
作者/圖片來源:CAVEDU 教育團隊

最近筆者拿到VIA Pixetto視覺感測器(以下通稱Pixetto),這個功能完整、1080P FULL HD 的AI鏡頭,除了本身可以辨識顏色、人臉、形狀及手寫辨識…..等等的視覺辨識,還可以搭配 Tensorflow Lite 框架來做更進一步的應用,如果透過 Grove 接頭或正確接線的話,當然也可以和Arduino 這種開發板來溝通。不管是第一次踏入機器學習的初學者,或想要做進階的視覺辨識專案的創作者,我認為Pixetto都顧及到了,可謂是面面俱到!
硬體正反面照片(規格表請按我)

圖片引用自 VIA 原廠規格表
既然Pixetto可以匯入Tensorflow Lite,筆者就想到我們最熟悉的好工具 — Google Teachable Machine 網頁,讓初學者無須編寫任何程式碼就能訓練出視覺辨識、聲音辨識與人體姿勢辨識的神經網路模型,並可以了解機器學習的架構的原理為何,也可以使初學者快速完成自己的專案喔!
筆者在實際把玩 Pixetto 的過程中,發現它可以匯入由 Google Teachable Machine 網頁所匯出的 Tensorflow lite (.tflite) 神經網路模型檔案,於是就寫了這篇教學文囉!以下操作分成三大部分,「安裝Pixetto軟體套件」、「Teachable machine網頁訓練模型」與「將Teachable machine網站的tflite檔匯入Pixetto視覺感測器工具」中。
安裝Pixetto軟體套件
在使用 Pixetto 這款 AI 鏡頭之前,需要有些前置作業,請按照以下步驟操作:
步驟1. 下載Pixetto軟體套件
請由 VIA 原廠下載相關軟體,點選本連結下載。
步驟2. 安裝Pixetto軟體套件
請依照預設設定安裝軟體完成,途中可能需要重新啟動電腦。
步驟3. 開啟 Pixetto Studio 介面
安裝完畢後,在桌面上會出現 Pixetto Startup 的 icon,點兩下滑鼠左鍵就會出現 Pixetto Studio 介面,此時先進行下一步硬體操作。

步驟4.將Pixetto透過USB2.0傳輸線連接至電腦

圖片引用自 VIA 原廠教學
步驟5. 初始化完成
Pixetto的綠色、藍色和紅色LED亮起,代表視覺感測器已經初始化完畢,可 以使用了。別忘了把將鏡頭上蓋打開。

圖片引用自 VIA 原廠教學
步驟6. Pixetto 視覺感測器工具介面
回到步驟3,在Pixetto Studio介面中,按下Pixetto Utility,就會出現Pixetto 視覺感測器工具的介面,若有看見鏡頭畫面,便設定完成。請注意在此要先關閉程式,因為後續在 Google Teachable Machine 也會去抓 Pixetto 鏡頭畫面。需要先情關閉否則會看不到畫面。
以上步驟可以在Pixetto 網站找到詳細說明,按此連結下載 。
使用 Google Teachable Machine 網頁訓練模型
雖然在Pixetto軟體套件已經可以自行辨識顏色、形狀、人臉….等等的功能,但如果要自定義某種特定類別的標籤已符合自己專案的話,還是需要透過撰寫Python程式,來匯入Pixetto軟體套件中,因此Teachable machine就可以針對初學者不需寫程式,也可以操作囉。
由於有關Teachable machine的細節操作,其他部落格已有很多的相關說明,有興趣的讀者請參考我們先前寫好的相關文章。本篇只是約略說明訓練模型的操作過程,以下分成幾個步驟講解:
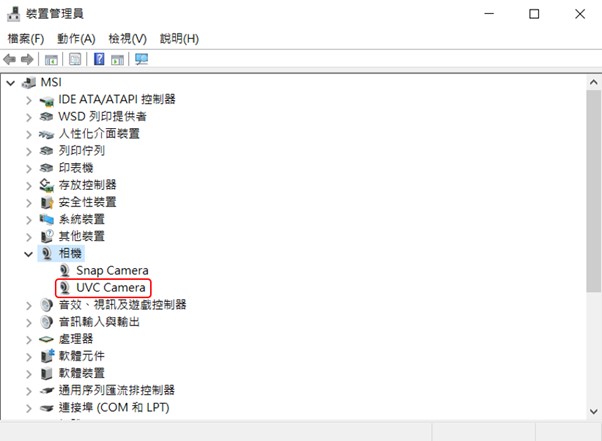
步驟1.找到Pixetto的鏡頭名稱
使用 USB 傳輸線把 Pixetto 接上電腦之後,就可以在 Windows 電腦的裝置管理員中🡪相機,找到UVC Camera,這就是Pixetto的鏡頭名稱。
步驟2. 在Teachable machine網頁中,得到Pixetto鏡頭的畫面
在收集圖片資料的過程中,除了可以上網搜尋圖片之外,最快速的方法就是使用鏡頭拍照。在Google Teachable Machine網站中新增一個影像分類專案,點選Webcam,在下拉式選單中點選UVC Camera,就可以看到 Pixetto 鏡頭畫面。
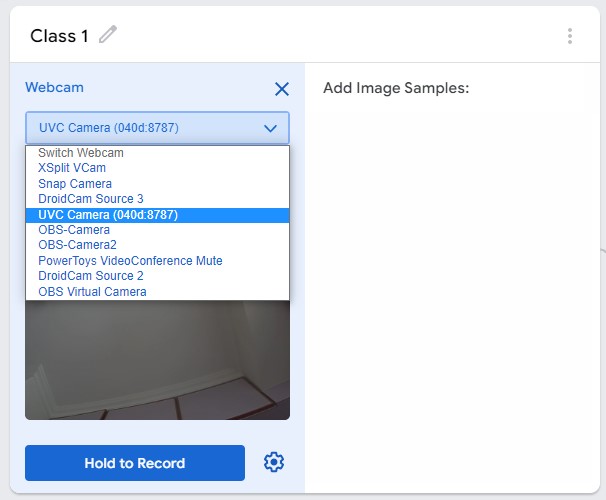 (注意:需先將Pixetto視覺感測器工具的介面關閉,不然會占用資源而無法在Teachable machine網頁中使用)
(注意:需先將Pixetto視覺感測器工具的介面關閉,不然會占用資源而無法在Teachable machine網頁中使用)
步驟3. 收集圖片資料
本文收集了四種類別,分別是Keychain、LinkIt7697、Raspberry Pi 與 Other,以下展示這四個類別的步驟。
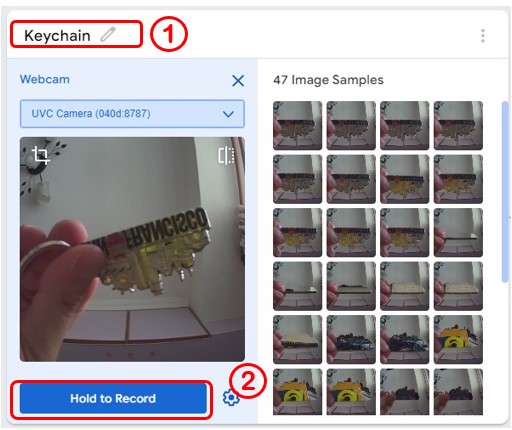
3-1 收集第一個類別Keychain圖片
將標籤改成Keychain後,按下Hold to Record即可拍照收集,以不超過50張為主,其它三個類別的張數也是一樣。
 3-2 收集第二個類別LinkIt7697圖片
3-2 收集第二個類別LinkIt7697圖片
重複步驟3-1,或選用你想要辨識的物體。
3-3收集第三個類別Raspberry Pi圖片
重複步驟3-1,或選用你想要辨識的物體。
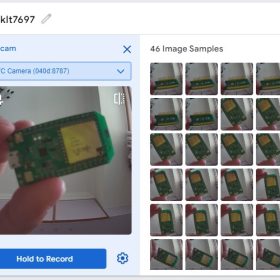
3-4收集第四個類別Other圖片
重複步驟3-1。第四個類別是屬於反指標,也就是辨識Keychain、LinkIt7697、Raspberry Pi類別以外的情形。
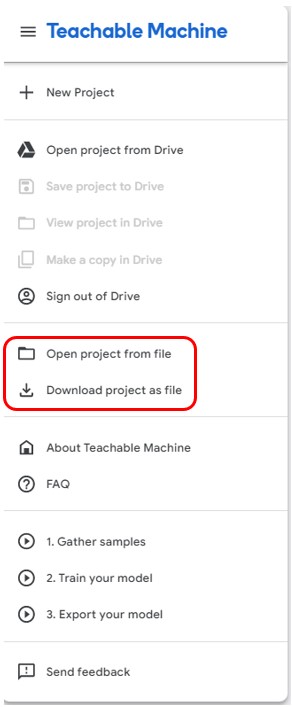
步驟4. 下載專案tm檔
Google Teachable Machine 的專案檔,副檔名是 tm。當讀者四種類別收集完資料後,若日後想再新增類別,可不必從頭再做一次,只需要按下Download project as file,即可將目前收集資料的進度保存至電腦;日後使用相同帳號,點選Open project from file 就能從上次進度繼續。
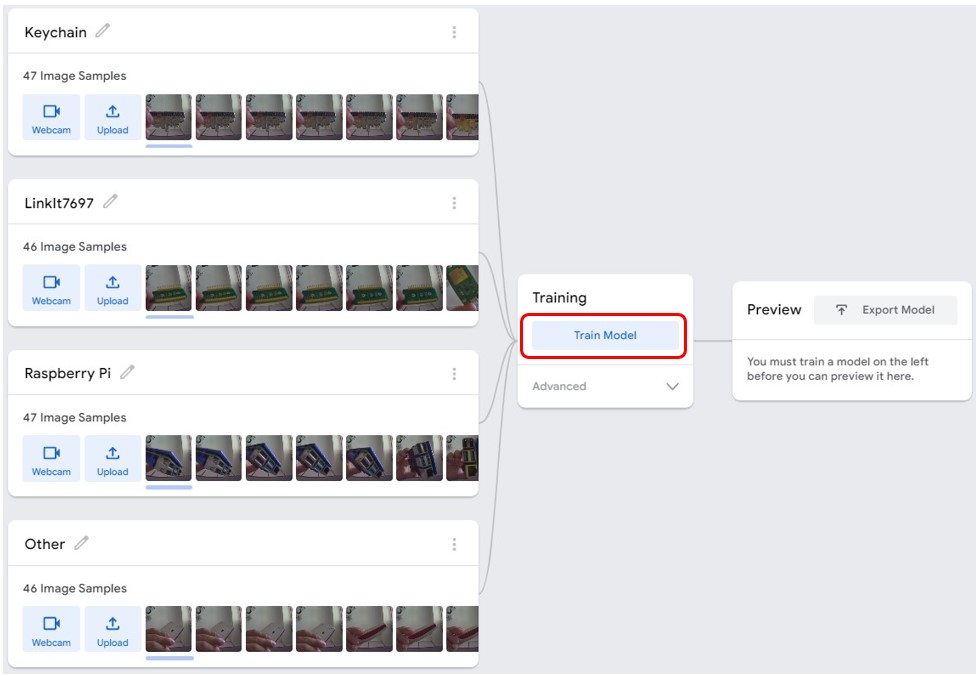
 步驟5. 訓練模型
步驟5. 訓練模型
確定以上四個類別圖片都收集完畢後,接著要開始訓練模型,按下 Train Model,網頁就會開始訓練模型。
步驟6. 在網站上推論
模型訓練完畢,可以在網頁直接進行推論,測試視覺辨識是否準確,若測試結果覺得不錯的話,可直接下載模型檔。
 步驟7. 關閉鏡頭
步驟7. 關閉鏡頭
這是非常重要的步驟,原因和上述一樣,如果沒有在 Teachable Machine 關閉鏡頭的話,等等在 Pixetto 視覺感測器工具中正確開啟攝影機畫面。請把 Input 處切到 OFF 即可關閉Pixetto鏡頭畫面。
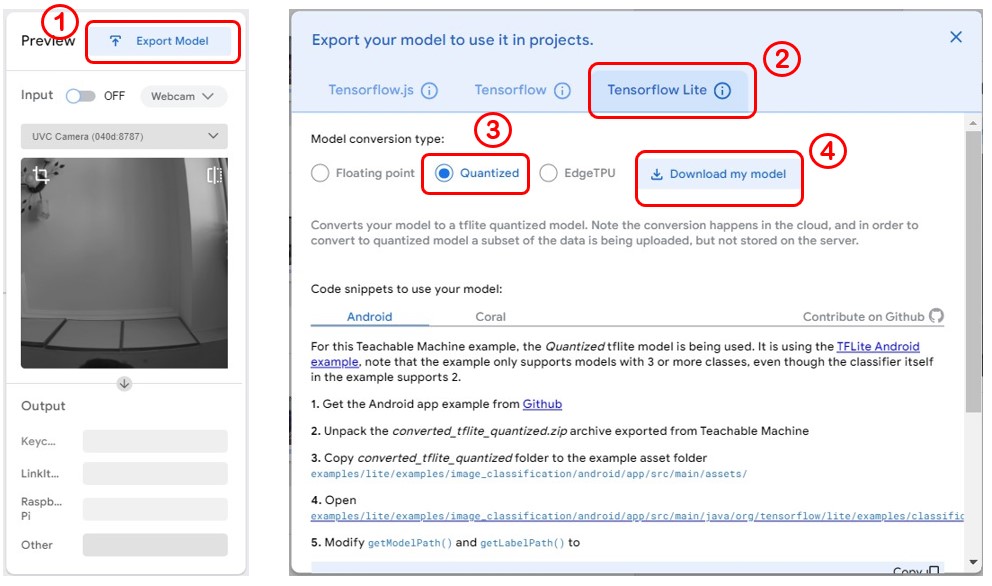
 步驟8. 匯出 tensroflow lite 模型檔
步驟8. 匯出 tensroflow lite 模型檔
滿意訓練結果嗎?按下右上角的 Export Model。於跳出的視窗中依序點選 Tensorflow Lite🡪Quantized🡪Download
my model,過幾分鐘後就會有模型的壓縮檔匯出提示可供下載。
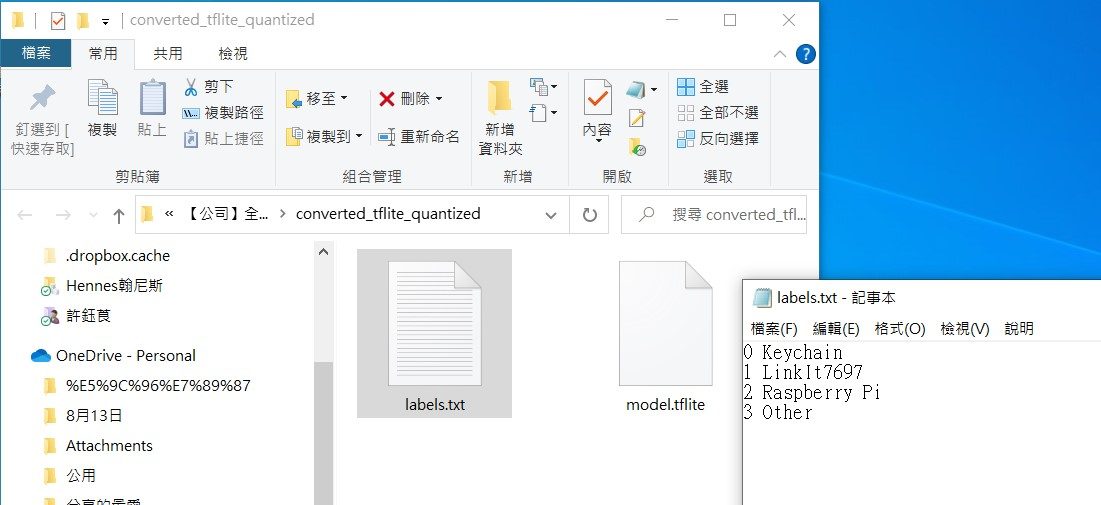
步驟9. 解壓縮模型檔
將下載下來的模型檔解壓縮,開啟資料夾後,可以看到模型檔 model.tflite 和標籤檔 label.txt。請開啟標籤檔,來看看當初在Teachable machine網頁收集資料的順序,這個步驟後續會用到。
將Teachable machine網站的tflite檔匯入Pixetto視覺感測器工具中
步驟1. 匯入tflite模型檔
接續第一階段安裝Pixetto軟體套件的步驟6,開啟Pixetto視覺感測器工具的介面後,點選模型路徑框🡪找到model.tflite模型檔🡪按確認,即可匯入。

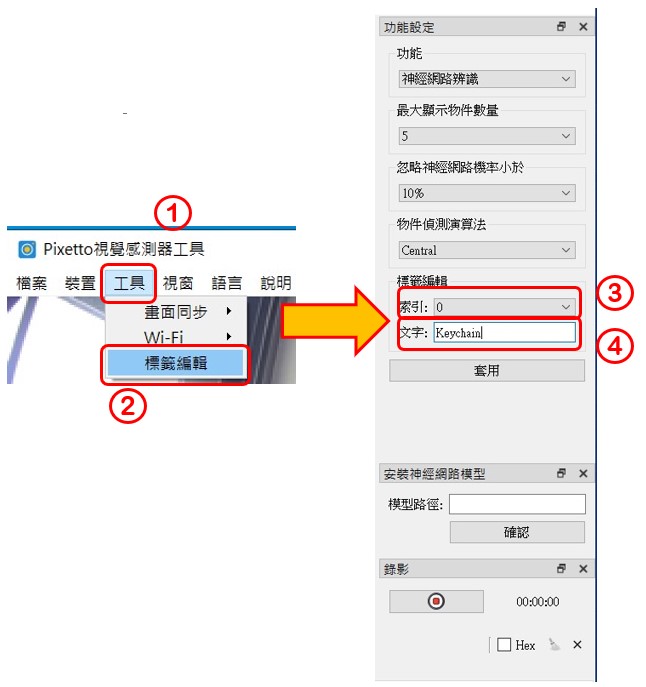
步驟2. 標籤編輯
在工具🡪標籤編輯選擇之後,右邊欄位會顯示索引和文字,依序對應索引及文字,例如索引 0 輸入文字 Keychain、索引1輸入文字LinkIt7697…以此類推。若忘記對應名稱,請回顧上述第二階段在Teachable machine網頁訓練模型的步驟9。
 成果展示
成果展示
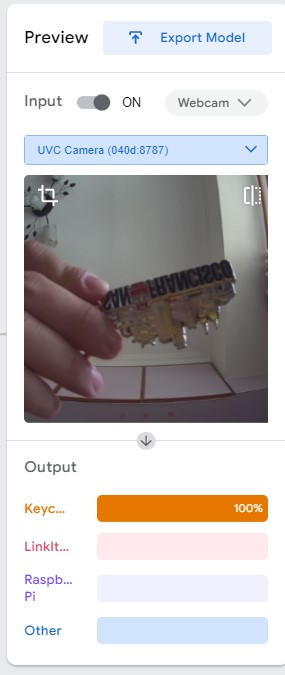
一切設定完成後,接下來就來看執行成果吧,首先是第一類別Keychain的辨識結果。
 綠框是感興趣區域 (ROI,Region of Interest),也就是鏡頭會辨識綠框區域內的物件。不過在辨識Keychain時需要靠近鏡頭近一點辨識才會準確,辨識率可以高達85%以上。值得一提的是,Keychain的另一面是光滑金屬面,容易反光而辨識錯誤。
綠框是感興趣區域 (ROI,Region of Interest),也就是鏡頭會辨識綠框區域內的物件。不過在辨識Keychain時需要靠近鏡頭近一點辨識才會準確,辨識率可以高達85%以上。值得一提的是,Keychain的另一面是光滑金屬面,容易反光而辨識錯誤。
其他類別的辨識結果如下說明:
LinkIt7697也是需要靠近鏡頭辨識才會準確,辨識率可以高達95%以上。
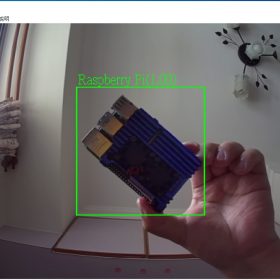
Raspberry Pi的辨識率是最高的,因為體積大,所以很容易辨識率100%。
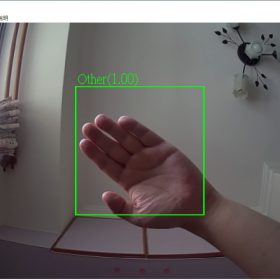
Other的辨識率也是不錯,也有達85%以上。

本文實作就到此告一段落,歡迎各位讀者可以在下方的留言區,聊聊你們做了甚麼專題吧,我們下篇部落格見!
相關文章

- 【CAVEDU講堂】NVIDIA Jetson AI Lab 大解密!範例與系統需求介紹 - 2024/10/08
- 【CAVEDU講堂】Google DeepMind使用大語言模型LLM提示詞來產生你的機器人操作程式碼 - 2024/07/30
- 【CAVEDU講堂】《Arduino首次接觸就上手》新手村教學:LED燈閃爍 - 2024/04/18
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!

