriminatorimg_A = Input(shape=img_shape)
img_B = Input(shape=img_shape)
# 由Generator由img_A產生假的對應圖片fake_A
fake_A = generator(img_B)
# Discriminator不在GAN model中訓練
discriminator.trainable = False
# 將 一起送進去Discriminator判斷真假
valid = discriminator()
# 整個GAN模型的input是
# output是
combined = Model(inputs=, outputs=)
#Discriminator輸出的不再是True/False的機率,而是4,4的特徵值,故改用MSE來計算距離差異作為loss,一般來說,選擇 MAE(差的絕對值)或MSE(差的平方)皆可。
combined.compile(loss=,
loss_weights=,
optimizer=optimizer)
combined.summary()
__________________________________________________________________________________________________
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_5 (InputLayer) (None, 256, 256, 3) 0
__________________________________________________________________________________________________
model_2 (Model) (None, 256, 256, 3) 41937603 input_5
__________________________________________________________________________________________________
model_1 (Model) (None, 4, 4, 1) 6998369 model_2
input_5
==================================================================================================
Total params: 48,935,972
Trainable params: 41,928,515
Non-trainable params: 7,007,457
Training
#Discriminator model輸出大小為(16,16,1),此亦為PatchGAN的大小。patch = int(256 / 2**4)
disc_patch = (patch, patch, 1)
disc_patch
batch_size = 4
#Label為1,為正確圖片的標記。
valid = np.ones((batch_size,) + disc_patch)
#Label為0,為虛擬圖片的標記。
fake = np.zeros((batch_size,) + disc_patch)
train_count = 5000
for train in range(0, train_count):
# 隨機取train_count張圖片
rid = np.random.randint(0, len(imglist), batch_size)
# 圖片左右分別代表預測前, 以及實際的原圖,分別切出來為left及right
imgs_A =
imgs_B =
for i in rid:
oriimage = Image.open(imglist)
right = oriimage.crop((0, 0, int(oriimage.size / 2), oriimage.size))
right = right.resize((256, 256))
right = np.array(right)
left = oriimage.crop((int(oriimage.size / 2), 0,
oriimage.size, oriimage.size))
left = left.resize((256, 256))
left = np.array(left)
# 標準化圖片(-1~1之間)
imgs_A.append((left - 127.5)/127.5)
imgs_B.append((right - 127.5)/127.5)
# 記得所有東西轉換成np array
imgs_A = np.array(imgs_A)
imgs_B = np.array(imgs_B)
# 由Generator依據圖產生預測的圖片(對Discriminator來說,為假的相片)
fake_A = generator.predict(imgs_B)
# Step1. 訓練Discriminator, train_on_batch(x, y)
d_loss_real = discriminator.train_on_batch(, valid)
d_loss_fake = discriminator.train_on_batch(, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# Step2. 訓練Generator, train_on_batch(x, y)
g_loss = combined.train_on_batch(, )
if (train + 1) % 100 == 0:
dash = "-" * 15
print(dash, "Train", train + 1, dash)
print("Discriminator loss:", d_loss)
print("Generator loss:", g_loss)
Dataset準備
由於能用於 PIX2PIX 訓練的成對圖片樣本較少,且很難找到適合又大量的現成 dataset 供訓練,所以我想說就自己來產生吧!
我使用了公司目前刷臉打卡所累積的大量相片,寫個程式逐層讀取資料夾內的每張相片並自動裁減臉部區域,再打上馬賽克,最後拼成一張張成對的相片如下(為保護圖片當事人,僅放上加上馬賽克的照片)。
只需不到短短一分鐘...
輸入您的信箱與ID註冊即可享有一切福利!
會員福利
免費電子報
會員搶先看
主題訂閱
好文收藏

